Fine-tuning the DeepSeek R1 Model to Enable Precision Q&A in Healthcare: Unlocking the Potential of Open Source AI

DeepSeek Launched a series of advanced inference models to challenge OpenAI's industry position, andCompletely free, no restrictions on use, benefiting all users.
In this article, we describe how to fine-tune the DeepSeek-R1-Distill-Llama-8B model using Hugging Face's Medical Mind Chain dataset. This lite version of the DeepSeek-R1 model, obtained by fine-tuning the Llama 3 8B model on the data generated by DeepSeek-R1, exhibits superior inference similar to the original model.

DeepSeek R1 Decryption
DeepSeek-R1 and DeepSeek-R1-Zero outperform OpenAI's o1 model in math, programming, and logical reasoning tasks.It is worth noting that both R1 and R1-Zero are open source modelsThe
DeepSeek-R1-Zero
DeepSeek-R1-Zero is the first open-source model trained exclusively using large-scale Reinforcement Learning (RL), as opposed to traditional models that use Supervised Fine-Tuning (SFT) as an initial step. This innovative approach empowers models to independently explore CoT (Chain-of-Thought) reasoning, enabling them to solve complex problems and iteratively optimize the output. However, this approach also poses some challenges, such as possible repetition of reasoning steps, reduced readability, and inconsistent language styles, which affects the clarity and usefulness of the model.
DeepSeek-R1
The release of DeepSeek-R1 aims to overcome the shortcomings of DeepSeek-R1-Zero. By introducing cold-start data prior to reinforcement learning, DeepSeek-R1 lays a stronger foundation for both inference and non-inference tasks. This multi-stage training strategy enables DeepSeek-R1 to achieve a leadership level against OpenAI-o1 in math, programming, and inference benchmarks, and significantly improves the readability and coherence of the output.
DeepSeek Distillation Model
DeepSeek has also introduced a family of distillation models. These models are smaller and more efficient while maintaining excellent inference performance. Although the parameter sizes range from 1.5B to 70B, all of these models retain strong inference capabilities. Among them, DeepSeek-R1-Distill-Qwen-32B outperforms the OpenAI-o1-mini model in several benchmarks. The smaller scale models inherit the inference patterns of the larger models, fully demonstrating the effectiveness of the distillation technique.
-1")
DeepSeek R1 fine-tuning in action
1. Environmental configuration
In this model fine-tuning exercise, Kaggle was chosen as the cloud IDE because of the free GPU resources provided by Kaggle. Two T4 GPUs were initially chosen, but only one was used. If users wish to perform model fine-tuning on a local computer, they need to have at leastA RTX 3090 graphics card with 16GB of video memory.The
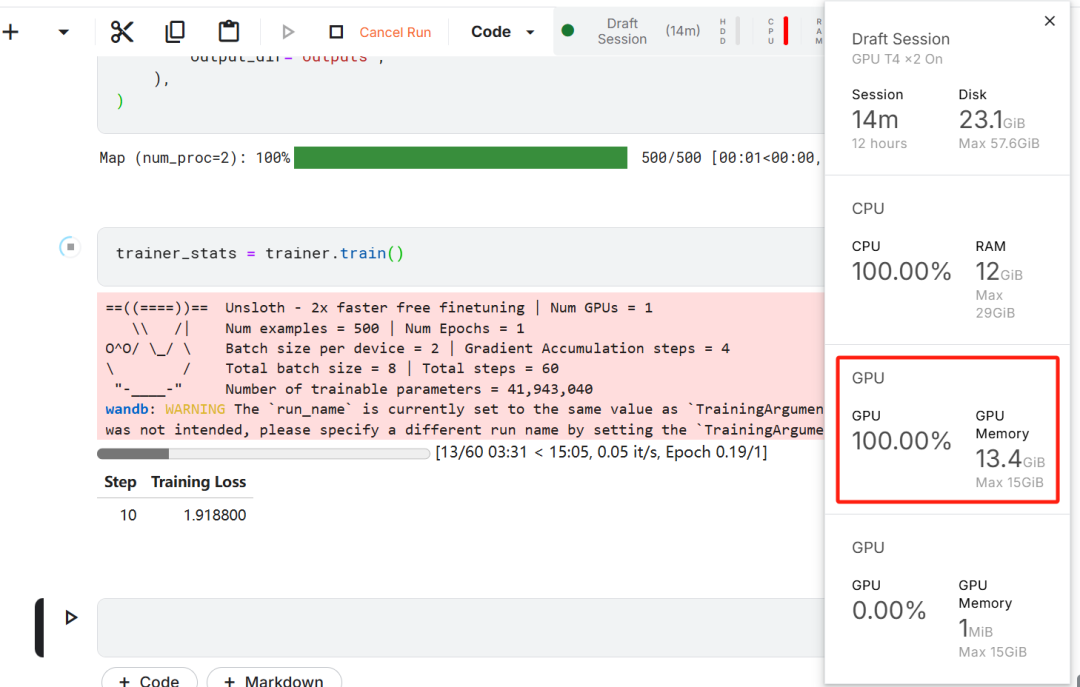
First, start a new Kaggle notebook with the user's Hugging Face token cap (a poem) Weights & Biases token is added as a key.
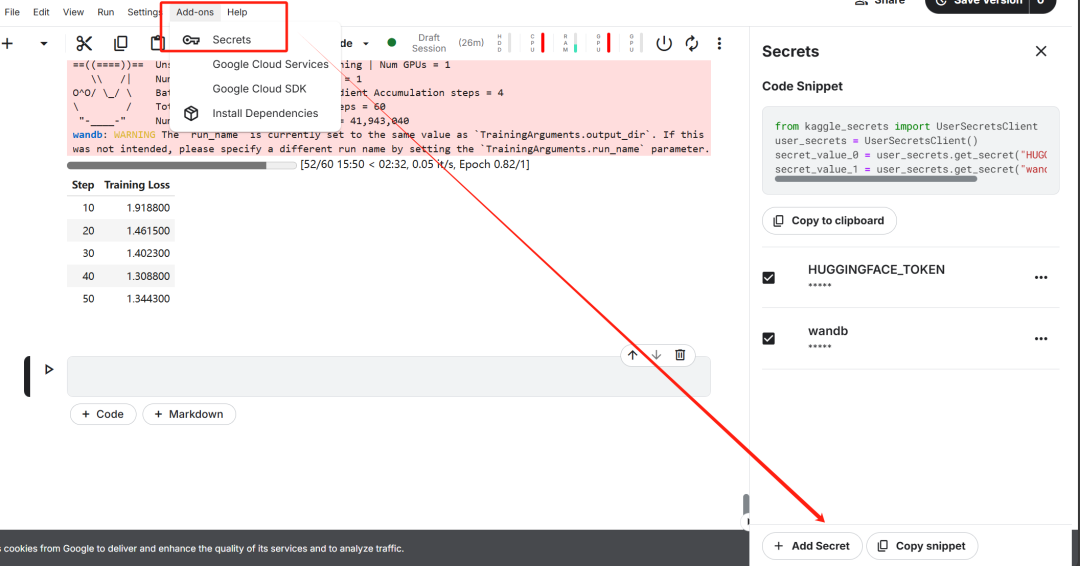
After completing the key setup, install the unsloth Python package. Unsloth is an open source framework designed to double the speed of fine-tuning large language models (LLMs) and significantly improve memory efficiency.
%%capture
!pip install unsloth
!pip install --force-reinstall --no-cache-dir --no-deps git+https://github.com/unslothai/unsloth.git
Next, log in to the Hugging Face CLI. this step is critical for subsequent downloads of the dataset and uploading the fine-tuned model.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)
Then, log in to Weights & Biases (wandb) and create a new project in order to keep track of the experimental process and fine-tune the progress.
import wandb
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune-DeepSeek-R1-Distill-Llama-8B on Medical COT Dataset',
job_type="training",
anonymous="allow"
)
2. Model and tokenizer loading
In the practice of this paper, the Unsloth version of the DeepSeek-R1-Distill-Llama-8B model was loaded.
https://huggingface.co/unsloth/DeepSeek-R1-Distill-Llama-8B
In order to optimize memory usage and improve performance, the model was chosen to be loaded in 4-bit quantization.
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="unsloth/DeepSeek-R1-Distill-Llama-8B",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token=hf_token,
)
3. Pre-fine-tuning model reasoning capability primer
In order to construct a prompt template for the model, a system prompt was defined with placeholders for question and answer generation. This prompt is intended to guide the model through a step-by-step process of thinking and ultimately generating logically rigorous and accurate answers.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>{}"""
In this example, a message is sent to the prompt_style provided a medical problem and transformed it into tokens, and subsequently these tokens passed to the model to generate the answer.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model)
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
The core of the above medical question is:
A 61-year-old woman with a long history of involuntary urine leakage during activities such as coughing or sneezing, but no nocturnal leakage. She underwent a gynecologic examination and Q-tip testing. Based on these findings, what information would cystometry most likely reveal about her residual urine volume and status of contraction of the forced urethra?
Even without fine-tuning, the model successfully generates chains of thoughts and performs rigorous reasoning before giving the final answer, and the entire reasoning process is encapsulated in the <think></think> Tagged within.
So why is fine-tuning still needed? Although the model shows a detailed reasoning process, its representation is slightly lengthy and not concise enough. Furthermore, the final answers are presented as bulleted lists, which deviates from the structure and style of the dataset expected to be fine-tuned.
4. Loading and pre-processing of data sets
The prompt template was fine-tuned to accommodate the processing needs of the dataset by adding a third placeholder for the Complex Chain-of-Thought column in the prompt template.
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning.
Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
A Python function was written to create a "text" column in the dataset. The content of the column consists of a training prompt template with placeholders populated with questions, thought chains, and answers, respectively.
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
The first 500 samples from the FreedomIntelligence/medical-o1-reasoning-SFT dataset were loaded from the Hugging Face Hub.
https://huggingface.co/datasets/FreedomIntelligence/medical-o1-reasoning-SFT?row=46
Subsequently, using the formatting_prompts_func function maps the "text" column of the dataset.
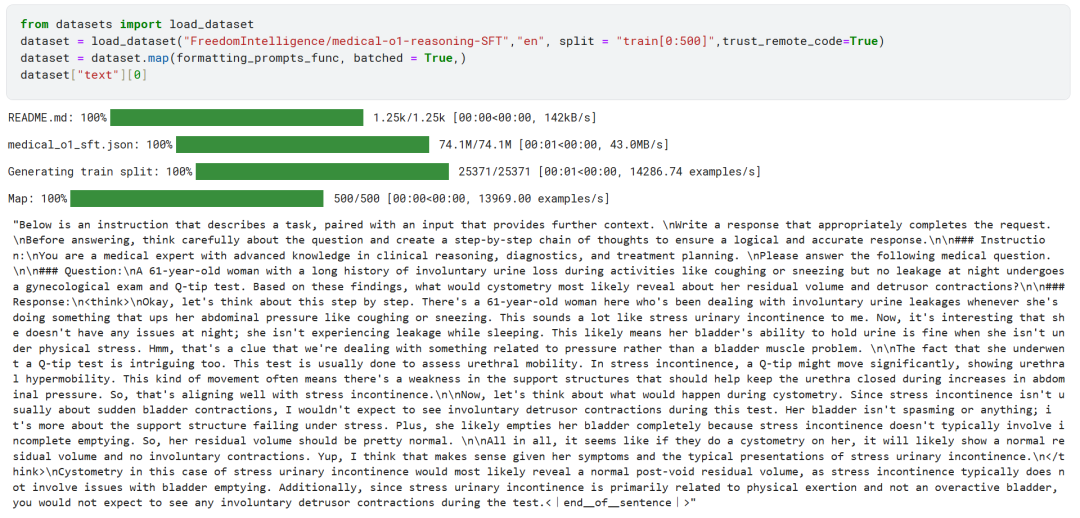
As you can see above, the "text" column has successfully integrated system hints, instructions, thought chains, and final answers.
5. Model configuration
The model is configured using the Low-Rank Adapter technique by setting the target module.
model = FastLanguageModel.get_peft_model(
model,
r=16,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
lora_alpha=16,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth", # True or "unsloth" for very long context
random_state=3407,
use_rslora=False,
loftq_config=None,
)
Next, the training parameters and trainer (Trainer) were configured. The model, tokenizer, dataset, and other key training parameters were provided to the trainer to optimize the fine-tuning process of the model.
from trl import SFTTrainer
from transformers import TrainingArguments
from unsloth import is_bfloat16_supported
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
# Use num_train_epochs = 1, warmup_ratio for full training runs!
warmup_steps=5,
max_steps=60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
6. Model training
trainer_stats = trainer.train()
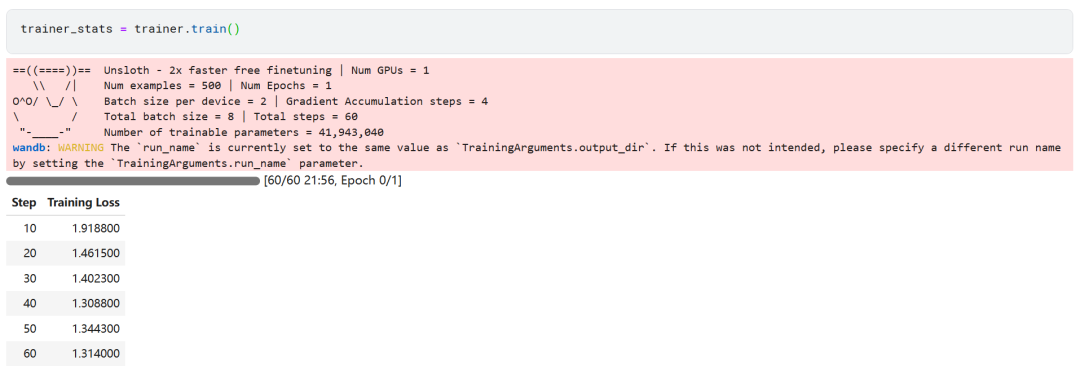
The model training process took 22 minutes. The gradual decrease in training loss (loss) is a positive sign that the model performance has improved.
Users can visit the Weights & Biases website to view the full model evaluation report.
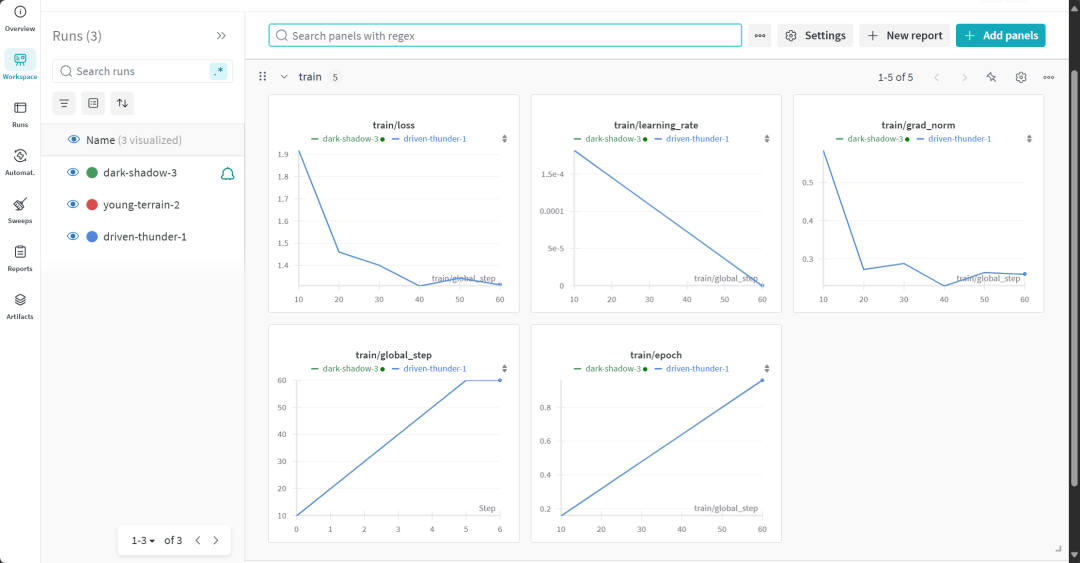
7. Assessment of the reasoning capacity of the fine-tuned model
For comparative analysis, the same questions were again asked to the fine-tuned model as before the fine-tuning to observe the change in model performance.
question = "A 61-year-old woman with a long history of involuntary urine loss during activities like coughing or sneezing but no leakage at night undergoes a gynecological exam and Q-tip test. Based on these findings, what would cystometry most likely reveal about her residual volume and detrusor contractions?"
FastLanguageModel.for_inference(model) # Unsloth has 2x faster inference!
inputs = tokenizer([prompt_style.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
use_cache=True,
)
response = tokenizer.batch_decode(outputs)
print(response[0].split("### Response:")[1])
The experimental results show that the quality of the output of the fine-tuned model has been significantly improved and the answers are more accurate. The chain of thoughts was presented more concisely and the final answer was more direct and clearly answered in just one paragraph, indicating that the fine-tuning of the model was successful.

8. Local storage of models
Now, save the adapter, the full model, and the tokenizer locally for use in other projects.
new_model_local = "DeepSeek-R1-Medical-COT"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method="merged_16bit")
9. Model uploaded to Hugging Face Hub
Adapters, tokenizers, and full models were also pushed to the Hugging Face Hub, with the goal of enabling the AI community to leverage this fine-tuned model and integrate it easily into their systems.
new_model_online = "realyinchen/DeepSeek-R1-Medical-COT"
model.push_to_hub(new_model_online)
tokenizer.push_to_hub(new_model_online)
model.push_to_hub_merged(new_model_online, tokenizer, save_method="merged_16bit")
summarize
The field of artificial intelligence (AI) is undergoing rapid change. The rise of the open source community presents a strong challenge to the AI landscape that has been dominated by proprietary models for the past three years. Open source Large Language Models (LLMs) are increasingly faster and more efficient, making it easier than ever to fine-tune them with lower computational and memory resources.
This article provides an in-depth look at the DeepSeek R1 inference model and details how its lite version can be fine-tuned for application in medical Q&A scenarios. The fine-tuned inference model not only offers significant performance improvements, but also makes it practical for use in key areas such as medicine, emergency services, and healthcare.
In response to the release of DeepSeek R1, OpenAI also quickly introduced two important tools: a more advanced inference model, o3, and the Operator AI Agent. the latter relies on the new Computer Usage Agent (CUA, the Computer Use Agent) model that demonstrates the ability to autonomously navigate websites and perform complex tasks.
Source Code:
https://www.kaggle.com/code/realyinchen/deepseek-r1-medical-cot
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...