
Retrieval Augmented Generation (RAG) Principles and Practices Foundation Building Guide (Translation)

简介-1")
Despite the continuous release of ever larger and smarter models, state-of-the-art generative Large Language Models (LLMs) still suffer from a major problem: they perform poorly when dealing with tasks that require specialized knowledge. This lack of expertise can lead to problems such as the phenomenon of hallucinations, where models generate inaccurate or fabricated information.Retrieval Augmentation Generation (RAG)This problem is mitigated by giving the model real-time access to domain-specific data from external sources, thus enhancing its ability to provide accurate, detailed answers.
Despite these limitations, generative models are still very influential tools that can automate everyday tasks, assist us in our daily work, and help us interact with data in new ways. So how can we leverage their extensive knowledge while making them serve our specific usage scenarios? The answer lies in providing task-relevant data for generative modeling.
In this paper, we will take an in-depth look at Retrieval Augmented Generative (RAG), a framework that enhances the capabilities of models by allowing them to reference external data. We will explore the limitations of generative modeling that contribute to the RAG We will explain the working principle of RAG and analyze the architecture of RAG pipeline in detail. In addition, we will provide some practical RAG use cases, propose specific RAG implementation methods, introduce some advanced RAG techniques, and discuss RAG evaluation methods.
LLM is a broad term for language models trained on large datasets that are capable of performing a variety of text- and language-related tasks. Generative LLMs are models that are capable of generating new text in response to user prompts, such as those used in chatbots, often referred to asgenerative modelThe LLM is called the LLM of textual data into semantic space. LLMs that encode textual data into semantic space are then calledembedding model. Therefore, in this paper we use the terms generative and embedded models to distinguish between these two types of models.
Limitations of Generative Modeling
Generative models are trained to acquire some general knowledge by training on a large number of datasets, including (but not limited to) social media posts, books, academic articles, and crawled web pages. As a result, these models can generate human-like text, answer a variety of questions, and assist with tasks such as answering, summarizing, and creative writing.
However, the training datasets for the generative models are inevitably incomplete, as they lack information on niche topics and new developments after the dataset cutoff date. Generative models also do not have access to proprietary data in internal databases or repositories. In addition, when these models do not know the answer to a question, they tend to guess, and sometimes that guess is inaccurate. This phenomenon of generating incorrect or fictitious information is known as hallucination and can lead to actual reputational damage in customer-facing AI applications.
The key to improving the performance of generative models on specialized tasks and reducing illusions is to provide additional information not present in the training data. This is where RAG comes in.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmentation Generation (RAG) is a way to retrieve additional data relevant to the current task by retrieving it from external data sources toreinforceA framework for generative macrolanguage modeling of general knowledge.
External data sources can include internal databases, files and repositories, as well as publicly available data such as news articles, websites or other online content. Access to this data allows models to provide more fact-based answers and cite sources in their responses, avoiding 'guessing' when information cannot be found in the model's original training dataset.
Common use cases for RAG include retrieving up-to-date information, accessing specialized domain knowledge, and answering complex, data-driven questions.
RAG Architecture
The basic components of the RAG pipeline can be divided intothree components: external knowledge sources, prompt templates, and generative models. With these components, large language model-driven applications can utilize valuable task-specific data to generate more accurate responses.
简介-2")
External knowledge sources
Without the support of external knowledge, generative models can only be based on theirParametric knowledgegenerating answers, which are learned during the model training phase. With RAG, we can integrate in the pipeline theExternal knowledge sourcesAlso known asNon-parametric knowledgeThe
External data sources are usually task-specific and often beyond the scope of the model's original training data or its parameterized knowledge. In addition, they are usually stored in vector databases, which may vary in subject matter and format.
Common external data sources include internal company databases, laws, regulations, and documents, medical and scientific literature, and crawled web pages. Private data sources can also be used for RAG. personal AI assistants, such as Microsoft's Copilot, leverage a variety of personal data sources, including emails, documents, and instant messages, to provide customized answers and automate tasks more efficiently.
Tip templates
Prompts are the tools we use to communicate requests to the generating model. Prompts can contain multiple elements, but typically include queries, directives, and context to guide the model in generating relevant responses.
Tip templates A structured way of generating standardized prompts is provided in which various queries and contexts can be inserted. In the RAG (Retrieval Augmented Generation) process, relevant data is retrieved from external data sources and inserted into the hint templates to augment the hints. Basically, the prompt template acts as a bridge between the external data and the model, providing contextually relevant information for the model to use in its reasoning to generate accurate responses.
prompt_template = "上下文信息如下。\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"根据上下文信息而不是先前的知识,回答问题。\n"
"问题: {query_str}\n"
"回答: "
Generative Large Language Model (LLM)
The final component in the RAG is the generative Large Language Model (LLM), also known as the generative model, which is used to generate the final answer to the user's query. Enhanced prompts, enriched with information provided by an external knowledge base, are then sent to the model, which generates answers that combine internal knowledge with newly retrieved data.
Now that we've discussed the architecture of RAG and its key components, let's look at how they fit together in a RAG workflow.
How does RAG work?
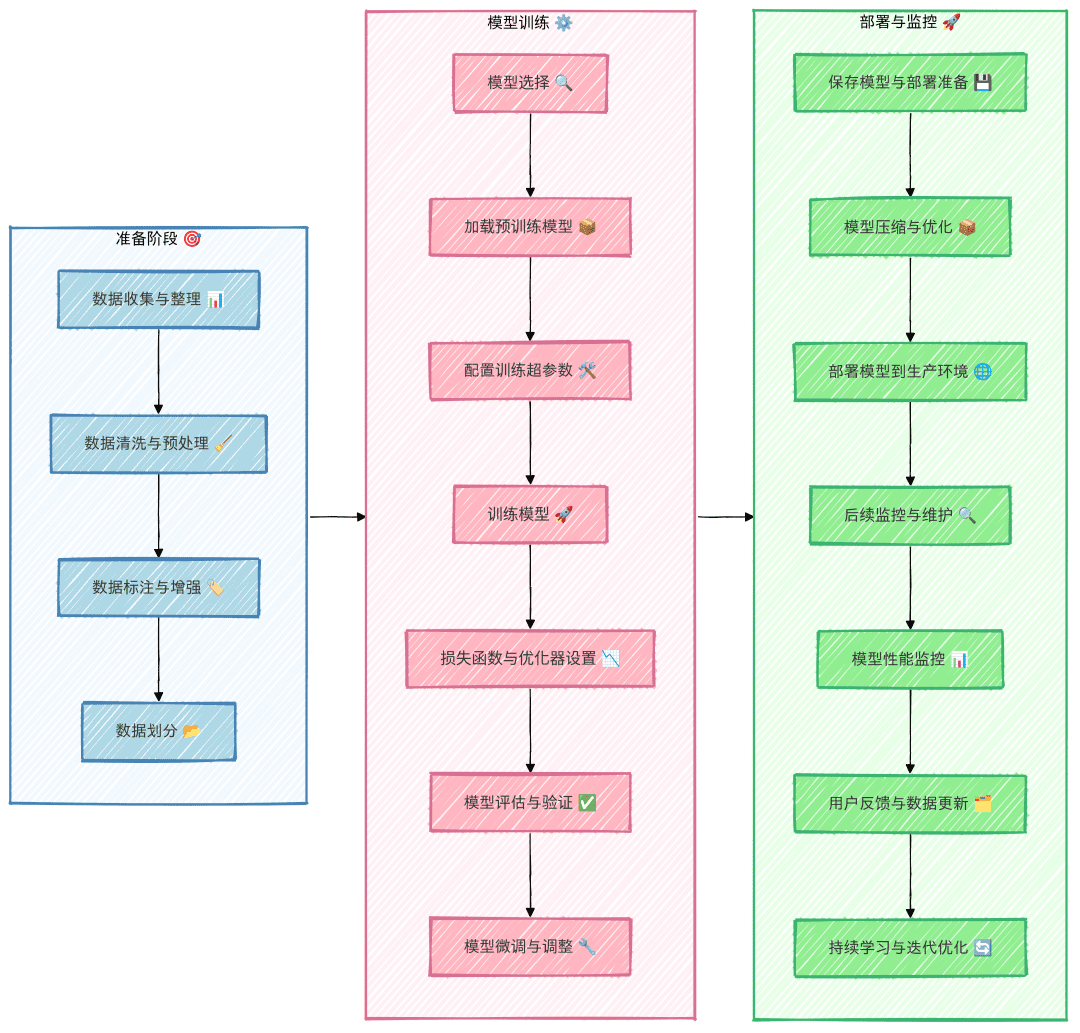
RAG is a multistep framework with two phases. First, in the ingestion phase, external knowledge is preprocessed and prepared for retrieval. Next, in the inference phase, the model retrieves relevant data from the external knowledge base, augments it with user prompts, and generates responses. Now, let's look at each phase in more detail.
Stage 1: Ingestion
First, external knowledge sources need to be prepared. Simply put, the external data needs to be cleaned and transformed into a format that the model can understand. This is called uptake phase. During the ingestion process, the text or image data is passed through a process called the quantitative The process of converting from its original format to embedding. Once embeddings have been generated, they need to be stored in a way that allows for easy retrieval at a later date. Most commonly, these embeddings are stored in vector databases so that information can be retrieved quickly and efficiently for downstream tasks.
简介-3")
Stage 2: Reasoning
Once the external data is encoded and stored in the inference stage for retrieval, where the model generates responses or answers questions. Reasoning is divided into three steps: retrieval, enhancement and generation.
简介-4")
look up
The inference phase begins with retrieval, where data is retrieved from an external knowledge source in response to a user query. Retrieval methods vary in format and complexity, however, in the simple RAG model, external knowledge is embedded and stored in a vector database, theSimilarity Search is the simplest form of search.
To perform a similarity search, it is first necessary to embed the user query in the same multidimensional space as the external data, so that the query can be directly compared with the embedded external data. In the Similarity Search in which the distance between the query and the external data points is calculated and the point with the shortest distance is returned, thus completing the retrieval process.
Augmentation
Once the most relevant data points have been retrieved from external data sources, the enhancement process integrates them by inserting this external information into predefined cue templates.
Generation
After the augmented prompts are injected into the model's context window, the model proceeds to generate the final response to the user input. In the generation phase, the model combines its internal linguistic understanding with the enhanced external data to generate coherent and contextualized answers.
This step involves generating responses in a smooth, natural way while utilizing rich information to ensure that the output is both accurate and relevant to the user's query. Enhancement aims to integrate external facts, while generation translates this combined knowledge into a well-structured, human-like output for a specific request.
RAG Application Examples
Now that we have covered the definition of RAG, how it works, and its architecture, we will explore some practical application scenarios to see how this framework can be used in the real world. By augmenting generative large language models with up-to-date, task-specific data, their accuracy, relevance, and ability to handle specialized tasks can be improved. As a result, RAG is widely used in real-time information retrieval, content recommendation systems, and the construction of personal AI assistants.
Real-time information retrieval
When generative models are used alone, they can only retrieve information that exists in their training dataset. In the framework of RAG, however, models are able to retrieve data and information from external sources, thus ensuring more accurate and up-to-date responses. One such example is ChatGPT-4o's ability to access and retrieve information directly from web pages in real time. This is a RAG use case that utilizes external data sources that are not embedded in a vector database, and is particularly useful for answering user queries about news or other time-sensitive events such as stock prices, travel advice, and weather updates.
Content Recommender System
Content recommendation systems analyze user data and preferences to recommend relevant products or content to users. Traditionally, these systems require complex integration models and large datasets of user preferences.RAG simplifies the construction of recommender systems by directly integrating external, contextually relevant user data with the general knowledge of the model, enabling them to generate personalized recommendations.
Personal AI Assistant
Our personal data, including files, emails, Slack messages, and notes, are important data sources for generating models. By running RAG on personal data, we can interact with it in a conversational manner, increasing efficiency and automating mundane tasks. With the help of AI assistants such as Microsoft's Copilot cap (a poem) Notion (of Ask AI), we can use simple prompts to search for relevant documents, write personalized emails, summarize documents and meeting notes, schedule meetings, and more.
How to implement RAG
Now that we have an understanding of how RAG works, we'll look at how to build a functional RAG pipeline.RAG can be implemented through a number of different frameworks that simplify the build process by providing pre-built tools and modules that enable the integration of individual RAG components, as well as external services like vector databases, embedding generation tools, and other APIs.
LangChain, LlamaIndex, and DSPy are all powerful open source Python libraries with active communities that provide powerful tools and integrations for building and optimizing RAG pipelines and Large Language Model (LLM) applications.
- LangChain Provides building blocks, components and third-party integrations to help develop LLM-based applications. It can be used in conjunction with LangGraph are used together to build a proxy-style RAG pipeline, and through the LangSmith Conduct a RAG assessment.
- LlamaIndex is a framework that provides tools for building LLM applications that integrate external data sources.LlamaIndex maintains the LlamaHubThis is a rich library of data loaders, proxy tools, datasets and other components that simplify the creation of RAG pipelines.
- DSPy is a modular framework for optimizing LLM pipelines. LLM and RM (Retrieval Model) can be configured in DSPy for seamless optimization of RAG pipelines.
Weaviate provides integrated (as in integrated circuit) cap (a poem) formulas , which can be used with each of the above frameworks. For specific examples, check out our notebook showing how to use Weaviate with the LlamaIndex cap (a poem) DSPy Build the RAG pipeline.
If you want to get the RAG up and running quickly, check out the VerbaVerba is an out-of-the-box open source RAG application with a shiny pre-built front-end.Verba enables you to visually explore datasets, extract insights, and build customizable RAG pipelines in a few simple steps without having to learn a whole new framework.Verba is a versatile tool that can be used as a playground for testing and experimenting with RAG pipelines as well as for individual tasks such as assisting with research, analyzing internal documents and streamlining various RAG-related tasks.
Implementing an out-of-the-box RAG with Verba
RAG technology
Traditional RAG workflows typically consist of an external data source embedded in a vector database that is retrieved through similarity searches. However, there are several ways to enhance the RAG workflow to obtain more accurate and robust results, collectively referred to as Advanced RAG.
The functionality of the RAG pipeline can be further extended by introducing graph databases and agents that enable more advanced reasoning and dynamic data retrieval. In the next sections, we introduce some common advanced RAG techniques and provide an overview of agent-based RAG and graph RAG.
Advanced RAG
Advanced RAG techniques can be deployed at all stages of the pipeline. Pre-retrieval strategies such as Metadata Filtering and text chunking Search efficiency and relevance can be improved by narrowing the search and ensuring that only the most relevant parts of the data are considered. The use of more advanced search techniques such as Hybrid Search, which combines the advantages of similarity search and keyword search, can also produce more robust retrieval results. Finally, by using a ranking model for the retrieval results re-order and generated using a Large Language Model (LLM) fine-tuned based on domain-specific data can improve the quality of the generated results.
简介-5")
If you'd like to explore this topic in more depth, check out our article about the Advanced RAG Technology The blog post.
Proxy RAG
AI Agent are autonomous systems that can interpret information, make plans, and make decisions. When added to a RAG pipeline, agents can reformulate user queries and re-retrieve more relevant information when initial results are inaccurate or irrelevant. Agent-based RAGs can also handle more complex queries that require multi-step reasoning, such as comparing information across multiple documents, asking follow-up questions, and iteratively adjusting retrieval and generation strategies.
If you want to dive deeper into a RAG pipeline that includes proxies and utilizes advanced techniques like text chunking and reordering, check out this post on the LlamaIndex blog writings matching notebooksThe
Graphics RAG
Traditional RAG is excellent at solving Q&A tasks through simple retrieval, but it can't answer questions that need to be answered from thetotalThe problem of deriving conclusions from an external knowledge base. Graphical RAG aims to address this problem by using generative models to create a knowledge graph that extracts and stores relationships between key entities, which are then added as data sources to the RAG process. This allows the RAG system to respond to queries that require comparing and summarizing multiple documents and data sources.
For more information on building a graphics RAG process, see Microsoft's GraphRAG software packagecap (a poem)(computer) fileThe
How to evaluate a RAG
RAG is a multi-phase, multi-step framework that requires global and fine-grainedvaluation. This assessment methodology ensures component-level reliability and overall accuracy. In this section, we explore these two assessment methods and introduce RAGAS, a popular assessment framework.
简介-6")
Component Level Evaluation
At the component level, RAG evaluations typically focus on assessing the quality of retrievers and generators, as they play a critical role in generating accurate and relevant responses.
The evaluation of searchers focuses on accuracy and relevance. In this context, theaccuracy measures the accuracy with which the retriever selects the information that directly addresses the query, and the relevance Then, it assesses how well the retrieved data matches the specific needs and context of the query.
On the other hand, the evaluation of the generator focuses on truthfulness and correctness.validity Evaluate whether the response generated by the model accurately reflects the information in the relevant documents and check the consistency of the response with the original source.correctness Then the generated response is evaluated to see if it is authentic and consistent with the real situation or expected answer in the context of the query.
End-to-end assessment
Although the Retriever and Generator are two separate components, they rely on each other to generate consistent responses to user queries.
Computing the semantic similarity of answers is a simple and efficient method for evaluating how well retrievers and generators work together.Answer semantic similarity Calculate the semantic similarity between the generated response and the real answer sample. A high similarity between the generated response and the real answer samples indicates that the process is able to retrieve relevant information and generate a contextually appropriate response.
The RAG Assessment Framework provides a structured methodology, tool or platform to assess RAG processes.RAGAS(Retrieval Enhanced Generation Evaluation) is a particularly popular framework that provides a set of metrics for evaluating retrieval relevance, generation quality, and authenticity without the need to manually label the data. Listen to this Weaviate podcast to learn directly from the RAGAS Creator's RAGAS workings and advanced techniques for optimizing RAGAS scores.
RAG vs. fine-tuning
RAG is one of the ways to extend the capabilities and mitigate the limitations of generative large language models. Fine-tuning large language models is a particularly popular technique that allows models to perform highly specialized tasks by training them on domain-specific data. While fine-tuning may be well suited to certain specific use cases, such as training a biglang model to adopt a particular tone or writing style, RAG is often the most straightforward way to improve model accuracy, reduce illusions, and customize a biglang model for a specific task.
The advantage of RAG is that it eliminates the need to update the weights of the underlying generative model, which is often a costly and time-consuming process.RAG allows the model to dynamically access external data, which improves accuracy without the need for costly retraining. This makes it a practical solution for applications that require real-time information. In the next section, we will delve into the architecture of RAG and how its components work together to create a powerful retrieval enhancement system.
summarize
In this paper, we introduced you to RAG as a framework that utilizes task-specific external knowledge to improve the performance of generative model-driven applications. We learned about the different components of the RAG process, including external knowledge sources, hint templates, and generative models, and how they work together to enable retrieval, enhancement, and generation. We also discuss some popular use cases and implementation frameworks for RAG, such as LangChain, LlamaIndex, and DSPy. Finally, we touch on some of the specialized techniques for RAG, including advanced RAG methods, agent-based RAG, and graphical RAG, as well as methods for evaluating RAG processes.
At the very least, each section of this article could stand alone as a blog post or even a chapter in a book. Therefore, we have put together a resource guide of academic papers, blog posts, YouTube videos, tutorials, notebooks, and recipes to help you learn more about the topics, frameworks, and methods presented in this article.
Resource Guide
📄 Retrieval Enhanced Generation for Knowledge Intensive NLP Tasks (Original RAG paper)
👩🍳 Getting Started with RAG in DSPy(Formulation)
👩🍳 Simple RAG in LlamaIndex(Formulation)
📝 Advanced RAG Technology(blog post)
📒 Agent-based RAG with multiple document agents(Notebook)
📝 Overview of the RAG Assessment(blog post)
📄 Evaluation of retrieval enhancement generation: an overview(Academic papers)
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...