
Ilya Sutskever Blows Up at NeurIPS to Declare: Pretraining Will End, Data Squeeze Comes to an End

Reasoning is unpredictable, so we have to start with incredible, unpredictable AI systems.
Ilya has finally shown up, and right off the bat, he's got something amazing to say. On Friday, Ilya Sutskever, the former chief scientist of OpenAI, said at the Global AI Summit, "We've reached the end of the data we can get, and there's not going to be any more." 
Ilya Sutskever, OpenAI's co-founder and former chief scientist, made headlines when he left the company in May of this year to start his own AI lab, Safe Superintelligence. He's stayed away from the media since leaving OpenAI, but made a rare public appearance this Friday at NeurIPS 2024, a conference on neural information processing systems in Vancouver.
"Pre-training as we know it will undoubtedly come to an end," Sutskever said from the stage.
In the field of artificial intelligence, large-scale pre-training models such as BERT and GPT have achieved great success in recent years, and have become a milestone on the road of technological progress.
Due to complex pre-training objectives and huge model parameters, large-scale pre-training can efficiently capture knowledge from a large amount of labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning it for a specific task, the rich knowledge implicitly encoded in the huge parameters can benefit a variety of downstream tasks. The consensus in the AI community is now to adopt pretraining as the backbone of downstream tasks, rather than learning models from scratch. 
However, in his NeurIPS talk, Ilya Sutskever said that while existing data can still drive AI, the industry is close to running out of new data to call usable. He noted that this trend will eventually force the industry to change the way models are currently trained.
Sutskever compares the situation to the depletion of fossil fuels: just as oil is a finite resource, so is human-generated content on the Internet.
"We've reached peak data, and there's no more data to come," Sutskever said. "We have to utilize the data that is available because there is only one Internet."
Sutskever predicts that the next generation of models will 'exhibit autonomy in a real way'. On the other hand, Agent has become a buzzword in AI.
In addition to being 'autonomous', he also mentioned that future systems will have the ability to reason. Unlike today's AI, which relies heavily on pattern matching (based on what the model has seen before), future AI systems will be able to solve problems step-by-step in a similar way to 'thinking'.
Sutskever says that the more reasoning a system can do, the more 'unpredictable' its behavior becomes. He compares the unpredictability of 'systems with real reasoning power' to the performance of advanced AI in chess - 'even the best human players can't predict their moves.'
These systems will be able to make sense of things from limited data and will not be confused," he said.
In his talk, he compared Scaling in AI systems to evolutionary biology, citing the relationship between brain to body weight ratios between different species in the study. He pointed out that most mammals follow a specific pattern of Scaling, whereas the human family (human ancestors) shows a very different trend of growth in brain-to-body ratio on a logarithmic scale.
Sutskever proposes that just as evolution has found a new Scaling paradigm for the human science brain, AI may go beyond existing pre-training methods to discover entirely new scaling paths. Below is the full text of Ilya Sutskever's talk: 
I would like to thank the conference organizers for choosing a paper for this award (Ilya Sutskever et al.'s Seq2Seq paper was selected for the NeurIPS 2024 Time Check Award). That's great. I would also like to thank my incredible co-authors Oriol Vinyals and Quoc V. Le, who are standing right in front of you. 

You have a picture here, a screenshot. there was a similar talk at NIPS 2014 in Montreal 10 years ago. It was a much more innocent time. Here we appear in the photo. By the way, that was last time, the one below is this time.
Now we have more experience and are hopefully a bit wiser now. But here I would like to talk a little bit about the work itself, and maybe do a 10-year retrospective, because a lot of the things that went right in this work went right, and some of them went less right. We can look back at them and see what happened and how it led us to where we are today. So let's start talking about what we did. The first thing we're going to do is show slides from the same presentation 10 years ago. It's summarized in three main points. An autoregressive model trained on text, it's a large neural network, it's a large dataset, and that's it.
So let's start talking about what we did. The first thing we're going to do is show slides from the same presentation 10 years ago. It's summarized in three main points. An autoregressive model trained on text, it's a large neural network, it's a large dataset, and that's it.
Now let's dive into some more details. 
Here's a slide from 10 years ago that looks good, 'The Deep Learning Hypothesis'. What we're saying here is that if you have a large neural network with 10 layers, but it can do anything a human can do in a fraction of a second. Why do we emphasize 'what humans can do in a fraction of a second'? Why this thing?
Why do we emphasize 'what humans can do in a fraction of a second'? Why this thing?
Well, if you believe in the deep learning dogma that artificial neurons are similar to biological neurons, or at least not too different, and you believe that three real neurons are slow, then humans can process anything quickly. I even mean if there was only one person in the world. If there is one person in the world who can do something in a fraction of a second, then a 10-layer neural network can do it, right?
Next, you simply embed their connections into an artificial neural network.
It's all about motivation. Anything a human can do in a fraction of a second, so can a 10-layer neural network.
We focused on 10-layer neural networks because that was the way we knew how to train back then, and if you could somehow get beyond that number of layers, then you could do more. But at the time, we could only do 10 layers, which is why we emphasized anything a human could do in a fraction of a second.
The other slide from that year illustrates our main idea that you might be able to recognize two things, or at least one thing, you might be able to recognize that autoregression is happening here. 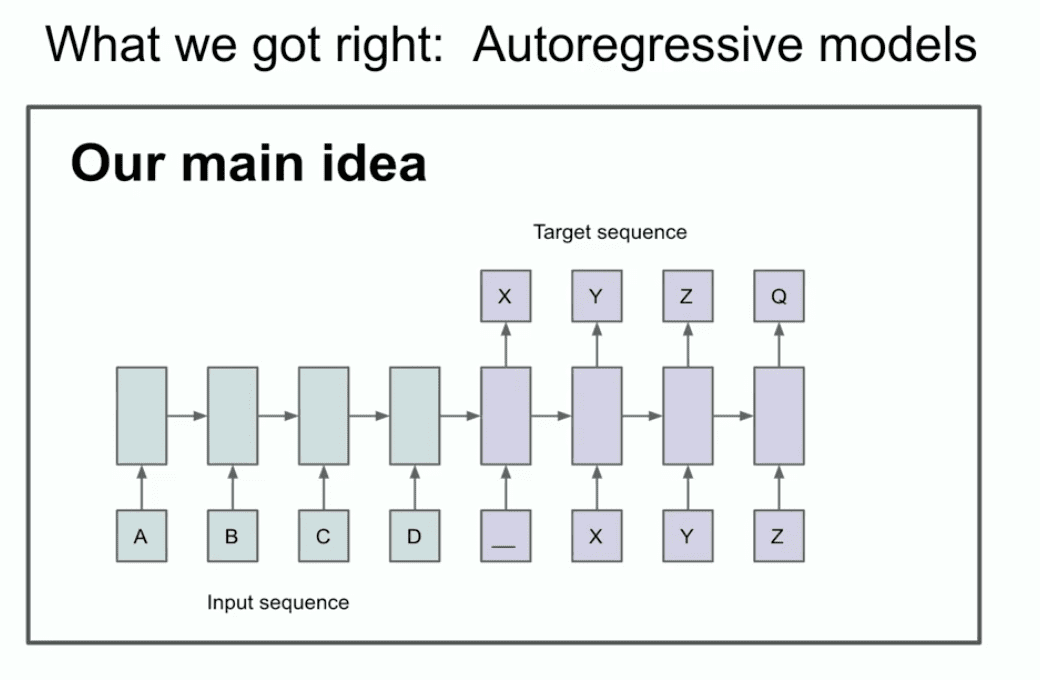
What the hell is it saying? What does this slide actually say? This slide says that if you have an autoregressive model and it predicts the next token good enough, then it will actually grab, capture, and hold the correct distribution of whatever sequence appears next.
It's a relatively new thing, it's not the first autoregressive network, but I think it's the first autoregressive neural network. We really believed that if you train it well, then you'll get whatever you want. In our case, it was a machine translation task that seems conservative now and seemed very bold at the time. Now I'm going to show you some ancient history that many of you have probably never seen before, and it's called the LSTM.
For those unfamiliar, the LSTM is the poor deep learning researcher in the Transformer What was done before.
It's basically a ResNet, but rotated 90 degrees, so it's an LSTM. So it's an LSTM. an LSTM is like a slightly more complex ResNet. you can see the integrator, which is now called the residual stream. but you have some multiplication going on. It's a little bit complicated, but that's what we're doing. This is a ResNet rotated 90 degrees. 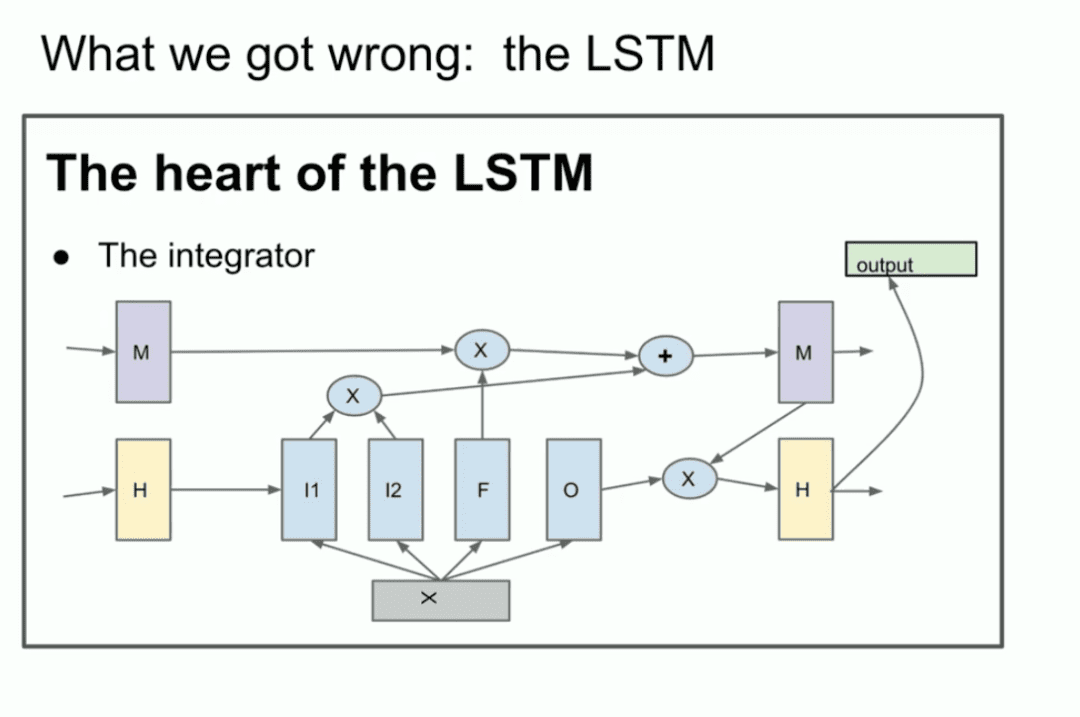
Another key point I wanted to emphasize in that old talk was that we used parallelization, but not just parallelization.
We used pipelining, allocating one GPU per neural network layer, which, as we know now, is not a smart strategy, but we weren't very smart at the time. So we used it and got 3.5 times faster with 8 GPUs. 
The final conclusion, that's the most important slide. It illuminates what might be the beginning of Scaling Laws. If you have a very large dataset and you train a very large neural network, success is guaranteed. One could argue that if one is generous, that's really what's happening. 
Now, I want to mention another idea that I think has really stood the test of time. It's the core idea of deep learning itself. It's the idea of connectionism. The idea is that if you believe that artificial neurons are kind of like biological neurons. If you believe that one is a little bit like the other, then it gives you the confidence to believe in hyperscale neural networks. They don't need to be really on the scale of a human brain, they might be a little bit smaller, but you can configure them to do pretty much everything that we do.
But there's still a difference between that and humans, because the human brain figures out how to reconfigure itself, and we're using the best learning algorithms we have, which requires as many data points as parameters. Humans do a much better job of that. All of this is geared toward, what I might call, the pre-training era.
All of this is geared toward, what I might call, the pre-training era.
And then we have what we call the GPT-2 model, the GPT-3 model, the Scaling Laws, and I would like to make a special mention of my former collaborator Alec Radford, as well as Jared Kaplan and Dario Amodei, for their efforts in realizing this work. 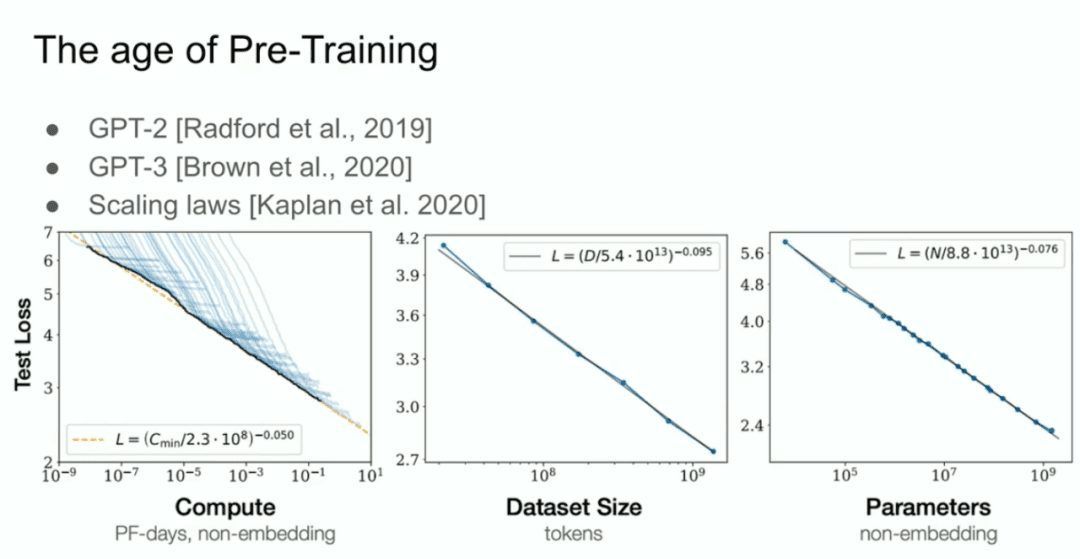 That's the era of pre-training, and that's what's driving all the advances, all the advances we're seeing today, mega-neural networks, mega-neural networks trained on huge datasets.
That's the era of pre-training, and that's what's driving all the advances, all the advances we're seeing today, mega-neural networks, mega-neural networks trained on huge datasets.
But the pre-training route as we know it will undoubtedly end. Why will it end? Because computers keep growing through better hardware, better algorithms, and logic clusters, and all of these things keep increasing your computing power, and the data isn't growing because all we have is an Internet. 
You could even say that data is the fossil fuel of AI. It's like it was created in a certain way and now that we're using it, we've maximized the use of the data and it can't get any better. We figure out what we have to do with the data that we have now. I'm still going to work on that, and that still gets us pretty far, but the problem is that there's only one internet.
So here I will venture to speculate on what will happen next. In fact, I don't even need to speculate because many others are speculating as well, and I'll mention their speculations.
- You may have heard the phrase 'Intelligent Body Agent', it's quite common and I'm sure eventually something will happen where people feel intelligent bodies are the future.
- More specifically, but also somewhat vaguely, synthetic data. But what does synthetic data mean? Figuring that out is a huge challenge, and I'm sure there are all sorts of interesting developments there by different people.
- There's also inference time computation, or perhaps more recently (OpenAI's) o1, the o1 model that most vividly demonstrates people trying to figure out what to do after pre-training.
These are all very good things. 
I want to mention another example from biology that I think is really cool. Many years ago at this conference I also saw a presentation where someone showed this graph which showed the relationship between body size and brain size in mammals. In this case, it was massive. That presentation, I remember it clearly, they said that in biology everything is confusing, but here you have a rare example of a very strong relationship between the size of an animal's body and their brain.
Out of serendipity, I became curious about this picture.  So I went to Google and searched by image.
So I went to Google and searched by image.
In this picture, a variety of mammals are listed, as well as non-primates, but largely the same, and primitives. As far as I can tell, primitives were close relatives of humans in their evolution, like Neanderthals. For example, the 'Energized Man'. Interestingly, they have different slopes of the brain to body ratio index. Very interesting.
This means that there is a case, there is a case where biology figures out some sort of different scale. Obviously, something is different. By the way, I want to emphasize that this x-axis is a logarithmic scale. This is 100, 1,000, 10,000, 100,000, again in grams, 1 gram, 10 grams, 100 grams, a kilogram. So it's possible for things to be different.
What we're doing, what we've been doing so far in terms of scaling, we're actually finding that how we scale becomes the number one priority. There's no doubt in this space that everybody who works here will figure out what to do. But I want to talk about it here. I want to take a few minutes to make a projection for the long term, something that all of us face, right?  All the progress we're making is amazing progress. I mean, people who worked in this field 10 years ago, you remember how powerless everything was. If you've joined the field of deep learning in the last two years, you probably can't even empathize with it.
All the progress we're making is amazing progress. I mean, people who worked in this field 10 years ago, you remember how powerless everything was. If you've joined the field of deep learning in the last two years, you probably can't even empathize with it.
I want to talk a little bit about 'superintelligence' because that's clearly where the field is going and what the field is trying to build.
While language models have incredible capabilities right now, they're also a bit unreliable. It's not clear how to reconcile this, but eventually, sooner or later, the goal will be realized: these systems will become intelligences in a real way. Right now, these systems aren't powerful meaningful perceptual intelligences; in fact, they're just beginning to reason. By the way, the more a system reasons, the more unpredictable it becomes.
We're used to all deep learning being very predictable. Because if you've been working on replicating human intuition, going back to a 0.1 second reaction time, what kind of processing does our brain do? That's intuition, and we've given AIS some of that intuition.
But reasoning, you see some early signs that reasoning is unpredictable. Chess, for example, is unpredictable for the best human players. So we're going to have to deal with very unpredictable AI systems. They will understand things from limited data and will not be confused.
All of this is very limiting. By the way, I didn't say how or when it would and when all of these things would happen with 'self-awareness', because why shouldn't 'self-awareness' be useful? We ourselves are part of the model of our own world.
When all of these things come together, we will have systems with qualities and attributes completely different from those that exist today. They will, of course, have incredible and amazing capabilities. But the problem with a system like this is that I suspect it will be very different.
I would say that predicting the future is certainly impossible as well. Really, all sorts of things are possible. Thank you all.
After a round of applause at the Neurlps conference, Ilya answered a few short questions from a couple of questioners.
Q: In 2024, are there any other biological structures related to human cognition that you think are worth exploring in a similar way, or are there any other areas of interest to you?
Ilya:I would answer the question this way: if you or someone has an insight into a specific problem, like "hey, we're clearly ignoring that the brain is doing something, and we're not doing it", and it's achievable, then they should go deeper into that direction. Personally, I have no such insights. Of course, it also depends on the level of research abstraction you're focusing on. Many people aspire to develop biologically inspired AI. In a way, one could argue that biologically inspired AI has been a huge success - after all, the whole basis of deep learning is biologically inspired AI. but on the other hand, that biologically inspiration is actually very, very limited. It's basically just "let's use neurons" - that's all bio-inspired is. More detailed, deeper levels of bio-inspiration are harder to achieve, but I wouldn't rule it out. I think it might be very valuable if someone with special insight could discover some new angle. Q: I'd like to ask a question about autocorrect.
You mentioned that inference may be one of the core directions of development for future models and may be a differentiating feature. In some of the poster presentation sessions, we have seen that there is an "illusion" of current models. Our current method of analyzing whether a model is hallucinating (please correct me if I'm misunderstanding, you're the expert in this area) is mainly based on statistical analysis, e.g., determining whether there is a deviation from the mean by some deviation from the standard deviation. In the future, do you think that if the model has the ability to reason, it will be able to self-correct like autocorrect and thus become a core feature of future models? That way the model wouldn't have as many hallucinations because it would be able to recognize situations where it generates its own hallucinatory content. This may be a more complex question, but do you think future models will be able to understand and detect the occurrence of hallucinations through reasoning?
Ilya:Answer: yes.
I think that the situation you describe is very likely. Though I'm not sure, I suggest you check it out, and this scenario may have already occurred in some early models of reasoning. But in the long run, why wouldn't it be possible?
Q: I mean, it's like the autocorrect feature in Microsoft Word, it's a core feature.
Ilya:Yeah, I just think calling it "autocorrect" is actually a bit of an understatement. When you mention "autocorrect," it conjures up images of relatively simple features, but the concept goes far beyond autocorrect. Overall, though, the answer is yes.
QUESTIONER: Thank you. Next is the second questioner.
Q: Hi Ilya. i really liked the ending with the mysterious whiteout. Will the AIs replace us, or are they superior to us? Do they need rights? It's a whole new species. Homo sapiens (Homo sapiens) birthed this intelligence, and I think the people over at Reinforcement Learning might think we need rights for these beings.
I have an unrelated question: how do we create the right incentives for humans to create them in a way that allows them to enjoy the same freedoms that we Homo sapiens enjoy?
Ilya:I think these are questions that in a sense people should be thinking about and reflecting on more. But to your question about what kind of incentives we should create, I don't think I can confidently answer a question like that. It sounds like we're talking about creating some kind of top-down structure or governance model, but I'm really not too sure about that.
Next is the last questioner.
Q: Hi Ilya, thanks for the great presentation. I'm from the University of Toronto. Thank you for all the work you have done. I would like to ask you if you think LLMs are capable of generalizing multi-hop inference outside of a distribution?
Ilya:Okay, this question assumes that the answer is either "yes" or "no", but it really shouldn't be answered that way. Because we need to figure out first: what does out-of-distribution generalization really mean? What is intra-distributive? What is out-of-distribution? Because this is a talk about "time-testing." I want to say that a long, long time ago, before deep learning, people used string matching and n-grams to do machine translation. Back then, people relied on statistical phrase tables. Can you imagine? These methods had tens of thousands of lines of code complexity, really unimaginable complexity. And at that time, generalization was defined as whether the translation result was not literally identical to the phrase representation in the dataset. Now we might say, "My model scored high in a math contest, but maybe some of the ideas for these math problems were discussed in some forum on the Internet at one time or another, and so the model might have just remembered them." Well, you could argue that this could be within the distribution, or it could be the result of memorization. But I think it's true that our standards for generalization have risen dramatically -- one might even say dramatically and inconceivably so.
So, my answer is that, to some extent, models may not be nearly as good at generalizing as humans. I do think humans are much better at generalization. But at the same time, it's also true that AI models are capable of out-of-distribution generalization to some extent. I hope this answer is sort of useful to you, even if it sounds a bit redundant.
Q: Thank you.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...