
Google Agents and Basic Applications White Paper (Chinese version)

By Julia Wiesinger, Patrick Marlow and Vladimir Vuskovic
Original: https://www.kaggle.com/whitepaper-agents
catalogs
summary
What is an intelligent body?
mould
artifact
orchestration layer
Intelligentsia and Models
Cognitive Architecture: How Intelligence Works
Tools: our keys to the outside world
extensions
Sample Extensions
function (math.)
use case
Function Sample Code
data storage
Realization and application
Tool Review
Enhancing model performance through targeted learning
Quick Start Intelligentsia with LangChain
Production applications using Vertex AI intelligences
summarize
This combination of reasoning, logic, and access to external information, connected to generative AI models, leads to the concept of intelligences.
summary
Humans are very good at handling messy pattern recognition tasks. However, they often rely on tools -- such as books, Google searches, or calculators -- to supplement their prior knowledge before they can reach a conclusion.
Just like humans, generative AI models can be trained to use tools to access real-time information or suggest real-world actions. For example, models can use database search tools to access specific information, such as a customer's purchase history, in order to generate tailored shopping recommendations.
Alternatively, based on a user query, the model can make various API calls, send an email response to a colleague or complete a financial transaction on your behalf. To do this, the model must not only access a set of external tools, but also have the ability to plan and execute any task in a self-directed manner.
This combination of reasoning, logic, and access to external information all connects to the generative AI model, leading to the concept of an intelligent body or program that extends the independent capabilities of the generative AI model. This whitepaper explores all of these and related aspects in more detail.
What is an intelligent body?
In its most basic form, a generative AI intelligence can be defined as an application that attempts to achieve a goal by observing the world and acting on it using the tools available to it. Intelligentsia are autonomous and can act independently of human intervention, especially when provided with appropriate goals or intentions to fulfill. Intelligentsia can also be proactive in the methods used to achieve their goals. Even in the absence of an explicit set of instructions from a human, an intelligent body can reason about what it should do next to achieve its ultimate goal. While the concept of intelligences in AI is quite general and powerful, this whitepaper focuses on the specific types of intelligences that generative AI models are capable of building at the time of publication.
In order to understand the inner workings of intelligences, let us first describe the underlying components that drive their behavior, actions, and decisions. The combination of these components can be described as a cognitive architecture, and there exist many such architectures that can be realized by mixing and matching these components. Focusing on the core functions, there are three basic components in the cognitive architecture of an intelligent body, as shown in Figure 1.

Figure 1. Generic Intelligence Architecture and Components
mould
In the context of intelligentsia, a model is a language model (LM) that will be used as a centralized decision maker for the processes of the intelligentsia. Models used by Intelligentsia can be one or more LMs of any size (small/large) that are capable of following instruction-based reasoning and logical frameworks such as ReAct, Chain of Thought, or Thinking Tree. Models can be generic, multimodal, or fine-tuned to the needs of your particular smartbody architecture. For optimal production results, you should utilize the model that best fits your intended end application and ideally has been trained on the data signature associated with the tools you plan to use in your cognitive architecture. It is important to note that the model is typically not trained using the specific configuration settings (i.e., tool selection, orchestration/reasoning settings) of the intelligences. However, the model may be further optimized to perform the tasks of the intelligent body by providing it with examples that demonstrate the functionality of the intelligent body, including instances where the intelligent body uses specific tools or reasoning steps in various contexts.
artifact
The underlying model, despite its impressive text and image generation capabilities, is still limited by its inability to interact with the external world. Tools bridge this gap, enabling intelligences to interact with external data and services while unlocking a broader scope of operations beyond the underlying model itself. Tools can take many forms and have varying depths of complexity, but are typically aligned with common Web API methods such as GET, POST, PATCH, and DELETE. For example, tools can update customer information in a database or fetch weather data to influence the travel recommendations that an intelligence provides to a user. With tools, intelligences can access and process real-world information. This enables them to support more specialized systems such as retrieval-enhanced generation (RAG), which significantly extends the capabilities of intelligences beyond what the underlying model can achieve on its own. We will discuss tools in more detail below, but the most important thing to understand is that tools bridge the gap between the internal functioning of the intelligences and the external world, thus unlocking a wider range of possibilities.
orchestration layer
The orchestration layer describes a cyclic process that controls how an intelligent body acquires information, performs some internal reasoning, and uses that reasoning to inform its next action or decision. Typically, this loop will continue until the intelligent body reaches its goal or stopping point. The complexity of the orchestration layer can vary greatly depending on the intelligences and the tasks they perform. Some loops can be simple computations with decision rules, while others may contain chained logic, involve additional machine learning algorithms, or implement other probabilistic reasoning techniques. We will discuss the implementation of the intelligentsia orchestration layer in more detail in the Cognitive Architecture section.
Intelligentsia and Models
To get a clearer picture of the difference between intelligences and models, consider the following diagram:
| mould | intelligent body |
|---|---|
| Knowledge is limited to what is available in its training data. | Knowledge is extended by connecting external systems via tools. |
| Single-session reasoning/prediction based on user queries. There is no management of session history or continuous context unless explicitly implemented for the model. (i.e. chat history) | Managing session history (i.e., chat logs) to allow multiple rounds of reasoning/prediction based on user queries and decisions made in the orchestration layer. In this case, a "round" is defined as an interaction between an interacting system and an intelligent body. (i.e. 1 incoming event/query and 1 intelligent body response) |
| There is no native tool implementation. | Tools are implemented in the native smart body architecture. |
| No native logic layer is implemented. Users can form prompts as simple questions or use inference frameworks (CoT, ReAct, etc.) to form complex prompts to guide the model in making predictions. | Native cognitive architectures use inference frameworks such as CoT, ReAct, or other pre-built intelligentsia frameworks such as LangChain. |
Cognitive Architecture: How Intelligence Works
Imagine a chef in a busy kitchen. Their goal is to create delicious dishes for restaurant patrons, which involves a cycle of planning, executing, and adjusting.
- They collect information such as customer orders and ingredients in the pantry and refrigerator.
- They do some internal reasoning about the dishes and flavors that can be made based on the information they have just gathered.
- They take action to prepare dishes: chopping vegetables, mixing spices, frying meat.
At each stage of the process, chefs make adjustments as needed, refining their plans as ingredients run out or as they receive feedback from customers, and using the previous set of results to determine their next action plan. This cycle of information intake, planning, execution, and adjustment describes the unique cognitive architecture that chefs employ to achieve their goals.
Like a chef, an intelligent body can use a cognitive architecture to achieve its ultimate goal by iteratively processing information, making informed decisions, and refining subsequent actions based on previous outputs. At the heart of the cognitive architecture of an intelligent body lies the orchestration layer, responsible for maintaining memory, state, reasoning, and planning. It uses the rapidly evolving field of cue engineering and related frameworks to guide reasoning and planning, enabling intelligences to interact with their environments and accomplish tasks more effectively. Research in the areas of cue engineering frameworks and task planning for language models is rapidly evolving, yielding a variety of promising approaches. While not an exhaustive list, the following are some of the most popular frameworks and reasoning techniques as of the publication of this white paper:
- ReAct, a cue engineering framework, provides a thought process strategy for language models to reason and act on user queries, with or without contextual examples.ReAct cues have been shown to outperform multiple SOTA baselines and improve human actionability and credibility for large language models.
- Chain of Thought (CoT), a cue engineering framework that implements reasoning capabilities through intermediate steps.There are various subtechniques of CoT, including self-consistency, active cueing, and multimodal CoT, each of which has strengths and weaknesses depending on the specific application.
- The Thinking Tree (ToT), a cue engineering framework, is well suited for exploratory or strategic foresight tasks. It generalizes thought chain prompts and allows models to explore various thought chains that act as intermediate steps to general problem solving using language models.
An intelligent body can utilize one of the above reasoning techniques or many others to select the next best action for a given user request. For example, let us consider a programmed to use the ReAct The framework selects the right actions and tools for the intelligence of the user query. The sequence of events might look like this:
- The user sends a query to the smart body
- Intelligence begins ReAct sequence
- Intelligentsia provide prompts to the model asking it to generate the next ReAct
One of the steps and its corresponding output:
a. Questions: input questions from user queries, provided with prompts
b. Reflections: model reflections on what should be done next
c. Operations: Model decisions on what to do next
i. This is where tools can be selected
ii. For example, an action could be [Flight, Search, Code, None], where the first three represent known tools that the model can choose from, and the last represents "no tool choice".
d. Operational inputs: the model's decisions on what inputs to provide to the tool, if any.
e. Observations: results of operations/operations on input sequences
i. This thinking/operating/operating input/observation can be repeated as many times as necessary. ii.
f. Final answer: the final answer to the original user query provided by the model
4. The ReAct loop ends and the final answer PS is provided to the user:Hands-on ReAct Implementation Logic

Figure 2. Example Intelligentsia Using ReAct Reasoning in the Orchestration Layer
As shown in Figure 2, the model, tool, and intelligences are configured to work in concert to provide the user with an informed, concise response based on the user's original query. While the model can guess the answer based on its a priori knowledge (creating an illusion), it uses the tools (flights) to search for real-time external information. This additional information is provided to the model to enable it to make more informed decisions based on real factual data, which is aggregated and fed back to the user.
In sum, the quality of an intelligent body's response can be directly related to the model's ability to reason and operate on these various tasks, including the ability to select the right tools and how well the tools are defined. Just as a chef crafts a dish with fresh ingredients and pays attention to customer feedback, an intelligent body relies on sound reasoning and reliable information to deliver optimal results. In the next section, we will delve into the various ways in which intelligentsia connect to fresh data.
Tools: our keys to the outside world
While language models are good at processing information, they lack the ability to directly perceive and influence the real world. This limits their usefulness in situations where they need to interact with external systems or data. This means that, in a sense, a language model is only as good as what it learns from its training data. However, no matter how much data we feed into our models, they still lack the basic ability to interact with the external world. So how can we give our models the ability to interact with external systems in a real-time, context-aware way? Functions, extensions, data stores, and plugins are all ways to provide models with this critical capability.
Though they go by many names, tools are the link that creates a connection between our underlying models and the outside world. This connection to external systems and data enables our intelligences to perform a wide variety of tasks with greater accuracy and reliability. For example, tools can enable an intelligent body to adjust smart home settings, update a calendar, retrieve user information from a database, or send an email based on a specific set of instructions.
As of the date of this whitepaper, there are three main types of tools that Google models can interact with: extensions, functions, and data stores. By equipping intelligences with tools, we unlock their enormous potential to not only understand the world but to act on it, opening the door to countless new applications and possibilities.
extensions
The easiest way to understand extensions is to think of them as bridging the gap between APIs and intelligences in a standardized way, allowing intelligences to seamlessly execute APIs regardless of their underlying implementation. Let's say you've built an intelligent whose goal is to help users book flights. You know you want to use the Google Flights API to retrieve flight information, but you're not sure how to get your smart body to call this API endpoint.

Figure 3. How do intelligences interact with external APIs?
One approach might be to implement custom code that takes an incoming user query, parses it for relevant information, and then makes an API call. For example, in the flight booking use case, a user might say "I want to book a flight from Austin to Zurich." In this case, our custom code solution would need to extract "Austin" and "Zurich" as relevant entities from the user query before attempting to make an API call. But what happens if the user says "I want to book a flight to Zurich" without providing a departure city? Without the required data, the API call will fail and more code will need to be implemented to capture such edge and extreme cases. This approach is not scalable and can easily fail in any situation that is beyond the scope of the implemented custom code.
A more reliable approach is to use extensions. Extensions bridge the gap between intelligences and APIs in the following ways:
- Use the examples to teach intelligences how to use API endpoints.
- Teach the intelligences what parameters are required to successfully call the API endpoint.

Figure 4. Extension to connect intelligences to external APIs
Extensions can be built independently of the Intelligence, but should be provided as part of the Intelligence's configuration. Intelligent Bodies use models and examples at runtime to determine which extensions, if any, are appropriate for solving the user's query. This highlights a key advantage of extensions, their built-in example type, which allows the Intelligent Body to dynamically select the most appropriate extension for the task.

Figure 5. 1-to-Many Relationship between Intelligentsia, Extensions and APIs
Think of it this way: a software developer decides which API endpoint to use when solving a user's problem. If a user wants to book a flight, a developer might use the Google Flights API, and if a user wants to know where the nearest coffee shop is relative to their location, a developer might use the Google Maps API. in the same way, the Intelligentsia/Model Stack uses a set of known extensions to decide which one is best suited to the user's query. If you want to see the extensions in action, you can find them in the Gemini Try them out on the app by going to Settings > Extensions and enabling any extension you want to test. For example, you could enable the Google Flights extension and then ask Gemini to "show flights from Austin to Zurich next Friday".
Sample Extensions
To simplify the use of extensions, Google provides a number of out-of-the-box extensions that can be quickly imported into your project and can be used with minimal configuration. For example, the code interpreter extension in Code Snippet 1 allows you to generate and run Python code from natural language descriptions.
Python
import vertexai
import pprint
PROJECT_ID = "YOUR_PROJECT_ID"
REGION = "us-central1"
vertexai.init(project=PROJECT_ID, location=REGION)
from vertexai.preview.extensions import Extension
extension_code_interpreter = Extension.from_hub("code_interpreter")
CODE_QUERY = """Write a python method to invert a binary tree in O(n) time."""
response = extension_code_interpreter.execute(
operation_id = "generate_and_execute",
operation_params = {"query": CODE_QUERY}
)
print("Generated Code:")
pprint.pprint({response['generated_code']})
# The above snippet will generate the following code.
# Generated Code:
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
Python
def invert_binary_tree(root):
"""
Inverts a binary tree.
Args:
root: The root of the binary tree.
Returns:
The root of the inverted binary tree.
"""
if not root:
return None
# Swap the left and right children recursively
root.left, root.right = \
invert_binary_tree(root.right), invert_binary_tree(root.left)
return root
# Example usage:
# Construct a sample binary tree
# 4
# / \
# 2 7
# / \ / \
# 1 3 6 9
root = TreeNode(4)
root.left = TreeNode(2)
root.right = TreeNode(7)
root.left.left = TreeNode(1)
root.left.right = TreeNode(3)
root.right.left = TreeNode(6)
root.right.right = TreeNode(9)
# Invert the binary tree
inverted_root = invert_binary_tree(root)
Code snippet 1. The code interpreter extension generates and runs Python code.
In summary, extensions provide intelligences with a variety of ways to perceive, interact with, and influence the external world. The selection and invocation of these extensions is guided by the use of examples, all of which are defined as part of the extension configuration.
function (math.)
In the field of software engineering, functions are defined as self-contained code modules that are used to accomplish specific tasks and can be reused as needed. When software developers write programs, they typically create many functions to perform various tasks. They will also define the logic for calling function_a and function_b, as well as the expected inputs and outputs.
Functions work in a very similar way in the domain of intelligences, but we can use models instead of software developers. A model can take a set of known functions and, based on its specification, decide when to use each function and what arguments the function takes. Functions differ from extensions in several ways, most notably:
- Model output functions and their parameters, but no real-time API calls.
- Functions are executed on the client side, while extensions are executed on the smartbody side.
Using our Google Flights example again, a simple setup of the function might look like Figure 7.

Figure 7. How do functions interact with external APIs?
Note that the main difference here is that neither functions nor intelligences interact directly with the Google Flights API. So how do API calls actually happen?
When using functions, the logic and execution of calling the actual API endpoints is transferred from the intelligence to the client application, as shown in Figures 8 and 9 below. This provides the developer with more granular control over the flow of data in the application. There are many reasons why a developer might choose to use functions over extensions, but some common use cases are:
- APIs need to be called at another level of the application stack, rather than directly in the agent architecture flow (e.g., using a middleware system, front-end framework, etc.).
- Security or authentication limitations that prevent the agent from calling the API directly (e.g., the API is not exposed to the Internet, or the agent infrastructure does not have access to the API).
- Time or sequence of operations limitations that prevent agents from calling the API in real time (e.g., batch operations, manual review processes, etc.).
- Additional data transformation logic is required for API responses that the agent cannot perform. For example, some API endpoints do not provide filtering mechanisms to limit the number of results returned. Using functions on the client side provides developers with additional opportunities to perform these transformations.
- Developers want to iterate on proxy development without deploying additional infrastructure for API endpoints (e.g., function calls can be used as a "staked emulation" of the API).
While the differences between the two approaches are more subtle from an internal architectural point of view as shown in Figure 8, function calls provide additional control and reduce dependence on external infrastructure, making them an attractive option for developers.

Figure 8. Client-side and Smartbody-side controls describing extensions and function calls
use case
Models can be used to call functions in order to handle complex client-side execution processes for end-users, where the intelligentsia developer may not want the language model to manage the API execution (as is the case with extensions). Let's consider the following example, in which an intelligent body is trained as a travel concierge to interact with a user who wants to book a vacation trip. The goal is for the intelligent body to generate a list of cities that we can use in our middleware application to download images, data, etc. for the user's travel planning. The user may say:
I would like to go on a ski trip with my family but am not sure where to go.
In a typical prompt for the model, the output might be as follows:
Of course, here is a list of cities to consider for a family ski trip:
- Crested Butte, CO, United States of America
- Whistler, British Columbia, Canada
- Zermatt, Switzerland
Although the output above contains the data we need (city names), the format is not suitable for parsing. With a function call, we can teach the model to format this output in a structured style (e.g., JSON), which is easier for another system to parse. Given the same input prompt from the user, the sample JSON output from the function might look like code snippet 5.
unfixed
function_call {
name: "display_cities"
args: {
"cities": ["Crested Butte", "Whistler", "Zermatt"],
"preferences": "skiing"
}
}
Code Snippet 5. Sample Function Call Load for Displaying a List of Cities and User Preferences This JSON load is generated by the model and then sent to our client server to perform whatever action we wish to perform on it. In this particular case, we will call the Google Places API to fetch the cities provided by the model and look up the images, and then serve them to our users as formatted rich content. Refer to the sequence diagram in Figure 9, which shows the steps of the above interaction in detail.

Figure 9. Sequence diagram showing the life cycle of a function call
The result of the example in Figure 9 is that the model is used to "fill in the blanks" with the parameters needed for the client UI to call the Google Places API. The client UI uses the parameters provided by the model in the returned function to manage the actual API call. This is just one use case for function calls, but there are many other scenarios to consider, such as:
- You want the language model to suggest a function that you can use in your code, but you don't want to include credentials in your code. Since the function call does not run the function, you do not need to include credentials with information about the function in your code.
- You are running an asynchronous operation that may take more than a few seconds to complete. These scenarios apply to function calls because it is an asynchronous operation.
- You want to run the function on a different device than the system that generated the function call and its arguments.
One key thing to remember about functions is that they are intended to provide the developer with more control over the execution of API calls and the overall flow of data in the application. In the example in Figure 9, the developer has chosen not to return the API information to the intelligence because it is not relevant to actions that the intelligence might take in the future. However, depending on the architecture of the application, it may make sense to return external API call data to the intelligent body to influence future reasoning, logic, and operational choices. Ultimately, it is up to the application developer to choose what is appropriate for a particular application.
Function Sample Code
To get the above output from our ski vacation scene, let's build each component to work with our gemini-1.5-flash-001 model. First, let's define the display_cities function as a simple Python method.
Python
def display_cities(cities: list[str], preferences: Optional[str] = None):
"""根据用户的搜索查询和偏好提供城市列表。
Args:
preferences (str): 用户的搜索偏好, 例如滑雪、
海滩、餐馆、烧烤等。
cities (list[str]): 推荐给用户的城市列表。
Returns:
list[str]: 推荐给用户的城市列表。
"""
return cities
Code Snippet 6. Sample Python method for a function that displays a list of cities.
Next, we will instantiate our model, build the tool, and then pass the user's query and the tool to the model. Executing the code below will produce the output shown at the bottom of the code snippet.
Python
from vertexai.generative_models import GenerativeModel, Tool, FunctionDeclaration
model = GenerativeModel("gemini-1.5-flash-001")
display_cities_function = FunctionDeclaration.from_func(display_cities)
tool = Tool(function_declarations=[display_cities_function])
message = "I'd like to take a ski trip with my family but I'm not sure where to go."
res = model.generate_content(message, tools=[tool])
print(f"Function Name: {res.candidates[0].content.parts[0].function_call.name}")
print(f"Function Args: {res.candidates[0].content.parts[0].function_call.args}")
> Function Name: display_cities
> Function Args: {'preferences': 'skiing', 'cities': ['Aspen', 'Vail',
'Park City']}
Code snippet 7. build the tool, send it to the model with the user query, and allow function calls to be made
In summary, functions provide a simple framework that enables application developers to have fine-grained control over data flow and system execution, while effectively utilizing intelligences/models for key input generation. Developers can optionally choose whether to keep intelligences "in the loop" by returning external data, or omit them depending on specific application architectural requirements.
data storage
Imagine a language model as a vast library containing its training data. But unlike a library that is constantly acquiring new books, this library stays static, holding only the knowledge from the initial training. This is a challenge because real-world knowledge is constantly being
Development. Data storage addresses this limitation by providing access to more dynamic and up-to-date information and ensuring that model responses are always based on facts and relevance.
Consider a common scenario in which a developer may need to provide a small amount of additional data to a model, perhaps in the form of a spreadsheet or PDF.

Figure 10. How do intelligences interact with structured and unstructured data?
Data stores allow developers to provide additional data to intelligences in their original format, eliminating the need for time-consuming data conversion, model retraining, or fine-tuning. The data store converts incoming documents into a set of vector database embeddings that can be used by the intelligences to extract the information needed to complement their next action or response to the user.

Figure 11. data stores connect intelligences to various types of new real-time data sources.
Realization and application
In the context of generative AI intelligences, the data store is typically implemented as a vector database, which the developer expects the intelligences to have access to at runtime. While we won't cover vector databases in depth here, the key point to understand is that they store data in the form of vector embeddings, which are high-dimensional vectors or mathematical representations of the data provided. In recent years, one of the most typical examples of the use of data stores with language models has been Retrieval Augmented Generation (RAG) applications. These applications attempt to extend the breadth and depth of model knowledge by providing the model with access to data in a variety of formats, for example:
- Site Content
- Structured data in PDF, Word documents, CSV, spreadsheets and other formats.
- Unstructured data in HTML, PDF, TXT and other formats.

Figure 12. 1-to-many relationships between intelligences and data stores that can represent various types of pre-indexed data
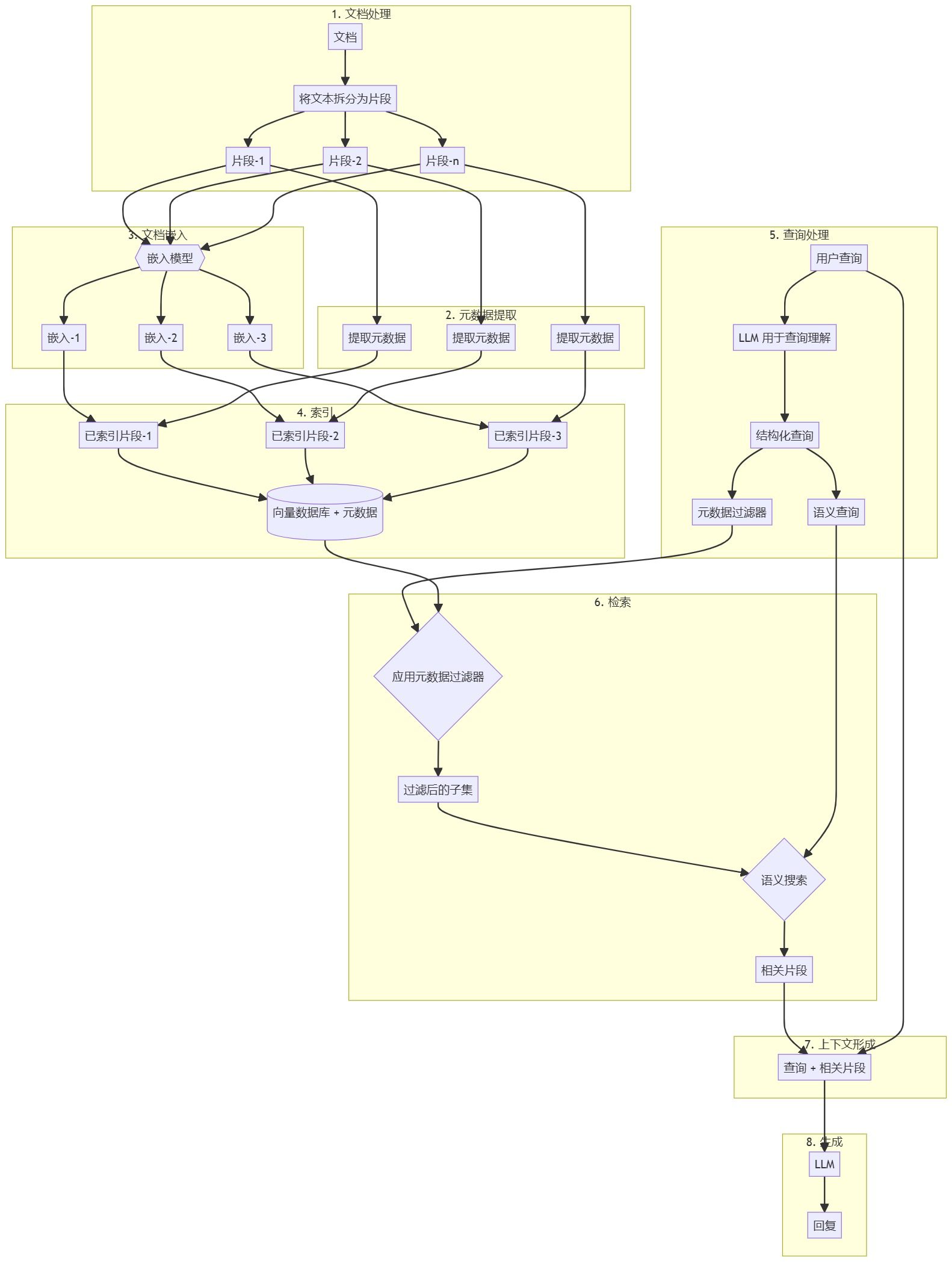
The basic process of each user request and intelligent body response cycle is typically modeled as shown in Figure 13.
- The user query is sent to the embedding model to generate an embedding of the query
- A matching algorithm (e.g., ScaNN) is then used to match the query embedding with the contents of the vector database
- Retrieve matches from the vector database in text format and send them back to the smart body
- Intelligentsia receive user queries and retrieved content and then formulate responses or actions
5. Send the final response to the user

Fig. 13. Lifecycle of a user request and an intelligent body response in a RAG-based application
The end result is an application that allows the intelligences to match the user's query to a known data store via vector search, retrieve the raw content, and provide it to the orchestration layer and model for further processing. The next step may be to provide a final answer to the user or to perform additional vector searches to further optimize the results. An example of interaction with an intelligence implementing a RAG with ReAct reasoning/planning is shown in Figure 14.

Figure 14. Example RAG application using ReAct reasoning/planning
Tool Review
In summary, extensions, functions, and data stores make up several different types of tools that intelligences can use at runtime. Each of these tools has its own purpose and can be used together or separately at the discretion of the intelligence developer.
| extensions | function call | data storage | |
|---|---|---|---|
| fulfillment | Intelligent Body Side Implementation | Client-side execution | Intelligent Body Side Implementation |
| use case |
|
| Developers want to implement Retrieval Augmented Generation (RAG) using any of the following data types:
|
Enhanced Model Performance and Targeted Learning
A key aspect of using models effectively is their ability to select the right tools when generating output, especially when using tools at scale in production. While general training can help models develop this skill.But real-world scenarios usually require more thanknowledge of the training data. Think of it as the difference between basic cooking skills and mastering a specific cuisine. Both require basic culinary knowledge, but the latter requires targeted learning for more nuanced results.
Several approaches exist to help models acquire this type of specific knowledge:
- Contextual Learning: This approach provides generalized models with hints, tools, and small sample samples when reasoning, allowing them to learn "on-the-fly" how and when to use these tools for a particular task.The ReAct framework is an example of this approach in natural language.
- Retrieval-based Context Learning: This technique dynamically populates model hints by retrieving the most relevant information, tools, and related examples from external storage. An example of this is the "example store" in the Vertex AI extension or the data store RAG architecture mentioned earlier.
- Fine-tuning based learning: this method involves training the model with a larger example-specific dataset before reasoning. This helps the model to understand when and how to apply certain tools before receiving any user queries.
To further illustrate the goals of each learning method, we can return to the cooking analogy to explore it.
- Imagine that a chef receives a specific recipe (hint), some key ingredients (related tools), and some sample dishes from customers (sample less). Based on this limited information and the chef's general culinary knowledge, they need to figure out how to prepare "on-the-fly" the dish that best matches the recipe and the customer's preferences. This is contextual learning.
- Now let's imagine our chef in a well-stocked pantry (external data storage) kitchen filled with a variety of ingredients and recipes (examples and tools). The chef is now able to dynamically select ingredients and recipes from the pantry and better align with customer recipes and preferences. This allows chefs to utilize existing and new knowledge to create smarter and more sophisticated dishes. This is retrieval-based contextual learning.
- Finally, let's imagine that we send the chef back to school to learn a new cuisine or dishes (pre-trained on a larger example-specific dataset). This allows the chef to approach future unknown customer recipes with a deeper understanding. If we want the chef to
This approach is perfect when it comes to excelling in a specific cuisine (knowledge area). This is fine-tuning based learning.
Each approach has unique advantages and disadvantages in terms of speed, cost, and latency. However, by combining these techniques in an intelligent body framework, we can leverage the advantages and minimize the disadvantages, resulting in a more robust and adaptable solution.
Quick Start Intelligentsia with LangChain
In order to provide an example of an executable smartbody actually running, we will use LangChain and the LangGraph Libraries to build a rapid prototype. These popular open-source libraries allow users to build client intelligences by "linking" sequences of logic and reasoning together, as well as invoking tools to answer user queries. We will use our gemini-1.5-flash-001 model and some simple tools to answer a multi-stage query from a user, as shown in code snippet 8.
The tools we use are SerpAPI (for Google Search) and Google Places API. after executing our program in code snippet 8, you can see the sample output in code snippet 9.
Python
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
from langchain_community.utilities import SerpAPIWrapper
from langchain_community.tools import GooglePlacesTool
os.environ["SERPAPI_API_KEY"] = "XXXXX"
os.environ["GPLACES_API_KEY"] = "XXXXX"
@tool
def search(query: str):
"""Use the SerpAPI to run a Google Search."""
search = SerpAPIWrapper()
return search.run(query)
@tool
def places(query: str):
"""Use the Google Places API to run a Google Places Query."""
places = GooglePlacesTool()
return places.run(query)
model = ChatVertexAI(model="gemini-1.5-flash-001")
tools = [search, places]
query = "Who did the Texas Longhorns play in football last week? What is the address of the other team's stadium?"
agent = create_react_agent(model, tools)
input = {"messages": [("human", query)]}
for s in agent.stream(input, stream_mode="values"):
message = s["messages"][-1]
if isinstance(message, tuple):
print(message)
else:
message.pretty_print()
Code Snippet 8. Examples of Using Tools LangChain and LangGraph Intelligentsia
unfixed
=============================== 用户消息 ================================
德克萨斯长角牛队上周的橄榄球赛对手是谁?对方球队体育场的地址是什么?
================================= AI 消息 =================================
工具调用:搜索
参数:
查询:德克萨斯长角牛队橄榄球赛程
================================ 工具消息 ================================
名称:搜索
{...结果:“NCAA 一级橄榄球联赛,佐治亚州,日期...”}
================================= AI 消息 =================================
德克萨斯长角牛队上周与佐治亚斗牛犬队进行了比赛。
工具调用:地点
参数:
查询:佐治亚斗牛犬队体育场
================================ 工具消息 ================================
名称:地点
{...桑福德体育场地址:桑福德路 100 号...}
================================= AI 消息 =================================
佐治亚斗牛犬队体育场的地址是佐治亚州雅典市桑福德路 100 号,邮编 30602。
Code Snippet 9. Output of the program in Code Snippet 8.
While this is a fairly simple example of an intelligent body, it demonstrates all of the basic components of modeling, orchestration, and tooling working together to achieve a specific goal. In the final section, we'll explore how these components fit together in Google-scale hosted products such as Vertex AI intelligences and Generative Playbooks.
Production applications using Vertex AI intelligences
While this whitepaper explores the core components of intelligences, building production-grade applications requires integrating them with other tools such as user interfaces, evaluation frameworks, and continuous improvement mechanisms.Google's Vertex AI platform simplifies this process by providing a fully hosted environment that includes all of the essential elements described earlier. Using a natural language interface, developers can quickly define key elements of their intelligences - goals, task descriptions, tools, sub-intelligences for task delegation, and examples - to easily build the desired system behavior. In addition, the platform provides a set of development tools that can be used to test, evaluate, measure the performance of intelligences, debug and improve the overall quality of developed intelligences. This allows developers to focus on building and optimizing their intelligences, while the complexity of infrastructure, deployment and maintenance is managed by the platform itself.
In Figure 15, we provide an example architecture for an intelligent body built on the Vertex AI platform that uses various features such as the Vertex Agent Builder, Vertex Extensions, Vertex Function Calls, and Vertex Example Storage. The architecture includes many of the various components required for production-ready applications.

Figure 15. Example architecture of an end-to-end smart body built on the Vertex AI platform
You can try this example of pre-built smartbody architecture from our official documentation.
summarize
In this whitepaper, we discuss the basic building blocks of generative AI intelligences, their composition, and effective ways to implement them in the form of cognitive architectures. Some of the key takeaways from this whitepaper include:
- Intelligentsia extend the functionality of language models by utilizing tools to access real-time information, suggest practical actions, and autonomously plan and execute complex tasks. Intelligentsia can utilize one or more language models to determine when and how to transition states and use external tools to perform any number of complex tasks that would be difficult or impossible for the model to perform on its own.
- At the heart of intelligent body operations is the orchestration layer, a cognitive architecture that builds reasoning, planning, decision-making, and guides its actions. Various reasoning techniques (e.g., ReAct, thought chains, and thought trees) provide a framework for the orchestration layer to receive information, perform internal reasoning, and generate informed decisions or responses.
- Tools (e.g., extensions, functions, and data stores) act as keys to the outside world for intelligences, allowing them to interact with external systems and access knowledge beyond their training data. Extensions provide a bridge between intelligences and external APIs.This allows for the execution of API calls and the retrieval of real-time information. Functions provide developers with more granular control through the division of responsibility, allowing intelligences to generate function parameters that can be executed on the client. Data stores support data-driven applications by providing intelligences with access to structured or unstructured data.
The future of intelligent bodies holds exciting advances, and we have only just begun to scratch the surface of what is possible. As tools become more sophisticated and reasoning capabilities are enhanced, intelligences will be able to solve increasingly complex problems. In addition, the strategic approach of "Chaining Intelligentsia" will continue to gain momentum. By combining specialized intelligences - each excelling in a particular domain or task - we can deliver superior results across industries and problem areas.
It is important to remember that building complex intelligences architectures requires an iterative approach. Experimentation and refinement are key to finding solutions for specific business cases and organizational needs. No two intelligences are identical due to the generative nature of the underlying models that support their architecture. However, by leveraging the strengths of each underlying component, we can create impactful applications that extend the capabilities of the language model and drive real value.
endnote
- Shafran, I., Cao, Y. et al., 2022, 'ReAct: Synergizing Reasoning and Acting in Language Models'. Available at.
https://arxiv.org/abs/2210.03629 - Wei, J., Wang, X. et al., 2023, 'Chain-of-Thought Prompting Elicits Reasoning in Large Language Models'.
Available at: https://arxiv.org/pdf/2201.11903.pdf. - Wang, X. et al., 2022, 'Self-Consistency Improves Chain of Thought Reasoning in Language Models'.
Available at: https://arxiv.org/abs/2203.11171. - Diao, S. et al., 2023, 'Active Prompting with Chain-of-Thought for Large Language Models'. Available at.
https://arxiv.org/pdf/2302.12246.pdf. - Zhang, H. et al., 2023, 'Multimodal Chain-of-Thought Reasoning in Language Models'. Available at.
https://arxiv.org/abs/2302.00923. - Yao, S. et al., 2023, 'Tree of Thoughts: Deliberate Problem Solving with Large Language Models'. Available at.
https://arxiv.org/abs/2305.10601. - Long, X., 2023, 'Large Language Model Guided Tree-of-Thought'. Available at.
https://arxiv.org/abs/2305.08291. - **Google. 'Google Gemini Application'. Available at: **http://gemini.google.com.
- **Swagger. 'OpenAPI Specification'. Available at: **https://swagger.io/specification/.
- Xie, M., 2022, 'How does in-context learning work? A framework for understanding the differences from
Traditional supervised learning'. Available at: https://ai.stanford.edu/blog/understanding-incontext/. - Google Research. 'ScaNN (Scalable Nearest Neighbors)'. Available at.
https://github.com/google-research/google-research/tree/master/scann. - **LangChain. 'LangChain'. Available at: **https://python.langchain.com/v0.2/docs/introduction/.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...