Free PDF of Fundamentals of Large Models from Zhejiang University - with download link

Fundamentals of Large Models provides an in-depth analysis of the core technologies and practical paths of Large Language Models (LLMs). Starting from the basic theory of language modeling, it systematically explains the principles of model design based on statistics, Recurrent Neural Network (RNN) and Transformer architectures, focusing on the three major mainstream architectures of large language models (Encoder-only, Encoder-Decoder, Decoder-only) and representative models (e.g. BERT, T5, GPT series). The book explains key technologies such as Prompt engineering, efficient fine-tuning of parameters, model editing, and retrieval enhancement generation. Combined with rich case studies, the book demonstrates application practices in different scenarios, providing readers with comprehensive and in-depth learning and practical guidance, helping readers master the application and optimization of large language modeling technologies.

Basics of Language Modeling
- Language modeling based on statistical methods: An in-depth look at n-gram models and the statistics behind them, including Markov assumptions and great likelihood estimation.
- RNN-based language modeling: A detailed explanation of the structural features of recurrent neural networks (RNNs), common gradient vanishing and explosion problems in training, and practical applications in language modeling.
- Transformer-based language modeling: A comprehensive analysis of the core components of the Transformer architecture, such as the self-attention mechanism, feed-forward neural networks (FFNs), layer normalization, and residual connectivity, and their efficient application in language modeling.
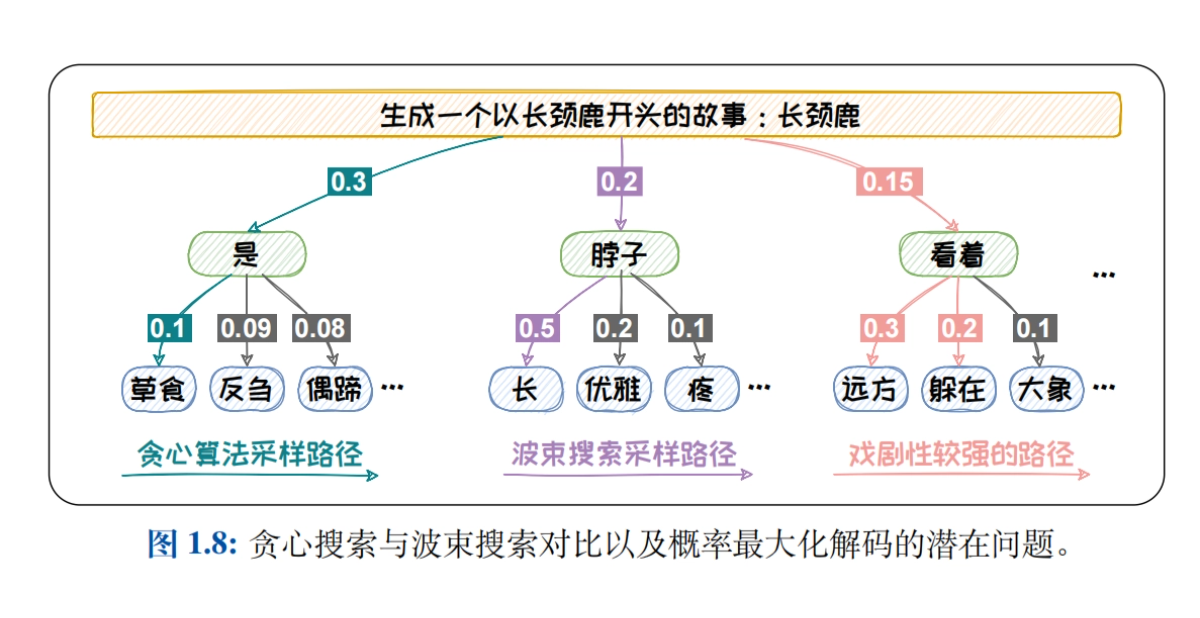
- Sampling methods for language modeling: Decoding strategies such as greedy search, beam search, Top-K sampling, Top-P sampling and Temperature mechanism are systematically introduced to explore the impact of different strategies on the quality of generated text.
- Review of Language Models: Detailed description of intrinsic rubrics (e.g., perplexity) and extrinsic rubrics (e.g., BLEU, ROUGE, BERTScore, G-EVAL), and analysis of the strengths and limitations of each rubric in evaluating the performance of language models.
Big Language Model Architecture
- Big Data + Big Models → New Intelligence: In-depth analysis of the impact of model size and data size on model capability, detailed explanation of Scaling Laws (e.g., Kaplan-McCandlish Law and Chinchilla Law), and discussion of how to improve model performance by optimizing model and data size.
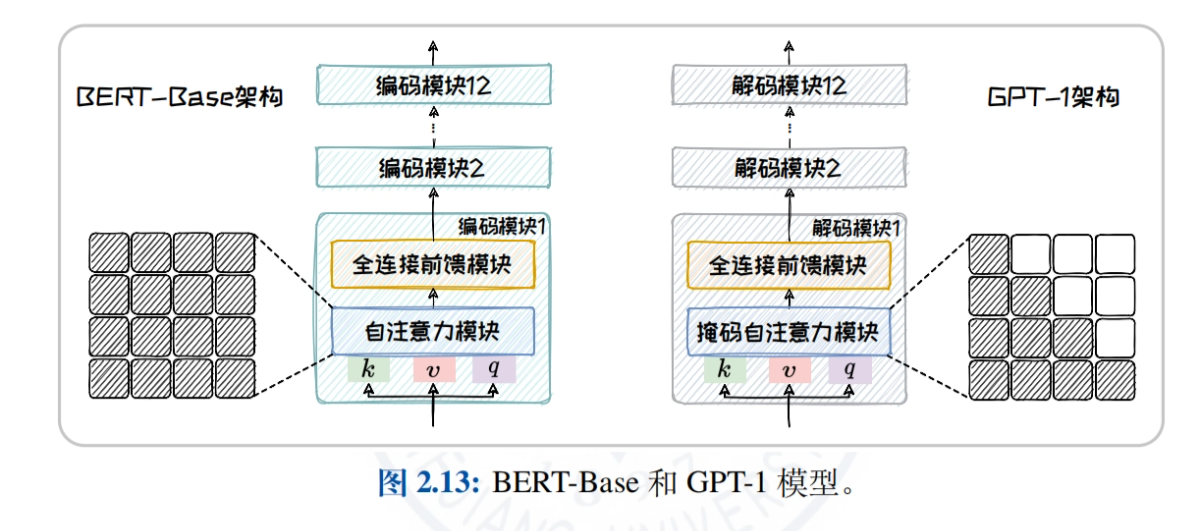
- Overview of the Big Language Model Architecture: Comparatively analyze the attention mechanisms and applicable tasks of three mainstream architectures, Encoder-only, Encoder-Decoder, and Decoder-only, to help readers understand the features and advantages of different architectures.
- Encoder-only architecture: Taking BERT as an example, we explain in depth its model structure, pre-training tasks (e.g., MLM, NSP), and derived models (e.g., RoBERTa, ALBERT, ELECTRA), and explore the application of the model in natural language understanding tasks.
- Encoder-Decoder Architecture: T5 and BART are used as examples to introduce the unified text generation framework and diverse pre-training tasks, and analyze the performance of the models in tasks such as machine translation and text summarization.
- Decoder-only architecture: The development history and characteristics of the GPT family (from GPT-1 to GPT-4) and the LLaMA family (LLaMA1/2/3) are described in detail, and the advantages of the models for open-domain text generation tasks are explored.
- non-Transformer architecture: Introduces state-space models (SSMs) such as RWKV, Mamba, and the training-while-testing (TTT) paradigm, and explores the potential of non-mainstream architectures to be applied in specific scenarios.
Prompt Engineering
- Introduction to Prompt Project: Define Prompt and Prompt Engineering, explain in detail the process of disambiguation and vectorization (Tokenization, Embedding), and explore how to generate high-quality text through a well-designed Prompt bootstrap model.
- In-Context Learning (ICL): Introduces the concepts of zero-sample, single-sample, and few-sample learning, explores example selection strategies (e.g., similarity and diversity), and analyzes how contextual learning can enhance a model's ability to adapt to tasks.
- Chain-of-Thought (CoT): Explain the three modes of CoT: step-by-step (e.g., CoT, Zero-Shot CoT, Auto-CoT), think-through (e.g., ToT, GoT), and brainstorm (e.g., Self-Consistency), and explore how to enhance the model's reasoning ability through the chain of thought.
- Prompt TipsThe introduction of standardized Prompt writing, reasonable summarization of questions, the timely use of CoT, and the use of psychological cues (such as role-playing, situational substitution) and other skills to help readers improve the level of Prompt design.
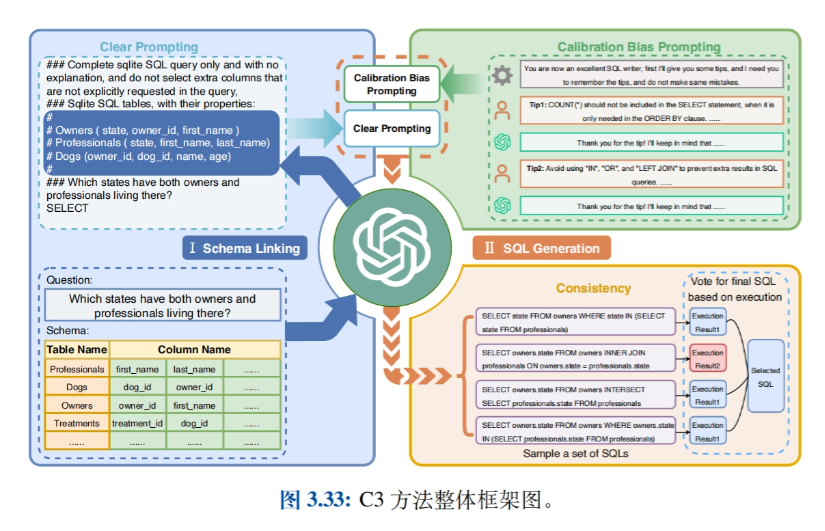
- Related Applications: Introducing applications such as Big Model-based Intelligentsia (Agents), Data Synthesis, Text-to-SQL, GPTS, etc., and exploring practical use cases of Prompt Engineering in different domains.
Efficient fine-tuning of parameters
- Introduction to efficient fine-tuning of parameters: Introducing the two dominant approaches to downstream task adaptation - context learning and instruction fine-tuning - leads to the Parameter Efficient Fine-Tuning (PEFT) technique, detailing the significant advantages in terms of cost reduction and efficiency.
- Parameter Attachment Methods: A detailed description of methods for efficient fine-tuning by attaching new, smaller trainable modules to the model structure, including the implementation and advantages of add-in inputs (e.g., Prompt-tuning), add-in models (e.g., Prefix-tuning and Adapter-tuning), and add-in outputs (e.g., Proxy-tuning).
- Parameter selection method: Introduces methods for fine-tuning only a portion of the model's parameters, categorized into rule-based methods (e.g., BitFit) and learning-based methods (e.g., Child-tuning), and explores how to reduce the computational burden and improve the performance of the model by selectively updating the parameters.
- Low-rank adaptation methods: A detailed introduction to efficient fine-tuning by approximating the original weight update matrix by a low-rank matrix, with a focus on LoRA and its variants (e.g., ReLoRA, AdaLoRA, and DoRA), and a discussion of LoRA's parametric efficiency and task-generalization capabilities.
- Practice and Application: Introduces the usage of the HF-PEFT framework and related techniques, demonstrates use cases of PEFT techniques in tabular data querying and tabular data analysis, and proves the effectiveness of PEFT in improving the performance of large model-specific tasks.
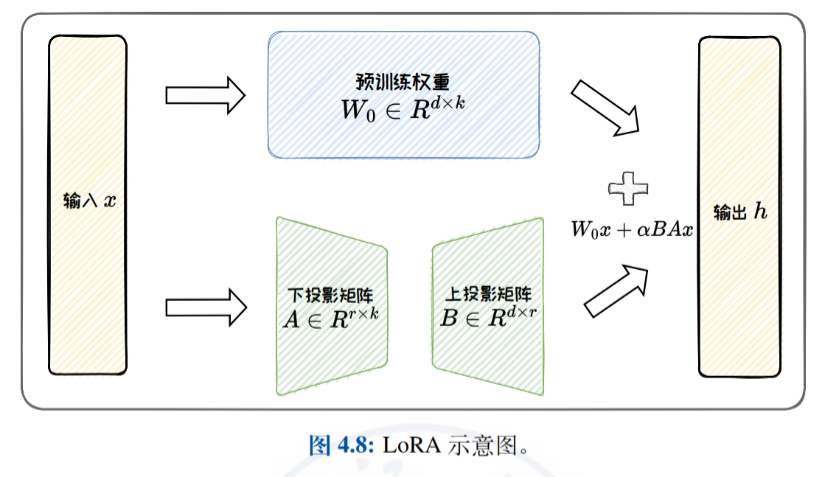
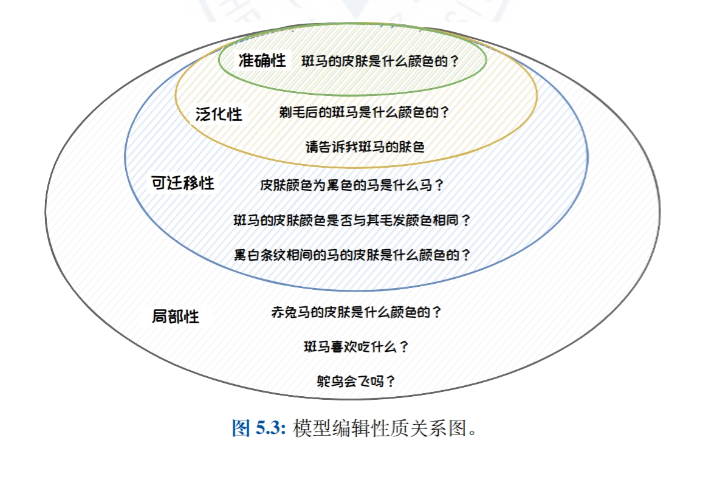
Model editing
- Introduction to Model Editing: Introduces the idea, definition, and nature of model editing and details the importance of model editing in correcting bias, toxicity, and knowledge errors in large language models.
- Classical approach to model editing: Categorize model editing methods into external expansion methods (e.g., knowledge caching and additional parameter methods) and internal modification methods (e.g., meta-learning and localization editing methods), presenting representative work on each type of method.
- Additional Parameter Method: T-Patcher: The T-Patcher method is described in detail, which achieves precise control of model output by attaching specific parameters to the model, and is suitable for scenarios that require fast and precise correction of specific knowledge points in the model.
- Location editing method: ROME: A detailed introduction to the ROME method, which achieves precise control of model outputs by locating and modifying specific layers or neurons within the model, and is suitable for scenarios requiring deep modification of the model's internal knowledge structure.
- Model editing applications: Introduces the practical applications of model editing in accurate model updating, protecting the right to be forgotten and enhancing model security, and demonstrates the application potential of model editing technology in different scenarios.
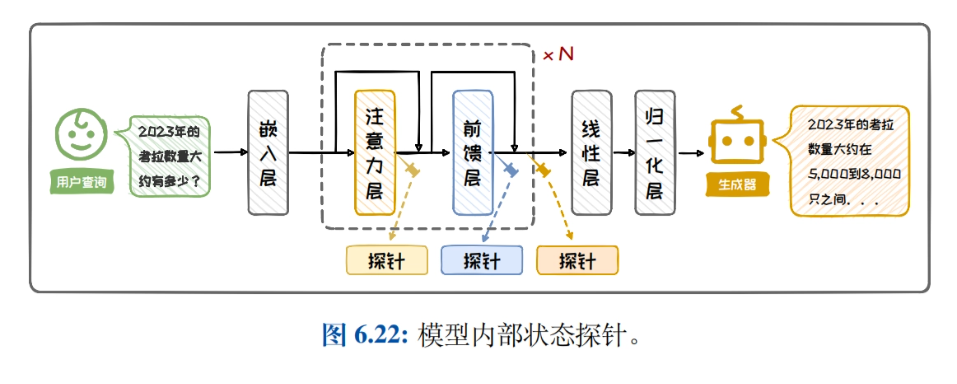
Search Enhanced Generation
- Retrieval Enhancement Generation Profile: Introduces the background and components of retrieval-enhanced generation, and details the importance and application scenarios of improving model performance by combining retrieval and generation in natural language processing tasks.
- Retrieving Enhanced Generation Architecture: Introduces RAG architecture classification, black-box enhancement architecture and white-box enhancement architecture, and comparatively analyzes the characteristics and applicable scenarios of different architectures to help readers choose the right architecture.
- knowledge retrieval: Details the methods of knowledge base construction, query enhancement, searchers and retrieval efficiency enhancement, and discusses how to improve retrieval effectiveness and optimize the knowledge retrieval process through search result rearrangement.
- Generation Enhancement: Introduces when to enhance, where to enhance, multiple enhancements, and cost reduction methods, and discusses strategies for applying generative enhancement to different tasks to improve the quality and efficiency of generated text.
- Practice and Application: Introduces the steps to build a simple RAG system, shows examples of RAG in typical applications, and helps readers understand and apply retrieval-enhanced generation techniques to improve the performance of models in real-world tasks.
Resource material download address
The Fundamentals of Large Models report is available for download at: https://url23.ctfile.com/f/65258023-8434020435-605e6e?p=8894 (Access code: 8894)
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...