FG-CLIP 2 - 360 Open Source Cross-Modal Visual Language Model for Graphic Texts

What is FG-CLIP 2
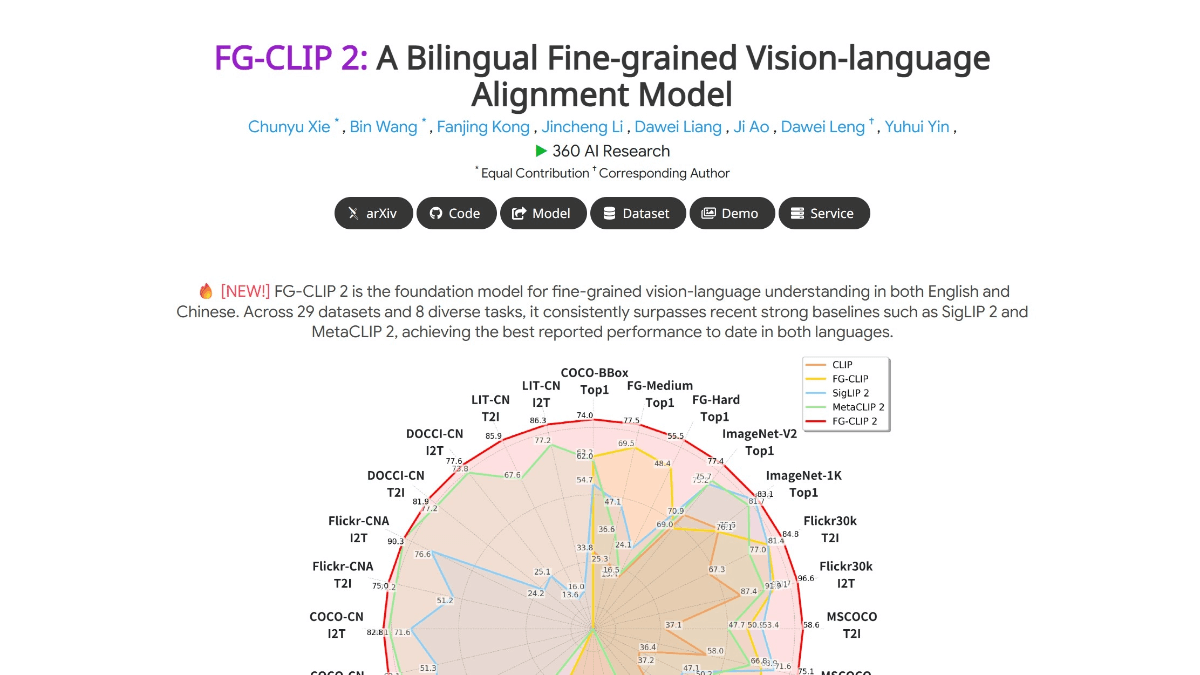
FG-CLIP 2 is the world's leading graphical cross-modal visual language model (VL-M) launched by 360 AI Research Institute, which has surpassed similar models from Google and Meta in 29 authoritative benchmarks, making it the most powerful VL-M at present. it can accurately recognize details such as hairs, spots, colors, expressions, and spatial relationships in an image, for example, distinguishing between different breeds of cats, determine the position of objects inside and outside the screen, and even understand the occlusion relationship in complex scenes. It also supports fine-grained understanding of Chinese and English, filling the gap of Chinese cross-modal modeling, and can accurately handle tasks such as Chinese long text retrieval and region classification. It adopts a two-stage training strategy, first globally aligning the graphic semantics, then focusing on local detail alignment; combined with a five-dimensional collaborative optimization system, it improves the model's anti-interference and robustness.
Functional features of FG-CLIP 2
- Bilingual support: Can handle both English and Chinese tasks, enabling true bilingual native support.
- Fine-grained understanding: Accurately recognizing details in an image, such as attributes of objects, spatial relationships, etc., to improve the accuracy of visual language alignment.
- Dynamic attention: Intelligently focuses on key areas of an image to effectively handle complex visual scenes.
- Hierarchical Alignment: Combine macro-scenarios and micro-details to progressively improve model understanding.
- Optimizing bilingual synergies: Balancing English and Chinese comprehension to improve overall performance in bilingual tasks.
- High Concurrency Response: Support fast response in high concurrency scenarios to ensure real-time and efficiency.
- Adaptive Input: Dynamically adjusts the resolution to accommodate input images of different sizes.
- Rich Open Source Resources: Full code, model weights, and training datasets are provided to facilitate research and development.
Core Benefits of FG-CLIP 2
- Pixel-level fine-grained understanding: It can accurately recognize details such as hairs, spots, colors, expressions, and spatial relationships in images, such as distinguishing between different breeds of cats, determining the position of objects on and off the screen, and even understanding occlusion relationships in complex scenes.
- Bilingual skills in English and Chinese: It supports fine-grained understanding of Chinese and English, fills the gap of Chinese cross-modal modeling, and can accurately handle tasks such as Chinese long text retrieval and region classification.
- Innovative training methods: A two-stage training strategy is adopted to globally align the graphic semantics first, and then focus on local detail alignment; combined with a five-dimensional collaborative optimization system to improve the model's anti-interference and robustness.
- High-quality data sets: Based on the self-developed FineHard dataset, it contains billions of pairs of Chinese and English graphic samples, as well as ten million local area labeling and hard-to-negative samples, ensuring the model's accurate capture of details.
- Dynamic Attention Mechanism: Intelligent focusing on key regions of an image improves the model's ability to process complex visual tasks.
- Hierarchical Alignment Architecture: Combining macro-scenes and micro-details to gradually improve model comprehension and enhance visual and verbal alignment accuracy.
- Optimized bilingual synergy strategies: Balancing English and Chinese comprehension to address performance imbalances in bilingual tasks.
- High Concurrent Response Speed: Explicit twin-tower structure is used to support fast response in high concurrency scenarios, ensuring real-time performance and efficiency.
- Adaptive input size: The dynamic resolution mechanism allows the model to adaptively handle inputs of different sizes, enhancing flexibility and adaptability.
What is the official website for FG-CLIP 2
- Project website:: https://360cvgroup.github.io/FG-CLIP/
- Github repository:: https://github.com/360CVGroup/FG-CLIP
- arXiv Technical Paper:: https://arxiv.org/pdf/2510.10921
People for whom FG-CLIP 2 is intended
- Home Robotics Developer: Needed to enable robots to understand complex commands in the home environment, FG-CLIP 2's fine-grained visual language understanding capability can significantly enhance the robot interaction experience.
- Security Systems Engineer: In the field of security surveillance, FG-CLIP 2 can quickly and accurately identify and locate targets, improving the efficiency and reliability of security systems.
- E-commerce Technology Team: FG-CLIP 2 can optimize the product search and recommendation functions, improve user experience, reduce the cost of multi-language adaptation, suitable for technical teams of e-commerce platforms.
- Autonomous Driving Developer: In an autonomous driving system, FG-CLIP 2 accurately recognizes objects and scenes in the road environment, enhancing the safety and reliability of the system.
- Medical Imaging Analyst: The FG-CLIP 2 can assist doctors in image diagnosis and improve the accuracy and efficiency of diagnosis, suitable for professionals in the field of medical image analysis.
- Educational technology developers: When developing intelligent educational tools, FG-CLIP 2 can enrich the content and form of teaching by providing relevant knowledge based on the content of pictures.
- Content Creation Team: In image editing and video production, the FG-CLIP 2 can quickly find suitable footage based on text descriptions, increasing creative efficiency.
- Intelligent Customer Service System Developer: FG-CLIP 2 understands the content of pictures uploaded by users, provides more accurate answers and suggestions, and improves the quality of customer service.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...