
FastVLM - Visual Language Model from Apple

What is FastVLM
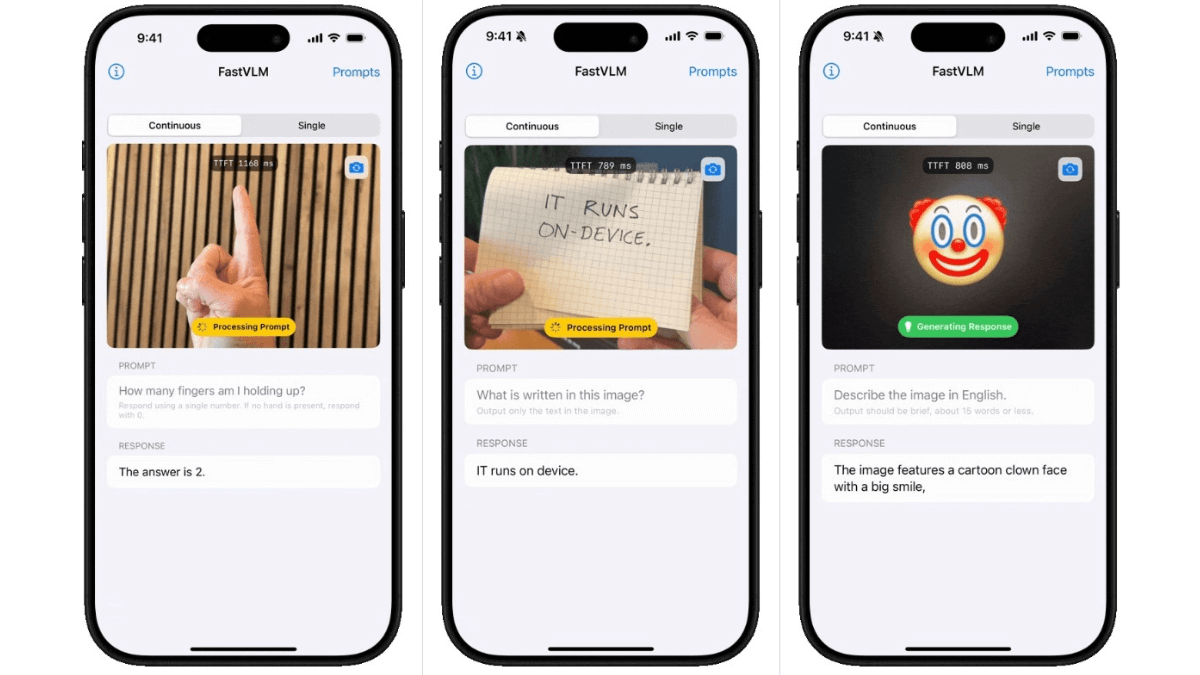
FastVLM (Fast Vision Language Model) is an efficient visual language model introduced by Apple. With FastViTHD hybrid visual encoder as the core, it incorporates convolutional and Transformer architectures to significantly reduce the number of visual tokens, encoding time and latency. When processing high-resolution images, the encoding speed is 85 times faster than comparable models, the time to first token generation (TTFT) is improved by 3.2 times, and the size of the visual encoder is smaller, making it easy to deploy on mobile devices.
Features of FastVLM
- Efficient visual processing: FastVLM dramatically reduces the number of visual tokens and significantly improves the processing speed of visual information through a hybrid visual coder that combines convolutional and Transformer architectures, and especially excels in high-resolution image processing.
- Low Latency Interaction: The first token generation time of the model is significantly shortened, and it can quickly respond to user inputs, which is suitable for real-time interaction scenarios, such as mobile graphical Q&A assistants, to provide instant feedback to users.
- Lightweight design: The significantly reduced size of the vision encoder facilitates deployment on mobile and edge intelligence devices, reduces hardware requirements, and improves model portability and application range.
- high accuracy: In several benchmark tests, FastVLM's performance is comparable to that of larger models, and its ability to accurately understand and generate image-related content ensures the model's utility.
- Simplified Architecture: Balancing the number of tokens and resolution is achieved only by adjusting the input image size without additional token pruning, which simplifies the model design and reduces the complexity of development and deployment.
FastVLM's Core Benefits
- Efficient Processing Capability: FastVLM employs a hybrid visual coder that combines convolutional and Transformer architectures to significantly reduce the number of visual tokens and improve coding efficiency, especially in high-resolution image processing, where coding speed is up to 85 times faster than comparable models.
- Low latency response: The time to first token generation (TTFT) is dramatically shortened, and the response speed is fast, which is suitable for real-time interaction scenarios, such as mobile graphic Q&A assistants, which are able to give answers quickly.
- Lightweight design: The significantly reduced size of the vision encoder, which is 3.4 times smaller than comparable models, facilitates deployment on mobile and edge smart devices, reduces hardware requirements, and improves model portability.
- high accuracy: In several benchmark tests, FastVLM's performance is comparable to that of larger models, and its ability to accurately understand and generate image-related content ensures the model's utility.
- Simplified design: Balancing the number of tokens and resolution is achieved only by adjusting the input image size without additional token pruning, which simplifies the model design and reduces the complexity of development and deployment.
What is FastVLM's official website?
- GitHub repository:: https://github.com/apple/ml-fastvlm
- HuggingFace Model Library:: https://huggingface.co/collections/apple/fastvlm-68ac97b9cd5cacefdd04872e
- arXiv Technical Paper:: https://www.arxiv.org/pdf/2412.13303
Who FastVLM is for
- Mobile device users: FastVLM is suitable for users with smartphones or tablets who need quick access to image-related information, such as students, travelers and commuters.
- Smart Wearables UsersFor those using smart glasses or other wearable devices, FastVLM can provide real-time scene alerts and information assistance to enhance the user experience.
- Educators and students: In the field of education, FastVLM can help teachers and students quickly acquire knowledge through image quizzes to assist teaching and learning.
- Company employees: In office scenarios, FastVLM can help employees quickly process text and data in images to improve work efficiency for those who need to work on the move.
- Technology Developer: For developers working on mobile applications or smart devices, FastVLM provides an efficient, lightweight visual language model that can be used to build a variety of smart interaction features.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...