
Doubao-1.5-pro Released: A New Multimodal Base Model for Extreme Balance

Doubao-1.5-pro
🌟 Model profile
Doubao-1.5-pro is a highly sparse MoE ArchitectureIn the four quadrants of Prefill/Decode and Attention/FFN, the computation and access characteristics are significantly different. For the four different quadrants, we adopt heterogeneous hardware combined with different low-precision optimization strategies to significantly increase throughput while ensuring low latency, and reduce the total cost while taking into account the optimization goals of TTFT and TPOT, achieving the ultimate balance between performance and inference efficiency.
- minor activation parameter: exceeds the performance of the very large dense model.
- Multi-scene adaptation: Outperforms on multiple review benchmarks.
📊 Performance Evaluation
Doubao-1.5-pro results on multiple benchmarks
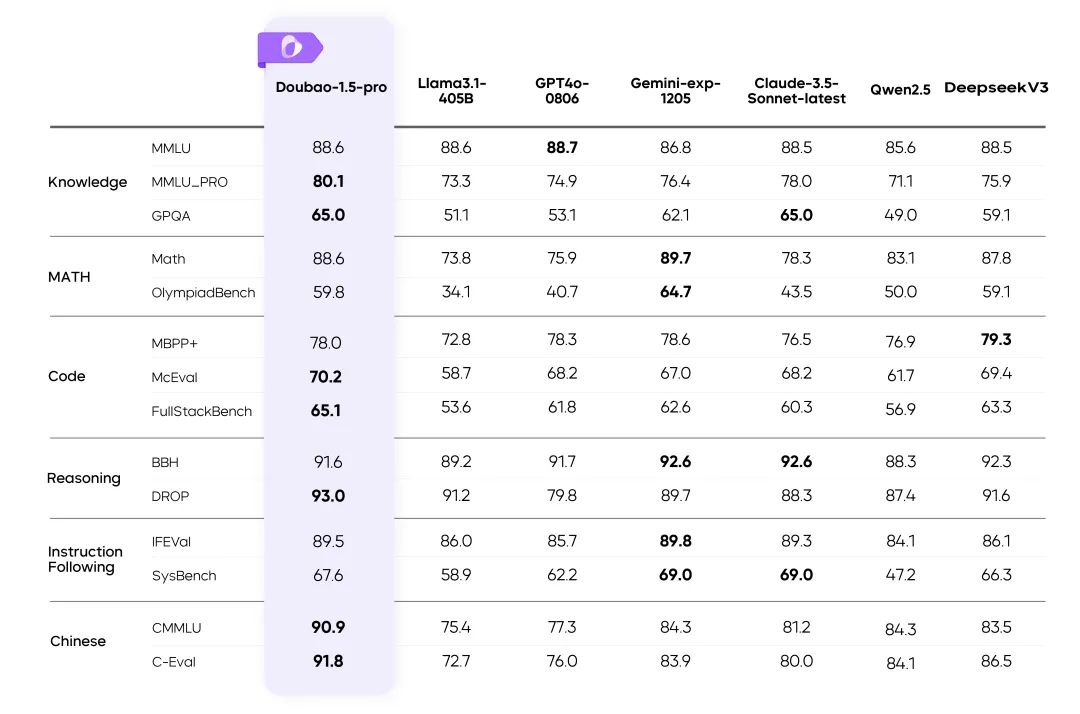
clarification::
- The metrics for the rest of the models in the table are taken from the official results, and the unpublished parts are done by internal evaluation platforms.
- GPT4o-0806 Excellent performance in public reviews of language models, see: simple-evals.
⚙️ Balancing Performance and Reasoning
Efficient MoE Architecture
- utilization Sparse MoE Architecture Achieving dual optimization of training and reasoning efficiency.
- Research highlights: Determine the optimal balance ratio between performance and efficiency by means of the sparsity Scaling Law.
Training Loss vs.

Model Performance Comparison
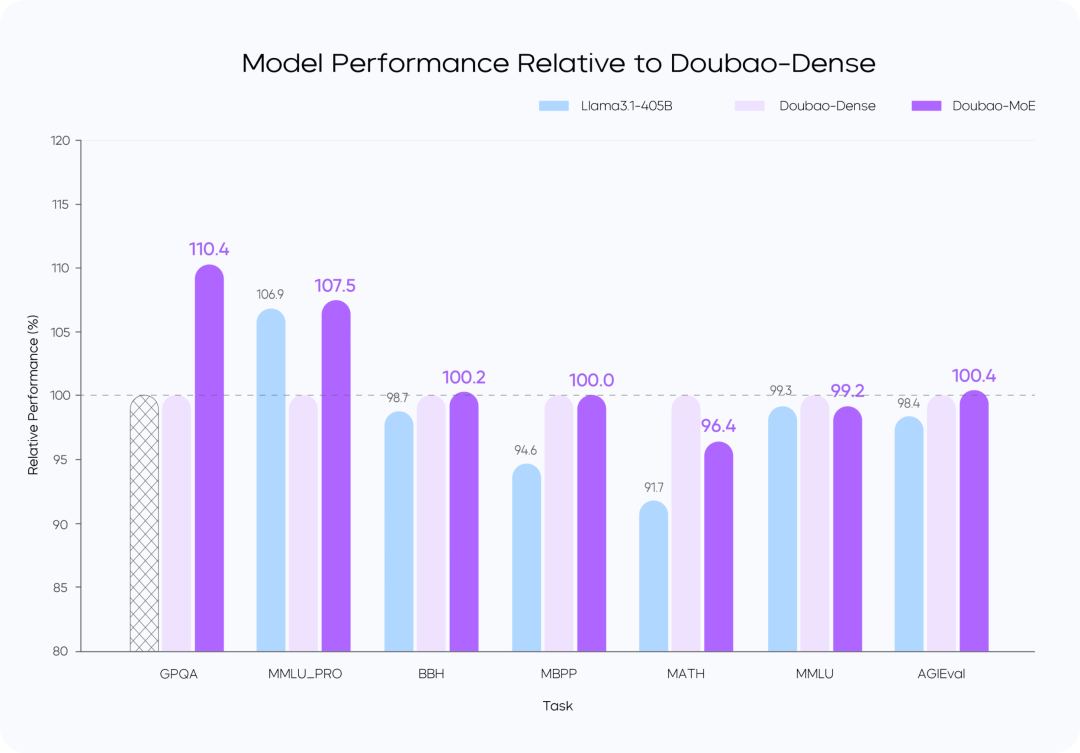
clarification::
- The Doubao-MoE model outperforms a dense model with 7 times the number of activated parameters (Doubao-Dense).
- Doubao Dense model training is more efficient than Llama 3.1-405B, data quality and superparameter optimization are key.
🚀 High performance reasoning
Computational and access feature optimization
Doubao-1.5-pro performs well in four computational quadrants: Prefill, Decode, Attention, and FFN.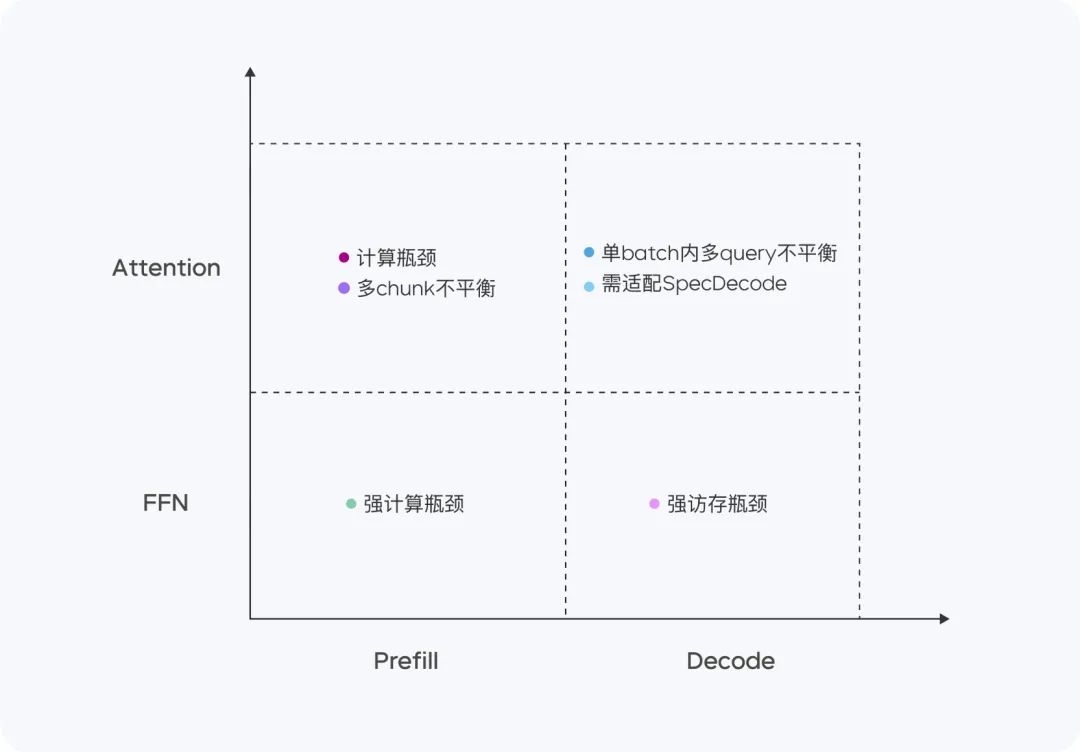
In the Prefill phase, the communication and access bottleneck is not obvious, but the computation bottleneck is easily reached. Considering the characteristics of LLM one-way attention, we do Chunk-PP Prefill Serving on a variety of devices with high compute-visit-to-deposit ratios, so that the utilization rate of the Tensor Core of the online system is close to 60%.
- Prefill Attention: Extends the open source FlashAttention 8-bit implementation with instructions such as MMA/WGMMA, combined with Per N tokens Per Sequence quantization strategy ensures that this phase can run losslessly on GPUs of different architectures. Meanwhile, by modeling the Attention consumption of slices of different lengths and combining with the dynamic cross-query batching strategy, it realizes inter-card balancing during Chunk-PP Serving, effectively eliminating the empty running caused by load imbalance;
- Prefill FFN: Adopting W4A8 quantization effectively reduces the access overhead of sparse MoE experts, and gives more inputs to the FFN stage through the cross-query Batching strategy, which improves the MFU to 0.8.
In the Decode phase, the computational bottleneck is not obvious, but the communication and memory requirements are relatively high. We use Serving, a device with lower computation and access memory, to obtain higher ROI, and at the same time, we use very low-cost sampling and Speculative Decoding strategy to reduce the TPOT metrics.
- Decode Attention: TP is deployed to optimize the common scenario of large differences in KV lengths among different Queries within a single batch by means of heuristic search and aggressive long sentence splitting strategy; in terms of accuracy, Per N tokens Per Sequence quantization is still adopted; in addition, the Attention computation during random sampling is optimized to ensure that the KV Cache is accessed only once. In addition, we optimize the Attention calculation during the random sampling process to ensure that the KV Cache is only accessed once.
- Decode FFN: Keep W4A8 quantized and deployed using EP.
Overall, we have implemented the following optimizations on the PD separated Serving system:
- Customized RPC Backend for Tensor transfer, and optimized Tensor transfer efficiency on TCP/RDMA network by means of zero-copy, multi-stream parallelism, etc., which in turn improves KV Cache transfer efficiency under PD separation.
- It supports flexible allocation and dynamic expansion and contraction of Prefill and Decode clusters, and does HPA elastic expansion for each role independently, so as to ensure that both Prefill and Decode have no redundant arithmetic power, and the arithmetic power allocation of the two sides is in line with the actual online traffic pattern.
- In the framework of the GPU computing and CPU pre- and post-processing asynchronization, so that the GPU reasoning the Nth step when the CPU launched the N + 1 step Kernel in advance, to keep the GPU is always full, the entire framework processing action of the GPU reasoning zero overhead. In addition, with our self-developed server cluster solution, we flexibly support low-cost chips, and the hardware cost is significantly lower than the industry solution. We have also significantly optimized the efficiency of packet communication through customized network cards and self-developed network protocols. At the arithmetic level, we realize the efficient overlap (Overlap) between computation and communication, thus ensuring the stability and efficiency of multi-computer distributed reasoning.
🎯 Data labeling: no shortcuts
- Build an efficient data production system that combines Labeling Team cap (a poem) Model Self-Lifting Technology, significantly improving the quality of the data.
🖼️ Multimodal Capabilities
Visual Multimodality: Complex Scenes Handled with Ease
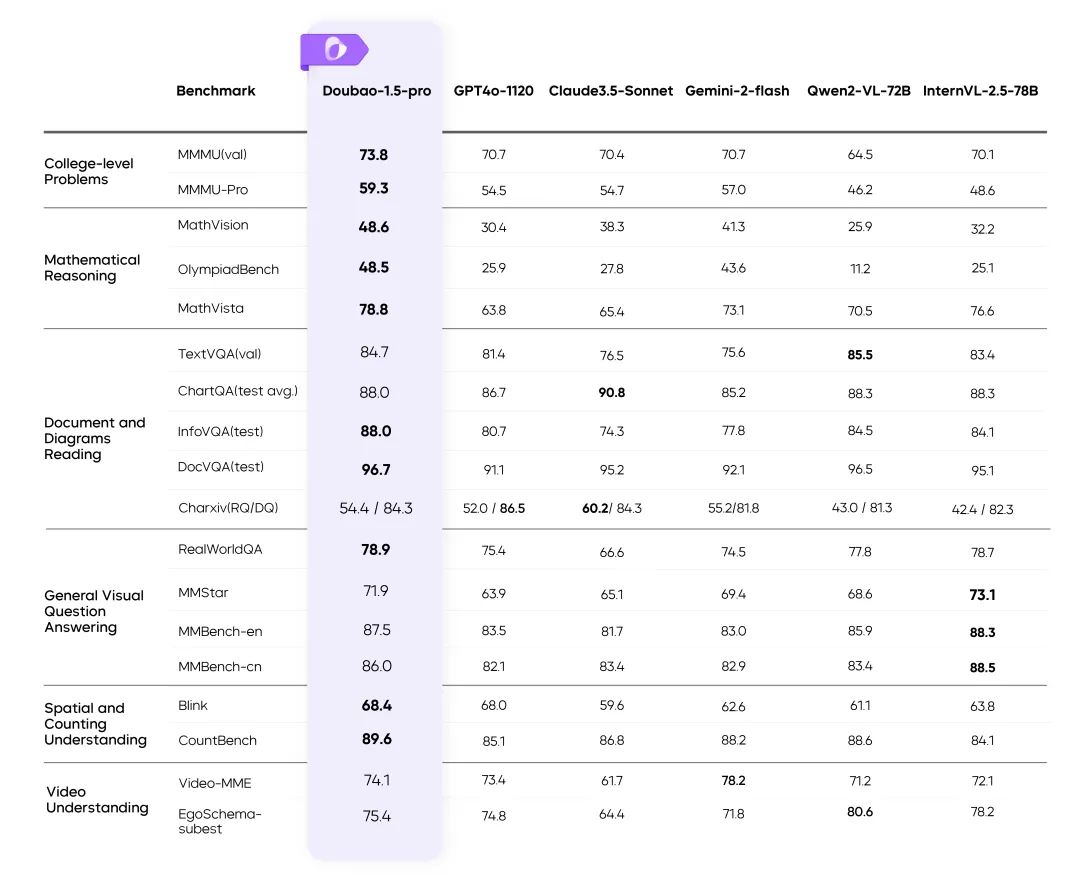
Dynamic Resolution Training: Throughput Enhancement 60%
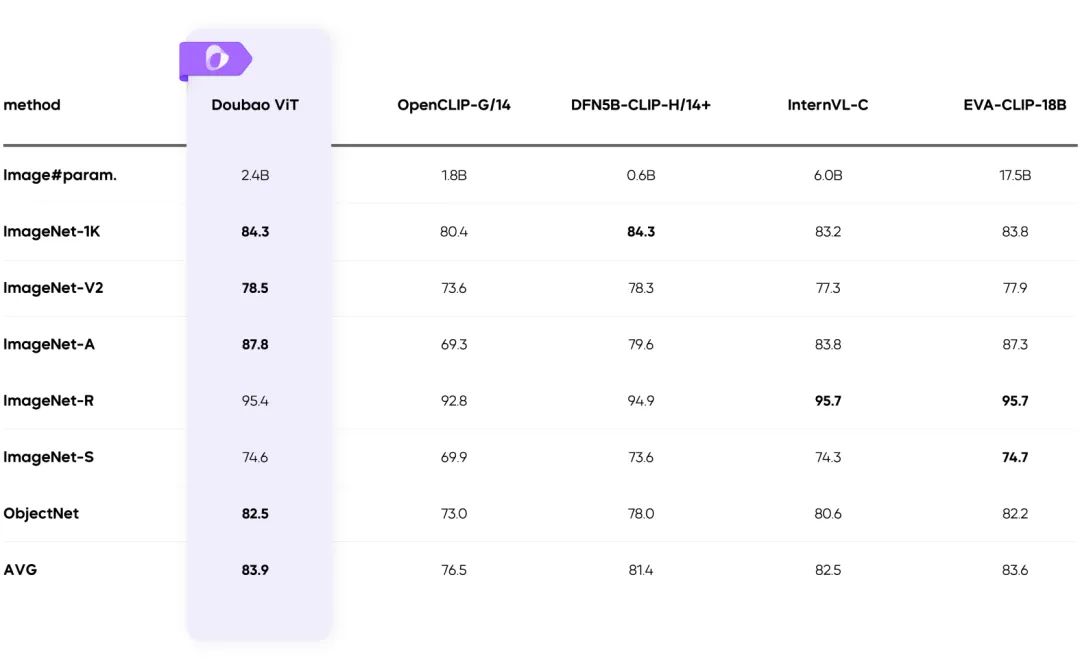
- Solve the problem of uneven load of visual encoder, and improve the efficiency significantly.
✅ Summary
Doubao-1.5-pro finds the optimal balance between high performance and low inference cost, and makes breakthroughs in multimodal scenarios:
- Innovative sparse architecture design.
- High quality training data and optimization system.
- Driving a new benchmark in multimodal technology.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...