
dots.ocr - the open source multilingual document parsing model launched by the Little Red Book hi lab

What is dots.ocr
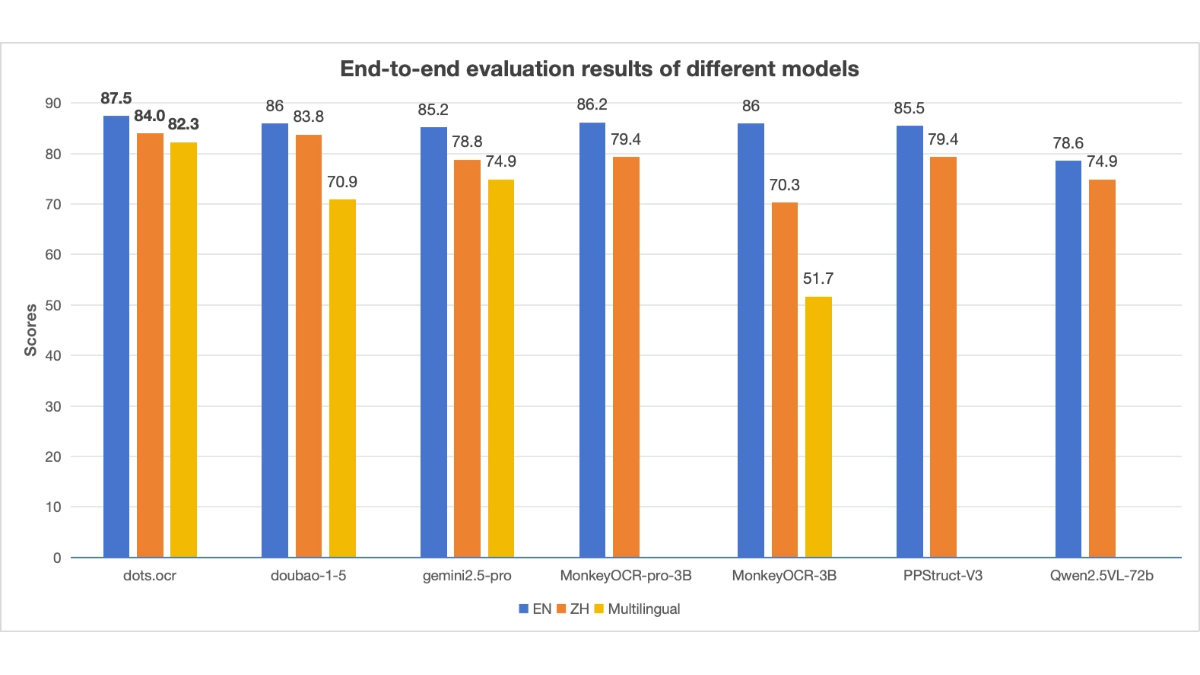
dots.ocr is a multilingual document parsing model open-sourced by Little Red Book hi lab, based on a 1.7 billion-parameter Visual Language Model (VLM), which can efficiently perform document layout detection and content recognition while maintaining a good reading order. dots.ocr supports multiple languages, parses text, tables, formulas, and images, and other elements, and has fast reasoning speeds and industry-leading performance! . The model can flexibly respond to different document parsing tasks by simply switching between input prompts and outputs in a variety of formats, including JSON and Markdown. dots.ocr excels in parsing small languages and recognizing formulas, and is suitable for a variety of scenarios, such as academic research, financial document processing, and parsing of educational materials.
Main functions of dots.ocr
- Multi-language support and diverse content analysis: dots.ocr handles documents in multiple languages and accurately parses text, tables, formulas, images and other elements to meet the content extraction needs of different scenarios.
- Unified layout and content handling: The model integrates layout detection and content recognition of documents into one, which can automatically identify different regions and maintain a reasonable reading order, avoiding the problem of separating layout and content in traditional methods.
- Efficient reasoning and large-scale processing capabilitiesThe visual language model is based on 1.7 billion parameters, and the model inference is fast, suitable for large-scale document processing, and can effectively cope with the parsing needs of a large number of documents.
- Flexible task switching: Easily switch between different tasks, such as layout detection, content recognition, formula parsing, etc., based on simple input prompt words, without complex model tuning.
- Versatile output formatsIt supports various output formats such as JSON, Markdown, etc. It provides layout visualization images, which is convenient for users to follow up the process according to their needs.
- Advantages of Small Language Analysis: The model performs well in parsing small-language documents and can accurately process small-language content to meet the needs of parsing documents in multilingual environments.
The official website address of dots.ocr
- GitHub repository:: https://github.com/rednote-hilab/dots.ocr
- HuggingFace Model Library:: https://huggingface.co/rednote-hilab/dots.ocr
- Online Experience Demo:: https://dotsocr.xiaohongshu.com/
How to use dots.ocr
- Visit the online experience: Visit dots.ocr for the Demo Experience address.
- Upload a document: Click the "Upload File" button and select the PDF or image file you want to parse.
- Select a task: Select tasks according to needs, such as layout detection, content recognition, formula parsing or table extraction.
- Start parsing: Click the "Start Parsing" button and the model will automatically process the document.
- View Results: After parsing is complete, select a different output format.
- Download or copy the results: Click the "Download" or "Copy" button to save or use the results.
Core benefits of dots.ocr
- High Performance and Small Model AdvantageThe number of model parameters is only 1.7 billion, with industry-leading performance, fast inference speed and low resource consumption.
- Multilingualism and small language expertise: support for a variety of mainstream languages, and in the small language document parsing performance is excellent, applicable to a wide range.
- Flexible task adaptation: Switching between different tasks by simply typing in the cue word is adaptable without retraining or adjusting the model architecture.
- Unified layout and content handling:Integrating layout detection and content recognition into a single model avoids the problem of separating layout and content in traditional methods and ensures the coherence of parsing results.
- Diverse output and visualization: Supports multiple output formats and provides layout visualization images for easy intuitive understanding and subsequent processing.
- Open Source and Community Support: Open source code and detailed documentation support for easy secondary development and customization by developers and active community.
People for whom dots.ocr is intended
- Researchers and scholars: dots.ocr quickly parses formulas and diagrams in academic literature, helping researchers efficiently access key information and accelerate academic research.
- Financial industry practitioners: Financial analysts and compliance officers automate the extraction of data and tables from financial reports, improving the efficiency of financial data analysis and compliance checks.
- Educators and students: Teachers and students use dots.ocr to parse textbooks and test papers to support teaching and learning, and to promote education informatization.
- In-house document managers: Business executives and project managers process meeting minutes and project reports, extract key information, and optimize document management processes.
- Developers and technical missionsTeam: Developers integrate models into applications to realize document parsing functionality and meet diverse development needs.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...