DINOv3 - Next Generation Self-Supervised Vision Base Model from Meta AI

What is DINOv3?
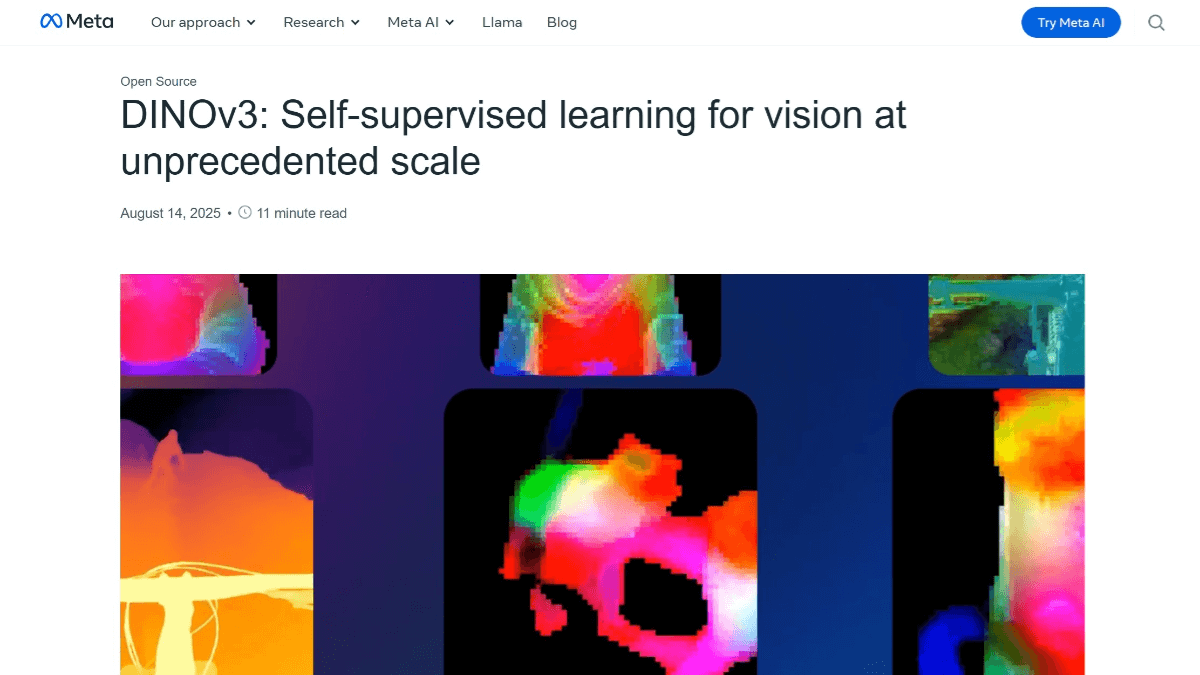
DINOv3 Yes Meta AI DINOv3 is a new generation of self-supervised vision base model, which adopts self-supervised learning paradigm to learn image features without labeling data. By improving data preparation and introducing Gram anchoring, the feature degradation problem is solved and the generalization ability is enhanced.DINOv3 provides two backbone network architectures, ViT and ConvNeXt, of which ViT-7B is the largest version at present, containing 6.7 billion parameters. The model can generate high-quality dense feature representations that accurately capture the local relationships and spatial information of images. It performs well in a wide range of visual tasks such as image classification, target detection, semantic segmentation, etc., and can outperform many professional models without task-specific fine-tuning.DINOv3 supports high-resolution feature extraction, which is suitable for medical image analysis, environmental monitoring and other scenarios that require high-precision features.
Features of DINOv3
- Self-supervised learning capability: Learning image features without labeling data, solving the feature degradation problem in long-term training by improving data preparation and introducing Gram anchoring, and improving the generalization ability of the model.
- Multiple backbone network architectures: Two backbone network architectures, ViT and ConvNeXt, are available to meet different computing needs, with ViT-7B being the largest version to date, containing 6.7 billion parameters.
- High-quality feature representation: It can generate high-quality dense feature representations that accurately capture the local relationships and spatial information of images for a wide range of visual tasks.
- Multitasking versatility: It excels in tasks such as image classification, target detection, and semantic segmentation, outperforming many specialized models without task-specific fine-tuning and significantly reducing inference costs.
- High Resolution Feature Extraction: Supports high-resolution feature extraction for scenarios that require high-precision features, such as medical image analysis and environmental monitoring.
Core Benefits of DINOv3
- Powerful self-supervised learning: It does not require a large amount of labeled data, achieves efficient learning through an innovative self-supervision mechanism, solves the feature degradation problem, and improves the model generalization ability.
- Flexible Architecture OptionsViT and ConvNeXt backbone network architectures are available to meet different computing resources and task requirements, balancing performance and efficiency.
- High-quality feature representation: The generated features accurately capture image local relationships and spatial information, and are suitable for a wide range of visual tasks with excellent performance.
- Multitasking versatility: Outperform professional models without specific fine-tuning in tasks such as image classification, target detection, semantic segmentation, etc., reducing development costs.
- High Resolution Feature Extraction: Supports high-resolution feature extraction, which is suitable for medical image analysis, environmental monitoring and other scenarios that require high precision.
- Open Source and Ease of UseThe code and models are open source, and support Hugging Face Hub and Transformers libraries, making it easy to get started and develop applications quickly.
What is DINOv3's official website?
- Project website:: https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- HuggingFace Model Library:: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- Technical Papers:: https://ai.meta.com/research/publications/dinov3/
People for whom DINOv3 is intended
- Computer vision researchers: DINOv3 provides powerful self-supervised learning capabilities and high-quality feature representations suitable for professionals engaged in research on visual tasks such as image classification, target detection, semantic segmentation, and so on.
- Deep Learning Developers: Open source code and pre-trained models make DINOv3 ideal for deep learning developers to rapidly build and deploy vision applications for scenarios that require efficient development and optimization.
- Medical Imaging Specialist: High-resolution feature extraction capability has great potential in the field of medical image analysis for medical diagnostic tasks that require high-precision features, such as X-ray, CT and MRI analysis.
- Environmental Monitoring and Geographic Information Systems (GIS) Practitioners: DINOv3 can be used for satellite image analysis, deforestation monitoring and other environmental monitoring tasks, providing technical support for GIS-related work.
- Robot Vision Engineer: DINOv3's high-precision vision features and multi-task versatility make it ideal for robotic vision systems for visual perception tasks in complex environments such as Mars exploration robots.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...