DeepSeek: ignored by the media

Guest contributors Lennart Heim and Sihao Huang, this article is cross-posted on Lennart's blog, Lennart is a regular contributor to ChinaTalk and recently participated in a discussion on geopolitics in the era of time-tested computing, and Sihao has previously written about Beijing's vision for global AI governance.
Recent reports on DeepSeek Reports of AI models have focused primarily on their superior performance in benchmarking and efficiency gains. While these achievements deserve recognition and have policy implications (see below for more details), the reality of access to computing resources, export controls, and AI development is more complex than many reports present. Here are a few key points of interest:
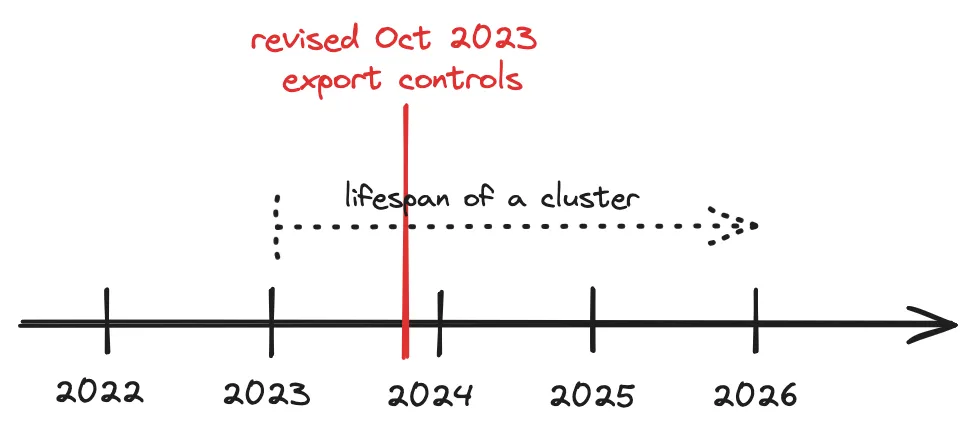
- The real export restrictions for AI chips begin in October 2023, and current claims about their ineffectiveness are premature. DeepSeek was trained using the Nvidia H800, a chip designed to circumvent the initial October 2022 limit. For DeepSeek's computational tasks, the performance of these chips is comparable to the H100 available in the United States. Nvidia's latest H20 - an AI chip still available for export to China - is weaker on the training side, but still powerful on the deployment side.
Despite its limitations in training, H20 remains unrestricted and robust in cutting-edge AI deployments, especially memory-intensive tasks such as long contextual reasoning. This is critical, especially with trends such as compute-on-test, synthetic data generation, and reinforcement learning, processes that rely more on memory than compute power. As restrictions on high-bandwidth memory (HBM) exports come into effect in December 2024, the continued availability of H20 is worth watching, especially in the context of AI compute demand increasingly skewed toward the deployment side. - Hardware export controls have a time lag effect and are not yet fully effective.
Note that all this assumes that export controls are perfectly enforced, which is not the case. Semiconductor controls have a large number of loopholes and there is credible evidence of large-scale chip transfers. While the Diffusion Framework may help to close some of these loopholes, enforcement remains the key challenge. [JS: Of course, access problems remain in the Western cloud ......]China is still using data centers built before export restrictions that contain tens of thousands of chips, while U.S. companies are building data centers containing hundreds of thousands of chips. The real test will come when these data centers need to be upgraded or expanded - a process that is easier for U.S. firms but will be challenging for Chinese firms subject to export controls. If 100,000 chips are needed to train the next generation of models, export controls will significantly impact cutting-edge model development in China. However, even without such large-scale training requirements, export controls will have a profound impact on China's AI ecosystem by reducing deployment capacity, limiting enterprise development, and inhibiting the ability to synthesize training data and self-game.
- It's no surprise that DeepSeek V3 completes its training with fewer computational resources; the cost of machine learning algorithms has been declining over time. But the same efficiency gains that enable small businesses like DeepSeek to access AI capabilities (i.e. "accessibility effect"), and may also allow other organizations to build more powerful systems on larger compute clusters (i.e., "performance effect"). Thankfully, DeepSeek trained V3 using only 2,000 H800s instead of 200,000 B200s (Nvidia's latest generation chip).

- The timing of the release has strategic considerations, but the technical prowess is real. The release of the R1 coincides with President Trump's inauguration last week, and is clearly designed to undermine public confidence in America's AI leadership at a critical time for U.S. policy. It's the same strategy Huawei used to launch its new product during former Commerce Secretary Raimondo's visit to China. After all, the R1 Preview's benchmark results were made public back in November.
This careful PR timing should not obscure two facts: the technological advances DeepSeek has made, and the structural challenges they face now and in the future due to export controls. - Export controls are difficult to accurately affect a single training task, but they can effectively curb the development of an entire AI ecosystem. In particular, limitations on state-of-the-art chips can effectively constrain large-scale AI deployments (i.e., making AI services accessible to a large number of users) and capability enhancements. AI companies typically dedicate 60-80% of compute resources to deployments-even before the rise of compute-intensive reasoning models. Limiting compute resources will increase the cost of Chinese AI, cripple its ability to deploy at scale, and limit system performance. It's worth noting that deployment compute is not just about user access; it also plays a key role in generating synthetic training data, facilitating capability improvements through model interactions, and building, scaling, and optimizing models.
For example, Gwern's recent comments point out that deployment computing plays a key role in AI development far beyond user access. Models like OpenAI's o1 can be used to generate high-quality training data, which creates a feedback loop in which deployment capabilities directly drive development capabilities and overall performance improvements. - DeepSeek's efficiency gains may stem from the massive arithmetic support it previously received. At first glance, the path to reducing chip usage (i.e., "increasing efficiency") may seem to start with having a lot of computing power. deepSeek operates Asia's first 10,000-chip A100 cluster and reportedly maintains a 50,000-chip H800 cluster, as well as unlimited access to cloud service providers (export-controlled) in China and abroad. service providers in China and abroad (not subject to export controls). This broad access to computing power is critical to its development of efficient technologies through iterative testing and to the delivery of model services to its customers.
Recently, other AI companies have seen spikes in usage that have caused service outages even when supported by greater computing power.Whether DeepSeek can cope with similar spikes is still untested, and they will be challenged to do so with limited computing power. (Sam Altman even claims that ChatGPT Pro subscription program is currently losing money.)
While their R1 model demonstrated excellent efficiency, its development process relied on a great deal of arithmetic for synthetic data generation, distillation, and experimentation. - Export controls have further exacerbated the U.S.-China arithmetic gap, which remains a major limitation for DeepSeek, whose leadership has publicly acknowledged that even with improved efficiency, they still face a 4x arithmetic disadvantage. This means we need twice the computing power to achieve the same results," said Wenfeng Liang, founder of DeepSeek. There is also about a 2x gap in data efficiency, which means we need 2x the training data and computing power to achieve comparable results. Taken together, this requires 4x the computing power." He added: "We have no financing plans in the short term. Our problem has never been funding, but the embargo on high-end chips."
- Leading U.S. AI companies keep their strongest capabilities under wraps, which means that public benchmarking does not accurately reflect the full picture of AI development. Chinese companies tend to share progress publicly, while Anthropic and OpenAI, among others, retain a great deal of private capabilities. As a result, direct comparisons based on publicly available information are incomplete.DeepSeek has received attention in part because of its openness-they share model weights and methodologies in detail, which contrasts with the trend of Western companies to be increasingly closed. However, it remains to be seen whether openness necessarily leads to strategic advantage.
So, what does that mean?
DeepSeek's achievements are real and important. It is inaccurate to dismiss their progress as simply propaganda. Their reported training costs are not unprecedented, and historical trends in algorithmic efficiency support this. However, comparisons need to be carefully considered in context - DeepSeek only reports final pre-training run costs, ignoring key expenses such as staffing costs, up-front experiments, data acquisition, and infrastructure development. For more details on the misleading comparisons that can result from different costing methods, see this article.
Increasing arithmetic efficiency means that AI capabilities will eventually proliferate. Controls alone are not enough; complementary measures are needed to enhance society's resilience and defenses, establish institutions capable of identifying, evaluating, and responding to AI risks, and build a sturdy defense system against potential AI threats from adversaries. However, we should also recognize that export controls have already had an impact on China's AI development and could have an even stronger effect in the future.
The model itself may not be what many consider a "strategic moat," but the impact of arithmetic power on national security varies by application scenario. For applications that require large-scale deployments (e.g., mass surveillance), capacity constraints can be a significant barrier. For single-user applications, on the other hand, the impact of regulation is less significant. The relationship between arithmetic availability and national security capabilities remains complex, although the modeled capabilities themselves are becoming easier to replicate.
While AI capabilities may proliferate despite controls, and stopping proliferation altogether will always be difficult, these controls remain critical to maintaining technological advantage. Controls buy valuable time, but complementary policies are still needed to ensure that democracies stay ahead of the curve and are able to fend off challenges from potential rivals.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...