
DeepSeek-V3 Model Low-Profile Update, Code Capability Jumps to Claude-3.7

Competition in the tech sector is always surging. Recently, the team at Chinese AI startup DeepSeek updated its V3 base model in a low-key manner without large-scale publicity, with the new version DeepSeek-V3-0324 has quietly gone live on the Hugging Face platform for developers to download and deploy. Although the update is very low-key, the new model's significant enhancements in terms of code capability have quickly sparked a great deal of interest and heated discussion in the technical community.
A few hours ago, DeepSeek-AI open sourced an updated version of DeepSeekV3, version 0324, uploaded to HuggingFace on March 24, 2025, and open sourced using the MIT protocol.
The model configuration information shows that DeepSeekV3-0324 remains a MoE grand model, containing 256 routing experts and 1 shared expert per token Uses 8 experts for inference. DeepSeekV3-0324 scales to a maximum context length of 163840 (160K) via RoPE. The model vocabulary size is 129280 and integrates the LoRA mechanism to support lightweight fine-tuning.
None of these parameters have changed from the December 26, 2024 release of DeepSeekV3, which means that this update is most likely the result of continued training or post-training of the original model.
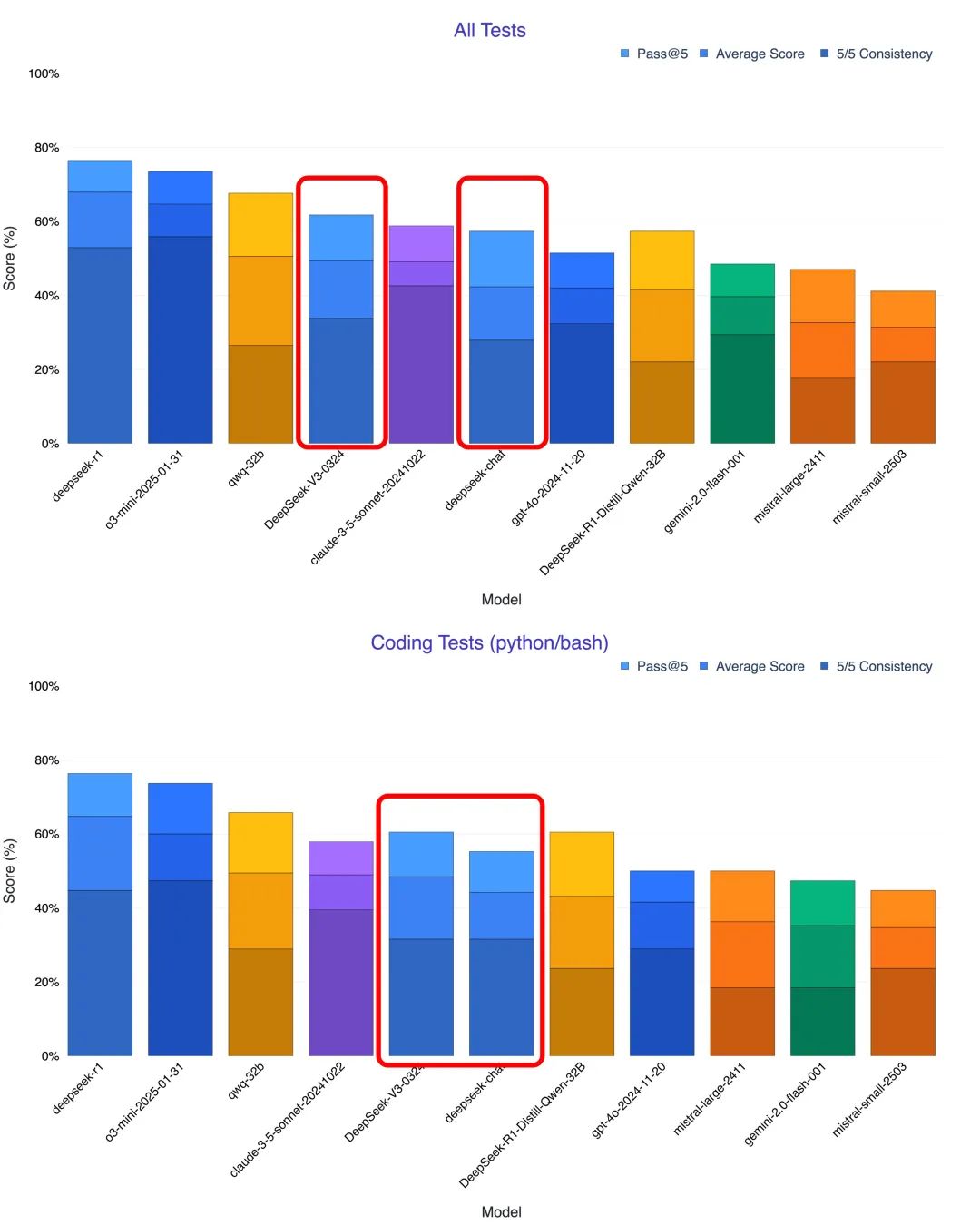
Code capabilities skyrocketed to close-source benchmarks
First impressions from users and multiple tests indicate that the most striking improvement in DeepSeek-V3-0324 is its code generation and comprehension capabilities. Many testers noted that in areas such as mathematical reasoning and front-end development, the new version outperforms even the Claude 3.5 and Claude 3.7 Sonnet. blogger @KuittinenPetri on the social media platform X was even more outspoken when he said that DeepSeek-V3-0324 makes it easy and free to create beautiful HTML5, CSS and front-end code, which is a great way for Anthropic and OpenAI pose new challenges.
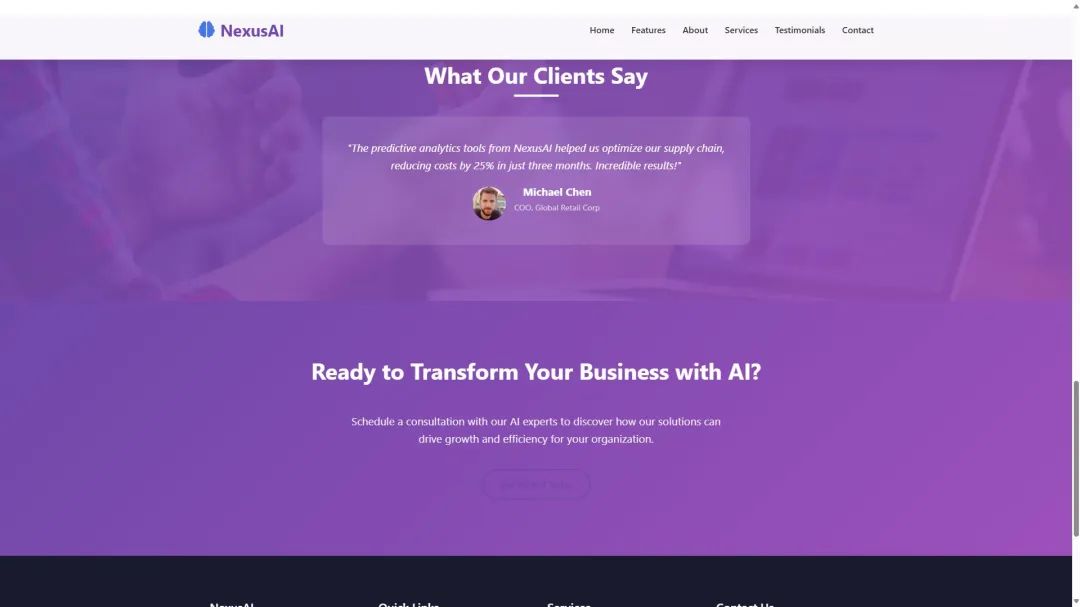
For example, with a simple command, DeepSeek-V3-0324 was able to generate a great looking responsive homepage for an AI company called NexusAI, integrating all the elements into a single HTML5 file. The resulting code was 958 lines long and resulted in an interactive and mobile-friendly website that even included the required image resources. According to @KuittinenPetri, DeepSeek-V3-0324 is DeepSeek The best non-inference model available is not only great at creative writing, but is now even better at generating HTML5 + CSS + front-end code than R1. Another user also managed to get DeepSeek-V3-0324 to create a website where the model generated over 800 lines of code in one go and the site layout was quite successful.
Multi-scenario real-world testing, showing strong programming potential
In order to more fully evaluate the programming capabilities of DeepSeek-V3-0324, many researchers conducted tests with different scenarios and compared it with models such as the old version of V3, Claude 3.7 and o1 pro. The results of the tests proved the significant improvement of the new version of V3 in terms of programming.
- Text to visualization pages: In the test of converting text descriptions into interactive web pages, DeepSeek-V3-0324 shows a quantum leap from the old V3 version. The web pages generated by the new version are not only richer in content, but also in user interface design and layout, which even surpasses the upgrade from Claude 3.5 to 3.7. It is worth noting that DeepSeek-V3-0324 is able to follow detailed instructions to convert PDF file content into beautiful Chinese visualization web pages, which is usually regarded as an area of strength of Claude 3.7.
- Generate 3D animation: In tests of generating interactive 3D presentations from the JS codebase, the new V3 was able to model each step of chocolate making and support tabbed interactions and sidebars. While there is still room for improvement over Claude, it significantly surpasses the capabilities of the old V3.
- UI component design: In the weather forecast UI component design test, V3-0324 has improved its animation performance and the accuracy of weather text labeling, which shows that it is more capable of generating practical user interfaces.
- Physical world simulation: In a test simulating a ball bouncing inside a rotating hexagon, DeepSeek-V3-0324 accurately implements the ball collision effect. Although there are still some flaws, the overall performance is better than the old V3 and comparable to the o1 pro.
- AI game generation: Most strikingly, DeepSeek-V3-0324 generates a playable pixel snakes game with sound effects and AI-assisted modes with just one sentence of instructions. Although it may fall short of Claude 3.7's extend thinking mode in terms of complexity and perfection, the ability to complete a fully functional game is a great demonstration of its powerful programming capabilities.
Technical features and cost advantages
DeepSeek-V3-0324 has not yet published a detailed model card, but it is known to have a parameter size of 685 billion. It is worth noting that DeepSeek V3 uses the Mixed Expert Model (MoE) architecture with 671 billion parameters, of which only 37 billion are activated per inference. (Editor's note: The MoE model significantly reduces computational cost and latency by decomposing large models into multiple "expert" sub-networks while maintaining model performance.) In order to solve the problem of unbalanced expert load in the traditional MoE model, DeepSeek innovatively proposes in V3 the Auxiliary loss free load balancing strategy In addition, V3 dynamically adjusts the expert load by introducing a "bias term" to improve model performance and training efficiency. In addition, V3 utilizes Node-constrained routing mechanisms , to reduce communication costs in large-scale distributed training.
In addition to strong performance, DeepSeek-V3-0324 continues the relaxed MIT open source protocol. More critically, its API is competitively priced compared to OpenAI's o1-pro At least 50 times cheaper. Compared to Claude 3.7, DeepSeek v3 is about a tenth of the price of its input, while the output is about a thirteenth of the price during standard hours, and even a twenty-seventh of the price during special hours. This attractive price advantage, combined with its open source nature, will undoubtedly provide a strong incentive for the popularization and development of AI programming.
DeepSeek-V3-0324 Model Characterization

DeepSeek-V3-0324 demonstrates significant improvements over its predecessor, DeepSeek-V3, in several key areas.
- Reasoning skills are improved:
- MMLU-Pro: 75.9 → 81.2 (+5.3)
- GPQA: 59.1 → 68.4 (+9.3)
- AIME: 39.6 → 59.4 (+19.8)
- LiveCodeBench: 39.2 → 49.2 (+10.0)
- Enhanced front-end web development capabilities:
- Code Execution Enhancement
- Web and game front ends are more aesthetically pleasing
- Chinese writing skills enhancement:
- Quality of style and content improved:
- Closer to R1 writing style
- Higher quality of mid-length writing
- functional enhancement
- Improved multi-round interactive rewriting capability
- Quality of translation and correspondence optimized
- Quality of style and content improved:
- Chinese search capability enhancement:
- More detailed output of report analysis requests
- Function Calling function improved:
- Function Calling Improved accuracy, fixes legacy issues from V3 version
Recommendations for use
System Prompt
The same system alerts with specific dates are used in the official DeepSeek web/app.
该助手为DeepSeek Chat,由深度求索公司创造。
今天是{current date}。
Example:
该助手为DeepSeek Chat,由深度求索公司创造。
今天是3月24日,星期一。
Temperature parameter setting
In the DeepSeek web and application environments, the temperature parameter (Tmodel) is set to 0.3. Considering that many users use the default temperature of 1.0 in API calls, DeepSeek implemented the API temperature (Tapi) mapping mechanism that adjusts the API input temperature value of 1.0 to the most appropriate model temperature setting of 0.3.
Tmodel = Tapi × 0.3 (0 ≤ Tapi ≤ 1)
Tmodel = Tapi - 0.7 (1 < Tapi ≤ 2)
Therefore, if you call V3 through the API, temperature 1.0 corresponds to model temperature 0.3.
Prompts for file uploads and web searches
For file uploads, follow the template below to create prompts, where {file_name},{file_content} cap (a poem) {question} as a parameter.
file_template = \
"""[file name]: {file_name}
[file content begin]
{file_content}
[file content end]
{question}"""
For Web searches.{search_results},{cur_date} cap (a poem) {question} as a parameter.
Chinese query Prompt:
search_answer_zh_template = \
'''# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]...[webpage X end]格式的,X代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:
- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在10个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在5个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}'''
English query Prompt:
search_answer_en_template = \
'''# The following contents are the search results related to the user's message:
{search_results}
In the search results I provide to you, each result is formatted as [webpage X begin]...[webpage X end], where X represents the numerical index of each article. Please cite the context at the end of the relevant sentence when appropriate. Use the citation format [citation:X] in the corresponding part of your answer. If a sentence is derived from multiple contexts, list all relevant citation numbers, such as [citation:3][citation:5]. Be sure not to cluster all citations at the end; instead, include them in the corresponding parts of the answer.
When responding, please keep the following points in mind:
- Today is {cur_date}.
- Not all content in the search results is closely related to the user's question. You need to evaluate and filter the search results based on the question.
- For listing-type questions (e.g., listing all flight information), try to limit the answer to 10 key points and inform the user that they can refer to the search sources for complete information. Prioritize providing the most complete and relevant items in the list. Avoid mentioning content not provided in the search results unless necessary.
- For creative tasks (e.g., writing an essay), ensure that references are cited within the body of the text, such as [citation:3][citation:5], rather than only at the end of the text. You need to interpret and summarize the user's requirements, choose an appropriate format, fully utilize the search results, extract key information, and generate an answer that is insightful, creative, and professional. Extend the length of your response as much as possible, addressing each point in detail and from multiple perspectives, ensuring the content is rich and thorough.
- If the response is lengthy, structure it well and summarize it in paragraphs. If a point-by-point format is needed, try to limit it to 5 points and merge related content.
- For objective Q&A, if the answer is very brief, you may add one or two related sentences to enrich the content.
- Choose an appropriate and visually appealing format for your response based on the user's requirements and the content of the answer, ensuring strong readability.
- Your answer should synthesize information from multiple relevant webpages and avoid repeatedly citing the same webpage.
- Unless the user requests otherwise, your response should be in the same language as the user's question.
# The user's message is:
{question}'''
Local Run Methods
The model structure of DeepSeek-V3-0324 is identical to DeepSeek-V3. For more information on running this model locally, visit the DeepSeek-V3 Code Repository.
The model supports features such as Function Calling, JSON output, and FIM completion. For instructions on how to build prompts to utilize these features, see the DeepSeek-V2.5 Code Repository.
DeepSeek-V3-0324 is a low-key update that has attracted a lot of attention in the tech world. It has made impressive strides in terms of coding power, not only showing strength in a number of programming tasks, but in some ways rivaling top models such as Claude 3.5/3.7 Sonnet. Its open-source, efficient and cost-effective features are a sign that the The era of universal access to AI programming may be accelerating DeepSeek. As more third-party platforms are connected to the new V3 version of DeepSeek, developers and ordinary users will be able to experience advanced AI programming capabilities at a lower cost. This will undoubtedly energize the entire AI ecosystem and drive the emergence of more innovative applications. With the powerful code capability V3 and the top reasoning capability R1, DeepSeek's future R2 model is worth waiting for.
This update of DeepSeekV3 proves once again that China's AI technology is rapidly developing and catching up. The open source and free commercial license strategy of DeepSeek-V3-0324 will undoubtedly attract more developers and enterprises to join the ranks of AI application development, and jointly promote the progress and popularization of AI technology.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...