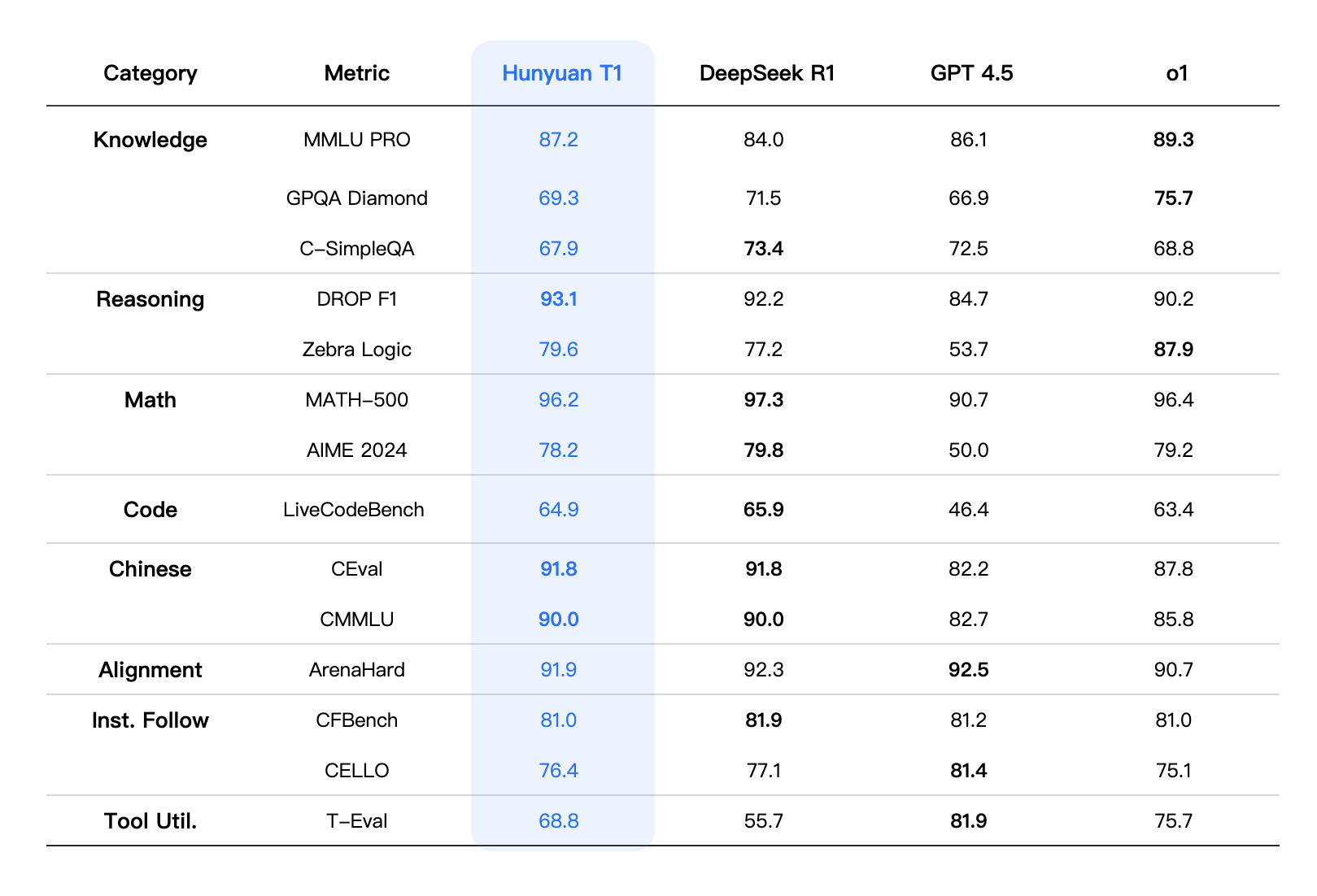
DeepSeek-R1 Capabilities in Detail, with Chinese Evaluation Report

speed reading
Experience:DeepSeek Official website: chat.deepseek.com Chat with DeepSeek-R1 and turn on the "Deep Thinking" button. Visit API compatible with OpenAI format The
Benefits:Deploying DeepSeek-R1 Open Source Models Online with Free GPU Computing Power ,Giving away 100$ DeepSeek-R1 credits,Top 5 AI Inference Platforms That Use Full-Blooded DeepSeek-R1 for Free
Recurrence:Recent attempts to reproduce There are quite a few projects for DeepSeek-R1, so keep an eye on the following articles:TinyZero: A Low-Cost Replication of DeepSeeK-R1 Zero's Epiphany Effect ,Open R1: Hugging Face Replicates the Training Process of DeepSeek-R1 ,Replicating DeepSeek-R1: 8K Math Examples Help Small Models Achieve Reasoning Breakthroughs through Reinforcement Learning And there's even that:R1 Overthinker: Forcing DeepSeek R1 Models to Think Longer The
Summary:Context length: 128K, $2.19/per million output tokens (big model world of Poundland), performance comparable to OpenAI-o1, full open source model free distillation and commercial use, imaginative front-end functionality for writing
Base model: Both DeepSeek-R1-Zero and DeepSeek-R1 are trained based on DeepSeek-V3-Base, and DeepSeek-R1 is strengthened by a small amount of long CoT data, and the output is more structured and parsimonious.
Distillation modeling (overall enhancement of existing open source miniatures capabilities): Distill DeepSeek-R1 to multiple smaller models that are ( Ollama (available for download)

Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, Llama-3.3-70B-Instruct
Training Flow of DeepSeek-R1(-Zero)
- Cold start: fine-tuning on the CoT example
- Reasoning Reinforcement Learning: adding linguistic consistency rewards
- Data generation: created 80 10,000 training samples
- Ultimate reinforcement learning: balanced competencies (both reasoning and generalized) through blended feedback

problem, the API's context length may not be enough in programming

Benchmark evaluation
Strong reasoning skills:
Performs well on math problems, achieving performance comparable to OpenAI-01-1217. Obtained an amazingly high score (97.3%) on the MATH-500 benchmark.
Strong performance in coding algorithm tasks such as Codeforces and LiveCodeBench.
Demonstrate strong capabilities on tasks that require complex reasoning (e.g., FRAMES).
Strong generalist capabilities:
Excellent performance in knowledge-based benchmarks such as MMLU, MMLU-Pro and GPQA Diamond.
Also excels in writing, answering open field questions, and a variety of other tasks.
Excellent length control win rates on benchmarks such as AlpacaEval 2.0 and ArenaHard show that it intelligently handles non-exam oriented queries.
Ability to generate concise summaries and avoid length bias.
Good readability:With cold-start data and a specific design in the training process, DeepSeek-R1 output is easier to read, using the proper format and structure.
Multilingualism:Although it is currently optimized mainly for Chinese and English, it can show some ability in handling queries in multiple languages.
Ability to follow instructions:It performed well on the IF-Eval benchmark, demonstrating its ability to understand and follow instructions well.
Self-evolving ability:Through reinforcement learning, models can autonomously learn and improve their reasoning abilities and are able to handle complex problems by increasing their thinking time.
Excellent distillation potential:DeepSeek-R1 can be used as a teacher model to distill inference power to smaller models, and the distilled models have excellent performance, e.g., DeepSeek-R1-Distill-Qwen-32B, which significantly outperforms the other models on several benchmarks.
About Local Programming Capabilities
If you think v3 is good enough for programming, which is the desktop alternative distillation model? Compared to DeepSeek V3, which distillation model is comparable? According to the LiveCodeBench score, DeepSeek V3 scores 42.2 and the distillation model Qwen 14B scores 53.1, which has comparable performance and relatively desktop class size can run, we recommend you to use 14B on the desktop.
DeepSeek-R1: Motivating LLM Reasoning through Reinforcement Learning.
Posted by DeepSeek-AI
Original: https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf
summaries
We introduce our first-generation inference models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained by large-scale reinforcement learning (RL) without an initial supervised fine-tuning (SFT) step, demonstrates superior inference. With RL, DeepSeek-R1-Zero naturally emerges with many powerful and interesting inference behaviors. However, it also encounters some challenges such as poor readability and language mixing. To address these issues and further improve inference performance, we introduce DeepSeek-R1, which combines multi-stage training and cold-start data before RL. DeepSeek-R1 achieves performance comparable to OpenAI-01-1217 on inference tasks. To support the research community, we open source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) based on Qwen and Llama refinements.

Fig. 1 | Benchmark performance of DeepSeek-R1.
catalogs
1 Introduction
1.1 Contributions
1.2 Summary of assessment results
2 Methodology
2.1 General
2.2 DeepSeek-R1-Zero: Reinforcement Learning Based on Foundational Models
2.2.1 Enhanced Learning Algorithm
2.2.2 Reward modeling
2.2.3 Training templates
2.2.4 Performance of DeepSeek-R1-Zero, Self-Evolutionary Processes and Moments of Epiphany
2.3 DeepSeek-R1: Reinforcement Learning with a Cold Start
2.3.1 Cold start
2.3.2 Reasoning-oriented reinforcement learning
2.3.3 Rejection of sampling and supervision of fine-tuning
2.3.4 Reinforcement learning for all scenarios
2.4 Distillation: augmenting small models with reasoning power
3 Experiments
3.1 DeepSeek-R1 evaluation
3.2 Evaluation of Distillation Models
4 Discussion
4.1 Distillation vs.
4.2 Failed attempts
5 Conclusions, limitations and future work
1. Introduction
In recent years, large-scale language models (LLMs) have undergone rapid iteration and development (Anthropic, 2024; Google, 2024; OpenAI, 2024a), gradually closing the gap leading to artificial general intelligence (AGI).
Recently, post-training has become an important part of the complete training process. It has been shown to improve the accuracy of reasoning tasks, align with societal values, and adapt to user preferences, while requiring relatively few computational resources compared to pre-training. In terms of reasoning power, OpenAI's o1 (OpenAI, 2024b) family of models introduces for the first time scaling while reasoning by increasing the length of the chain-of-thought reasoning process. This approach has led to significant advances in a variety of reasoning tasks, such as mathematical, coding, and scientific reasoning. However, the challenge of effective test-time scaling remains an open question for the research community. Some previous work has explored various approaches including process-based reward models (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023), reinforcement learning (Kumar et al., 2024), and search algorithms such as Monte-Carlo tree search and bundle search (Feng et al., 2024; Trinh et al., 2024). 2024; Trinh et al.) However, none of these methods have been able to achieve generalized inference performance comparable to OpenAI's o1 family of models.
In this paper, we take the first step towards improving the reasoning capabilities of language models using pure reinforcement learning (RL). Our goal is to explore the potential of LLM to develop reasoning capabilities without any supervised data, focusing on self-evolution through a pure RL process. Specifically, we use DeepSeek-V3-Base as the base model and GRPO (Shao et al., 2024) as the RL framework to improve the model's performance in reasoning. During the training process, DeepSeek-R1-Zero naturally emerges with many powerful and interesting inference behaviors. After thousands of RL steps, DeepSeek-R1-Zero shows excellent performance on inference benchmarks. For example, AIME 2024的pass@1得分从15.6%提高到71.0% and by majority voting, the score is further improved to 86.7%, reaching the performance level of OpenAI-01-0912.
However, DeepSeek-R1-Zero encounters challenges such as poor readability and language mixing. To address these issues and further improve inference performance, we introduce DeepSeek-R1, which combines a small amount of cold-start data with a multi-stage training process. Specifically, we first collect thousands of cold-start data to fine-tune the DeepSeek-V3-Base model. After this, we perform inference-oriented RL similar to DeepSeek-R1-Zero. as the RL process nears convergence, we create new SFT data by rejection sampling of RL checkpoints, combine it with supervised data from DeepSeek-V3 in the domains of writing, factual quizzing, and self-awareness, and then retrain the DeepSeek- V3-Base model. After fine-tuning with the new data, this checkpoint undergoes an additional RL process, which takes into account cues from all scenarios. After these steps, we obtain a checkpoint called DeepSeek-R1, which is comparable in performance to OpenAI-01-1217.
We further explored distillation from DeepSeek-R1 to smaller dense models. Using Qwen 2.5-32B (Qwen, 2024b) as the base model, distillation directly from DeepSeek-R1 outperforms applying RL on top of it, suggesting that the inference patterns found in the larger base model are critical to improving inference. We open-source the Qwen and Llama (Dubey et al., 2024) family of models for distillation. Notably, our distilled 14B model substantially outperforms the state-of-the-art open-source QwQ-32B-Preview (Qwen, 2024a), and the distilled 32B and 70B models set a new record for reasoning benchmarks in dense models.
1.1 Contributions
Post-training: large-scale reinforcement learning based on base models
- We apply Reinforcement Learning (RL) directly to the underlying model without relying on Supervised Fine Tuning (SFT) as a preliminary step. This approach allows the model to explore the chain of thought (CoT) for solving complex problems, leading to the development of DeepSeek-R1-Zero.DeepSeek-R1-Zero demonstrates the ability to self-validate, reflect, and grow the CoT, marking an important milestone for the research community. Notably, this is the first public study to validate that the reasoning ability of LLM can be motivated by pure RL without the need for SFT.This breakthrough paves the way for future developments in the field.
- We describe the process used to develop DeepSeek-R1. The process consists of two RL phases designed to discover improved reasoning patterns and align with human preferences, and two SFT phases that serve as seeds for the model's reasoning and non-reasoning capabilities. We believe the process will benefit the industry by creating better models.
Distillation: small models can be powerful
- We demonstrate that inference patterns from large models can be distilled into smaller models for better performance compared to inference patterns discovered via RL on small models. The open-source DeepSeek-R1 and its API will benefit the research community in distilling better small models in the future.
- Using inference data generated by DeepSeek-R1, we fine-tuned several dense models widely used in the research community. The evaluation results show that the distilled small dense models perform well in benchmarks.DeepSeek-R1-Distill-Qwen-7B achieves a score of 55.51 TP3T on AIME 2024, outperforming QwQ-32B-Preview.In addition, DeepSeek-R1-Distill-Qwen-32B scored 72.6% on AIME 2024, 94.3% on MATH-500, and 57.2% on LiveCodeBench.These results are significantly better than previous open-source models and comparable to o1-mini. We open-source to the community distillation 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on the Qwen2.5 and Llama3 series.
1.2 Summary of assessment results
- Inference tasks:(1) DeepSeek-R1 obtains a pass@1 score of 79.81 TP3T on AIME 2024, which slightly outperforms OpenAI-o1-1217.On MATH-500, it obtains an impressive 97.31 TP3T score, which is comparable to OpenAI-o1-1217's performance and significantly better than other models. (2) On coding-related tasks, DeepSeek-R1 demonstrated expert level in the code competition task as it achieved a 2,029 Elo rating on Codeforces, outperforming the 96.31 TP3T human participant in that competition. For engineering-related tasks, DeepSeek-R1 performed slightly better than DeepSeek-V3, which helps developers work in the real world.
- **** knowledge: on benchmarks such as MMLU, MMLU-Pro, and GPQA Diamond, DeepSeek-R1 achieves excellent results, significantly outperforming DeepSeek-V3, scoring 90.8% on MMLU, 84.0% on MMLU-Pro, and GPQA Diamond scored 71.5%.Although its performance is slightly lower than OpenAI-01-1217 on these benchmarks, DeepSeek-R1 outperforms the other closed-source models, demonstrating its competitive advantage in educational tasks. On the factual benchmark SimpleQA, DeepSeek-R1 outperforms DeepSeek-V3, demonstrating its ability to handle fact-based queries. A similar trend is observed in OpenAI-o1 beyond 4o for this benchmark.
- Other: DeepSeek-R1 also performed well in a variety of tasks, including creative writing, general question answering, editing, summarizing, and more. It achieved a length control win rate of 87.61 TP3T on AlpacaEval 2.0 and 92.31 TP3T on ArenaHard, demonstrating its strong ability to intelligently process non-exam-oriented queries. In addition, DeepSeek-R1 performs well in tasks requiring long context comprehension and significantly outperforms DeepSeek-V3 in long context benchmarks.
2. Methodology
2.1 General
Previous work has relied heavily on large amounts of supervised data to improve model performance. In this study, we demonstrate that inference ability can be significantly improved by large-scale reinforcement learning (RL), even without using supervised fine-tuning (SFT) as a cold-start. Furthermore, performance can be further enhanced by including a small amount of cold-start data. In the following sections, we present (1) DeepSeek-R1-Zero, which applies RL directly to the base model without any SFT data, and (2) DeepSeek-R1, which applies RL starting from checkpoints fine-tuned with thousands of long Chain of Thoughts (CoT) examples. and (3) distilling the inference power of DeepSeek-R1 into small dense models.
2.2 DeepSeek-R1-Zero: Reinforcement Learning Based on Foundational Models
Reinforcement learning has shown significant effectiveness in inference tasks, as demonstrated in our previous work (Shao et al., 2024; Wang et al., 2023). However, these tasks rely heavily on supervised data, which is time-consuming to collect. In this section, we explore the potential of LLM to develop reasoning abilities without any supervised data, focusing on self-evolution through a pure reinforcement learning process. We begin with a brief overview of our reinforcement learning algorithm and then present some exciting results, which we hope will provide valuable insights to the community.
Group Relative Strategy Optimization To save the training cost of RL, we employ Group Relative Strategy Optimization (GRPO) (Shao et al., 2024), which abandons the critic model, which is usually of the same size as the strategy model, and instead estimates the baseline from the group scores. Specifically, for each problem q, GRPO samples a set of outputs {o1, o2,..., oG} from the old strategy πθold and then optimizes the strategy model πθ by maximizing the following objective:

where ɛ and β are hyperparameters and Ai is the dominance, using the rewards corresponding to the outputs within each group {r1,r2, . . . , rG} for computation:

The reward is the source of the training signal, which determines the optimization direction of RL. To train DeepSeek-R1-Zero, we use a rule-based reward system that consists of the following two main types of rewards:
- Accuracy Rewards: Accuracy reward models assess whether a response is correct. For example, for math problems with deterministic results, the model needs to provide the final answer in a specified format (e.g., within a box) so that rule-based correctness verification can be reliably performed. Similarly, for LeetCode problems, the compiler can be used to generate feedback based on predefined test cases.
- Format Reward: In addition to the Accuracy Reward model, we used the Format Reward model that forces the model to place the thought process between the '' and '' labels.
We did not use outcome or process neural reward models in the development of DeepSeek-R1-Zero because we found that neural reward models can suffer from reward hacking during large-scale reinforcement learning and that retraining the reward model requires additional training resources, which can complicate the overall training process.
To train DeepSeek-R1-Zero, we first designed a simple template that instructs the base model to follow the instructions we specified. As shown in Table 1, this template requires DeepSeek-R1-Zero to first generate the reasoning process and then the final answer. We intentionally limited the constraints to this structural format to avoid any content-specific biases, such as enforcing reflective reasoning or promoting specific problem-solving strategies, to ensure that we could accurately observe the natural progression of the model through the reinforcement learning (RL) process.
用户与助手之间的对话。用户提出一个问题,助手解决该问题。
助手首先在脑海中思考推理过程,然后为用户提供答案。
推理过程和答案分别用 <think> </think> 和 <answer> </answer> 标签括起来,即:
<think> 此处为推理过程 </think>
<answer> 此处为答案 </answer>。
用户:提示。助手:
Table 1 | Templates for DeepSeek-R1-Zero. During training, thedraw attention to sth.will be replaced with a specific reasoning problem.
Performance of DeepSeek-R1-Zero Figure 2 depicts the performance trajectory of DeepSeek-R1-Zero on the AIME 2024 benchmark throughout reinforcement learning (RL) training. As shown, DeepSeek-R1-Zero's performance exhibits steady and consistent enhancement as RL training progresses. Notably, the average pass@1 score of AIME 2024 shows significant growth, jumping from an initial 15.61 TP3T to an impressive 71.01 TP3T, reaching a performance level comparable to OpenAI-01-0912. This significant improvement highlights the effectiveness of our RL algorithm in optimizing model performance.
Table 2 provides a comparative analysis of DeepSeek-R1-Zero and OpenAI's o1-0912 model on various inference-related benchmarks. The findings show that RL makes

Table 2 | Comparison of DeepSeek-R1-Zero and OpenAI o1 models on inference-related benchmarks.

Figure 2 | AIME accuracy of DeepSeek-R1-Zero during training. For each problem, we sampled 16 responses and computed the overall average accuracy to ensure stable evaluation.
DeepSeek-R1-Zero achieves powerful inference without any supervised fine-tuning of the data. This is a noteworthy achievement as it highlights the model's ability to learn and generalize effectively through RL alone. Moreover, the performance of DeepSeek-R1-Zero can be further enhanced by applying majority voting. For example, when using majority voting in the AIME benchmark, DeepSeek-R1-Zero's performance improves from 71.01 TP3T to 86.71 TP3T, thus exceeding the performance of OpenAI-01-0912.DeepSeek-R1-Zero achieves such competitive performance with and without majority voting, which highlights its strong underlying capabilities and its potential for further development in reasoning tasks.
DeepSeek-R1-Zero's Self-Evolutionary Process DeepSeek-R1-Zero's self-evolutionary process is a fascinating demonstration of how RL can drive models to autonomously improve their reasoning. By launching RL directly from the base model, we can closely monitor the model's progress without being subject to a supervised fine-tuning phase. This approach provides a clear view of how the model evolves over time, especially in terms of its ability to handle complex reasoning tasks.
As shown in Figure 3, DeepSeek-R1-Zero's thinking time shows a continuous improvement throughout the training process. This improvement is not the result of external tuning, but rather an intrinsic development within the model.DeepSeek-R1-Zero naturally gains the ability to solve increasingly complex reasoning tasks by utilizing extended test-time computation. This computation ranges from generating hundreds to thousands of inference tokens, thus allowing the model to explore and refine its thought processes in greater depth.
One of the most striking aspects of this self-evolution is the emergence of complex behaviors as computation increases during testing. Reflection - i.e., the model revisiting and reevaluating its previous steps - as well as the exploration of alternative problem-solving approaches - emerges spontaneously. These behaviors are not explicitly programmed, but emerge as a result of the model's interaction with the reinforcement learning environment. This spontaneous development significantly enhances DeepSeek-R1-Zero's reasoning capabilities, enabling it to tackle more challenging tasks with greater efficiency and accuracy.

Fig. 3 | Average response length of DeepSeek-R1-Zero on the RL process training set.DeepSeek-R1-Zero naturally learns to solve inference tasks by taking more thinking time.
Epiphany moments in DeepSeek-R1-Zero A particularly interesting phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of "epiphany moments". As shown in Table 3, this moment occurs in the intermediate version of the model. At this stage, DeepSeek-R1-Zero learns to allocate more thinking time to the problem by re-evaluating its initial approach. This behavior is not only a testament to the model's growing inference capabilities, but also a fascinating example of how reinforcement learning can lead to unexpected and complex results.

Table 3 | An interesting "epiphany moment" for the intermediate version of DeepSeek-R1-Zero. The model learns to rethink using an anthropomorphic tone. This was also our own epiphany moment, allowing us to witness the power and beauty of reinforcement learning.
This moment was an "epiphany" not only for the model, but also for the researchers who observed its behavior. It emphasizes the power and beauty of reinforcement learning: instead of explicitly teaching a model how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The "epiphany moment" is a powerful reminder of the potential of RL to unlock new levels of intelligence in AI systems, paving the way for more autonomous and adaptive models in the future.
Disadvantages of DeepSeek-R1-Zero While DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it also faces some problems. For example, DeepSeek-R1-Zero struggles with poor readability and language mixing. To make the reasoning process more readable and share it with the open community, we explored DeepSeek-R1, an approach that utilizes RL with human-friendly cold-start data.
2.3 DeepSeek-R1: Reinforcement Learning with a Cold Start
Inspired by the promising results of DeepSeek-R1-Zero, two natural questions arise: 1) Can inference performance be further improved or convergence accelerated by incorporating a small amount of high-quality data as a cold-start? and 2) How can we train a user-friendly model that not only produces clear and coherent Chains of Thought (CoTs), but also demonstrates strong generalization capabilities? To address these questions, we designed a process for training DeepSeek-R1. The process consists of four phases, which are summarized below.
Unlike DeepSeek-R1-Zero, in order to prevent an early unstable cold-start phase when RL training starts from the base model, for DeepSeek-R1 we constructed and collected a small amount of long CoT data to fine-tune the model as an initial RL participant. To collect such data, we explored several approaches: using few-sample prompts with long CoTs as examples, directly prompting the model to generate detailed answers with reflection and validation, collecting DeepSeek-R1-Zero output in a readable format, and post-processing the results via human annotators.
In this work, we collected thousands of cold-start data to fine-tune DeepSeek-V3-Base as a starting point for RL. Advantages of cold-start data over DeepSeek-R1-Zero include:
- Readability: A major limitation of DeepSeek-R1-Zero is that its content is often not readable. Responses may mix multiple languages or lack the markup formatting used to highlight the user's answers. Instead, when creating cold-start data for DeepSeek-R1, we designed a readable schema that includes a summary at the end of each response and filters out responses that are not easily readable. Here, we define the output format as | special_token | | special_token |
, where the reasoning process is the CoT of the query and the summary is used to summarize the results of the reasoning. - Potential: By using a human prior to craft a model for cold-start data, we observe better performance against DeepSeek-R1-Zero. We argue that iterative training is a better way to reason about models.
After fine-tuning DeepSeek-V3-Base on cold-start data, we applied the same large-scale reinforcement learning training process employed in DeepSeek-R1-Zero. The focus of this phase was to enhance the inference capabilities of the model, especially in tasks that require inference, such as coding, mathematical, scientific, and logical reasoning involving explicit questions. During the training process, we observed that the CoT often exhibits language mixing, especially when the RL cues involve multiple languages. To mitigate the language mixing problem, we introduced a linguistic alignment reward during RL training, which was computed as the proportion of target language words in the CoT. Although ablation experiments show that this alignment leads to a slight decrease in model performance, this reward is consistent with human preferences, making it more readable. Finally, we combine the rewards of accuracy and linguistic consistency in the reasoning task by directly summing them to form the final reward. We then apply reinforcement learning (RL) training on the fine-tuned model until it reaches convergence on the inference task.
As the inference-oriented RL converges, we utilize the generated checkpoints to collect SFT (supervised fine-tuning) data for subsequent rounds. Unlike the initial cold-start data, which focuses primarily on reasoning, this phase incorporates data from other domains to enhance the model's capabilities in writing, role-playing, and other generalized tasks. Specifically, we generated data and fine-tuned the model as described below.
Inference Data We curated inference cues and generated inference trajectories by performing rejection sampling from the RL-trained checkpoints described above. In the previous phase, we only included data that could be evaluated using rule-based rewards. However, in this phase, we extend the dataset by combining more data, some of which use generative reward models, by feeding real labels and model predictions into DeepSeek-V3 for judgment. Additionally, since the model output is sometimes confusing and difficult to read, we filtered out thought chains with mixed language, long paragraphs, and code chunks. For each cue, we sampled multiple responses and retained only the correct response. In total, we collected about 600,000 training samples related to reasoning.
Non-Reasoned Data For non-reasoned data, such as writing, factual quizzing, self-awareness, and translation, we employ the DeepSeek-V3 process and reuse portions of DeepSeek-V3's SFT dataset. For certain non-reasoning tasks, we invoke DeepSeek-V3 to generate potential chains of thought by prompting before answering a question. However, for simple queries (e.g., "hello"), we do not provide CoTs in the responses.Finally, we collect a total of about 200,000 training samples that are not related to inference.
We fine-tuned DeepSeek-V3-Base for two periods using the above curated dataset of about 800,000 samples.
To further align the model with human preferences, we implemented a second phase of reinforcement learning aimed at increasing the usefulness and harmlessness of the model while continuously improving its inference. Specifically, we train the model using a combination of reward signals and various cue distributions. For inference data, we stick to the approach outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide the learning process in the domains of mathematical, coding, and logical reasoning. For general data, we rely on reward models to capture human preferences in complex and detailed scenarios. We build on the DeepSeek-V3 process and use similar preference pairs and training cue distributions. To be helpful, we focus exclusively on the final summary, ensuring that the evaluation emphasizes the utility and relevance of the response to the user while minimizing interference with the underlying reasoning process. To provide harmlessness, we evaluate the entire response of the model, including the reasoning process and the summary, to identify and mitigate any potential risks, biases, or harmful content that may have arisen during the generation process. Ultimately, the integration of reward signals and various data distributions allows us to train a model that excels at reasoning and prioritizes both usefulness and harmlessness.
2.4 Distillation: augmenting small models with reasoning power
In order to make more efficient small models with inference capabilities like DeepSeek-R1, we directly fine-tuned open-source models such as Qwen (Qwen, 2024b) and Llama (AI@Meta, 2024) using the 800,000 samples compiled by DeepSeek-R1 (as detailed in §2.3.3). Our findings suggest that this simple distillation method can significantly enhance the inference of small models. The base models we use here are Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5-14B, Qwen2.5-32B, Llama-3.1-8B, and Llama-3.3-70B-Instruct. we chose Llama-3.3 because of its slightly better reasoning power than that of Llama-3.1.
For the distillation model, we apply only SFT and do not include the RL stage, although merging RL can significantly improve model performance. Our main goal here is to demonstrate the effectiveness of the distillation technique, leaving the exploration of the RL stage to the wider research community.
3. Experiments
benchmarking We have published a number of papers in MMLU (Hendrycks et al., 2020), MMLU-Redux (Gema et al., 2024), MMLU-Pro (Wang et al., 2024), C-Eval (Huang et al., 2023), and CMMLU (Li et al., 2023), IFEval (Zhou et al., 2023), FRAMES (Krishna et al., 2024), GPQA Diamond (OpenAI Diamond) (Rein et al., 2023), SimpleQA Diamond (OpenAI Diamond) (Rein et al., 2023), and IFEval (Li et al., 2023). IFEval (Zhou et al., 2023), FRAMES (Krishna et al., 2024), GPQA Diamond (Rein et al., 2023), SimpleQA (OpenAI, 2024c), C-SimpleQA (He et al., 2024), SWE- Bench Verified (OpenAI, 2024d), Aider¹ , LiveCodeBench (Jain et al., 2024) (2024-08 - 2025-01), Codeforces², Chinese National High School Mathematics Olympiad (CNHSMOA) School Mathematics Olympiad (CNMO 2024)³, and American Invitational Mathematics Examination 2024 (AIME 2024) (MAA, 2024). In addition to the standard benchmark tests, we use LLM as a jury to evaluate the performance of our models on open generative tasks. Specifically, we follow the original configurations of AlpacaEval 2.0 (Dubois et al., 2024) and Arena-Hard (Li et al., 2024), which utilize GPT-4-Turbo-1106 as a jury for pairwise comparisons. Here, we only make the final summaries available for evaluation to avoid length bias. For distillation models, we report representative results on AIME 2024, MATH-500, GPQA Diamond, Codeforces, and LiveCodeBench.
Evaluation Tips Following the setup in DeepSeek-V3, standard benchmarks such as MMLU, DROP, GPQA Diamond, and SimpleQA are evaluated using prompts from the simple-evals framework. For MMLU-Redux, we use the Zero-Eval prompt format (Lin, 2024) in the zero-sample setting. For MMLU-Pro, C-Eval, and CLUE-WSC, since the original cues are undersampled, we slightly modified the cues to the zero-sample setting. CoTs in fewer samples may impair the performance of DeepSeek-R1. The other datasets follow the original evaluation protocol with default hints provided by their creators. For code and math benchmarking, the HumanEval-Mul dataset covers eight major programming languages (Python, Java, C++, C#, JavaScript, TypeScript, PHP, and Bash). Model performance on LiveCodeBench is evaluated using the CoT format, with data collected between August 2024 and January 2025. The Codeforces dataset was evaluated using questions from 10 Div.2 competitions as well as expert-produced test cases, and then the expected ratings and percentages of competitors were calculated. Obtain the results of the SWE-Bench validation through an agentless framework (Xia et al., 2024). AIDER-related benchmarks were measured using the "diff" format, and the DeepSeek-R1 output was capped at 32,768 tokens per benchmark.
base line (in geodetic survey) We conducted comprehensive evaluations against several powerful baselines, including DeepSeek-V3, Claude-Sonnet-3.5-1022, GPT-40-0513, OpenAI-01-mini, and OpenAI-01-1217. due to the challenging access to the OpenAI-01-1217 API in mainland China we report its performance based on official reports. For the distillation model, we also compared the open source model QwQ-32B-Preview (Qwen, 2024a).
Generate settings For all our models, the maximum generation length is set to 32,768 tokens. for benchmarks that require sampling, we use a temperature of 0.6, a top-p value of 0.95, and generate 64 responses for each query to estimate pass@1.
3.1 DeepSeek-R1 Evaluation
For education-oriented knowledge benchmarks such as MMLU, MMLU-Pro, and GPQA Diamond, DeepSeek-R1 demonstrates superior performance over DeepSeek-V3. This improvement is mainly attributed to the increased accuracy in STEM-related problems, where significant gains are achieved through large-scale reinforcement learning (RL). In addition, DeepSeek-R1 performs well on FRAMES, a long context-dependent QA task, demonstrating its strong document analysis capabilities. This highlights the potential of inference models in AI-driven search and data analysis tasks. On the factual benchmark SimpleQA, DeepSeek-R1 outperforms DeepSeek-V3, demonstrating its ability to handle fact-based queries. A similar trend was observed when OpenAI-01 outperformed GPT-40 in this benchmark. However, DeepSeek-R1 does not perform as well as DeepSeek-V3 on the Chinese SimpleQA benchmark, mainly due to its tendency to refuse to answer certain queries after a secure RL. In the absence of a secure RL, DeepSeek-R1 can achieve an accuracy of more than 70%.

Table 4 | Comparison between DeepSeek-R1 and other representative models.
DeepSeek-R1 also achieved impressive results on the IF-Eval, a benchmark test designed to evaluate a model's ability to follow format instructions. These improvements may be related to the instruction adherence data included in the final stages of supervised fine-tuning (SFT) and RL training. In addition, superior performance was observed on AlpacaEval2.0 and ArenaHard, demonstrating that DeepSeek-R1 has an advantage in writing tasks and open-domain question answering. Its significantly better performance than DeepSeek-V3 highlights the generalization benefits of large-scale RL, which not only improves inference but also performance across multiple domains. In addition, DeepSeek-R1 generates concise summary lengths, and the average on ArenaHard token of 689 and an average of 2,218 characters on AlpacaEval 2.0. This indicates that DeepSeek-R1 avoids introducing length bias during GPT-based evaluation, further solidifying its robustness across multiple tasks.
For the math task, DeepSeek-R1's performance is comparable to that of OpenAI-01-1217, significantly outperforming the other models. A similar trend is observed in coding algorithm tasks such as LiveCodeBench and Codeforces, where inference-centered models dominate these benchmarks. For engineering-oriented coding tasks, OpenAI-01-1217 outperforms DeepSeek-R1 on Aider, but achieves comparable performance on SWE Verified. We believe that the performance of DeepSeek-R1 for engineering tasks will be improved in the next release, as the amount of relevant RL training data is still very limited at this point.
3.2 Evaluation of Distillation Models

Table 5 | Comparison of the DeepSeek-R1 distillation model with other models comparable on the inference correlation benchmark test.
As shown in Table 5, simply distilling the output of DeepSeek-R1 allows the efficient DeepSeek-R1-7B (i.e., DeepSeek-R1-Distill-Qwen-7B, henceforth referred to by this name) to outperform non-inference models such as GPT-40-0513 in every respect. DeepSeek-R1-14B outperforms QwQ-32B-Preview in all evaluation metrics, while DeepSeek-R1-32B and DeepSeek-R1-70B significantly outperform o1-mini in most benchmarks. These results demonstrate the strong potential of distill. In addition, we find that applying RL to these distillation models leads to significant further gains. We believe this is worth exploring further, and therefore only present results for the simple SFT distillation model here.
4. Discussion
4.1 Distillation vs.

Table 6 | Comparison between the distillation model and the RL model on the inference correlation benchmark.
In Section 3.2, we can see that by distilling DeepSeek-R1, small models can achieve impressive results. However, a question remains: can the model achieve comparable performance with the large-scale RL training discussed in this paper (without distillation)?
To answer this question, we performed large-scale RL training of Qwen-32B-Base using math, code, and STEM data for more than 10,000 steps, resulting in DeepSeek-R1-Zero-Qwen-32B. The experimental results (shown in Fig. 6) show that the base model of 32B, after large-scale RL training, achieves a performance comparable to that of the QwQ-32B-Preview at a comparable level. However, DeepSeek-R1-Distill-Qwen-32B, which is distilled from DeepSeek-R1, significantly outperforms DeepSeek-R1-Zero-Qwen-32B in all benchmarks. Therefore, we can draw two conclusions: firstly, distilling a more powerful model into a smaller model produces excellent results while smaller models that rely on the large-scale RLs mentioned in this paper require enormous computational power and may not even achieve distillation performance. Second, while the distillation strategy is both cost-effective and efficient, more powerful underlying models and larger-scale reinforcement learning may still be required to move beyond the boundaries of intelligence.
4.2 Failed attempts
We also encountered some failures and setbacks during the early development stages of DeepSeek-R1. We share our failures here to provide insights, but this does not mean that these methods are incapable of developing effective inference models.
Process Reward Modeling (PRM) PRM is a reasonable approach to guide models to adopt better methods for solving reasoning tasks (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023). In practice, however, there are three main limitations of PRMs that may hinder their ultimate success. First, it is difficult to explicitly define fine-grained steps in general reasoning. Second, determining whether the current intermediate step is correct is a difficult task. Automatic annotation using models may not produce satisfactory results, while manual annotation is not conducive to scaling. Third, once model-based PRM is introduced, it will inevitably lead to reward hacking (Gao et al., 2022), and retraining the reward model requires additional training resources, which can complicate the entire training process. In summary, while PRM demonstrates good ability to reorder model-generated top-N responses or assist in guided search (Snell et al., 2024), its advantages are limited when compared to the additional computational overhead introduced during large-scale reinforcement learning in our experiments.
Monte Carlo Tree Search (MCTS) Inspired by AlphaGo (Silver et al., 2017b) and AlphaZero (Silver et al., 2017a), we explored the use of Monte Carlo Tree Search (MCTS) to enhance the scalability of computation at test time. This approach involves decomposing the answer into smaller parts to allow the model to systematically explore the solution space. To facilitate this, we prompt the model to generate multiple labels that correspond to specific inference steps necessary for the search. For training, we first use the collected hints to find answers through an MCTS guided by a pre-trained value model. Subsequently, we use the generated Q&A pairs to train the actor model and the value model, thus iteratively improving the process.
However, this approach encounters several challenges when scaling up training. First, unlike chess where the search space is relatively well-defined, token generation presents an exponentially larger search space. To address this issue, we set a maximum expansion limit for each node, but this may cause the model to fall into a local optimum. Second, the value model directly affects the quality of the generation as it guides each step of the search process. Training a fine-grained value model is inherently difficult, which makes it difficult to iteratively improve the model. While the core success of AlphaGo relies on training value models to incrementally improve its performance, the principle is difficult to replicate in our setup due to the complexity of marker generation.
In conclusion, while MCTS can improve performance during inference when paired with pre-trained value models, iteratively improving model performance during self-search remains a difficult challenge.
5. Conclusions, limitations and future work
In this paper, we share our process for enhancing model inference through reinforcement learning (RL).DeepSeek-R1-Zero represents a pure RL approach that does not rely on cold-start data and achieves strong performance in a variety of tasks.DeepSeek-R1 is even more powerful in that it utilizes cold-start data and iterative RL fine-tuning. Ultimately, DeepSeek-R1 achieves performance comparable to OpenAI-01-1217 in a variety of tasks.
We further explored distilling reasoning power into small dense models. We used DeepSeek-R1 as a teacher model to generate 800K data and fine-tuned several small dense models. The results are promising: the DeepSeek-R1-Distill-Qwen-1.5B outperforms the GPT-40 and Claude-3.5-Sonnet in math benchmarking, with an AIME score of 28.91 TP3T and a MATH score of 83.91 TP3T.Other dense models also achieve impressive results, significantly outperforming the other instruction fine-tuning models based on the same underlying checkpoints.
In the future, we plan to investigate DeepSeek-R1 in the following areas:
- Generalized Capabilities: Currently, DeepSeek-R1 is less capable than DeepSeek-V3 in tasks such as function calls, multi-round conversations, complex role-playing, and json output.Going forward, we plan to explore how long CoTs can be utilized to augment tasks in these domains.
- Language mixing: DeepSeek-R1 is currently optimized for Chinese and English, which may lead to language mixing issues when processing queries in other languages. For example, DeepSeek-R1 may reason and respond in English even if the query is in a language other than English or Chinese. We aim to address this limitation in a future update.
- Hint engineering: While evaluating DeepSeek-R1, we found that it is sensitive to hints. Less-sample hints consistently degrade its performance. Therefore, we recommend that users describe the problem directly and specify the output format using the zero-sample setting for best results.
- Software Engineering Tasks: Large-scale RL has not yet been widely applied to software engineering tasks due to the long evaluation time, which affects the efficiency of the RL process.As a result, DeepSeek-R1 has not yet shown a huge improvement in performance on software engineering benchmarks over DeepSeek-V3. Future releases will address this issue by implementing rejection sampling on software engineering data or merging asynchronous evaluations in the RL process to improve efficiency.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...