
How do big models get "smarter"? Stanford reveals the key to self-improvement: four cognitive behaviors

The field of Artificial Intelligence has made impressive progress in recent years, especially in the area of Large Language Modeling (LLM). Many models, such as Qwen, have shown an amazing ability to self-check answers and correct errors. However, not all models are equally capable of self-improvement. Given the same extra computational resources and "thinking" time, some models are able to fully utilize these resources and improve their performance dramatically, while others have little success. This phenomenon raises the question: what factors are responsible for this discrepancy?
Just as humans spend more time thinking deeply when confronted with difficult problems, some advanced models of large languages begin to exhibit similar reasoning behavior when trained for self-improvement through reinforcement learning. However, there are significant differences in self-improvement capabilities between models trained with the same reinforcement learning. For example, Qwen-2.5-3B far outperforms Llama-3.2-3B in the Countdown game. Although both models are relatively weak at the initial stage, at the end of the reinforcement learning training, Qwen achieves an accuracy of about 60%, while Llama is only about 30%. What is the hidden mechanism behind this significant gap?
A recent Stanford study has dug deeper into the mechanisms behind the ability of large models to self-improve, revealing that key language models in the underlying cognitive behavior The Importance of. This research provides new perspectives on understanding and enhancing the self-improvement capabilities of AI systems.
The study has been widely discussed upon its release. The CEO of Synth Labs, for one, believes that the discovery is exciting because it promises to be integrated into any model to improve its performance.

Four key cognitive behaviors
In order to investigate the reasons for the differences in self-improvement abilities of the models, the researchers focused on two base models, Qwen-2.5-3B and Llama-3.2-3B. By training them with reinforcement learning in the game of Countdown, the researchers observed significant differences: Qwen's problem solving ability improved significantly, while Llama-3's improvement was relatively limited during the same training process. So, what model attributes are responsible for this difference?

To systematically examine this issue, the research team developed a framework for analyzing cognitive behaviors that are critical to problem solving. The framework describes four key cognitive behaviors:
- Verification:: Systematic error checking.
- Backtracking:: Abandon failed approaches and try new paths.
- Sub-goal Setting:: Break down complex problems into manageable steps.
- Reverse Thinking: Reverse derivation from desired result to initial input.
These patterns of behavior are highly similar to the way expert problem solvers approach complex tasks. For example, mathematicians perform proofs by carefully verifying each step of the derivation; by backtracking to check previous steps when contradictions are encountered; and by breaking down complex theorems into simpler lemmas for step-by-step proofs.

Preliminary analyses indicate that the Qwen model naturally exhibits these inference behaviors, particularly in the areas of validation and backtracking, while the Llama-3 model notably lacks these behaviors. Based on these observations, the researchers formulated the core hypothesis: Certain reasoning behaviors in the initial strategy are critical for the model to effectively utilize the increased test time computation. In other words, if an AI model wants to become "smarter" when it has more "thinking" time, it must first have some basic thinking skills, such as the habit of checking for errors and verifying results. If the model lacks these basic thinking methods from the beginning, even if it is given more thinking time and computational resources, it will not be able to effectively improve its performance. This is very similar to the human learning process - if students lack basic self-checking and error-correction skills, simply taking longer exams will not significantly improve their performance.
Experimental validation: the importance of cognitive behavior
To test the above hypothesis, the researchers conducted a series of clever intervention experiments.
First, they attempted to bootstrap the Llama-3 model using synthetic inference trajectories containing specific cognitive behaviors (especially retrospection). The results show that the Llama-3 model after such bootstrapping exhibits significant improvements in reinforcement learning, with performance gains even comparable to Qwen-2.5-3B.
Second, even if the reasoning trajectories used for bootstrapping contained incorrect answers, the Llama-3 model was still able to make progress as long as these trajectories exhibited correct reasoning patterns. This finding suggests that the The key factor that really drives self-improvement of a model is the presence of reasoning behavior, not the correctness of the answer itself.
Finally, the researchers filtered the OpenWebMath dataset to emphasize these reasoning behaviors and used this data to pretrain the Llama-3 model. The experimental results show that this targeted pre-training data tuning is effective in inducing the inference behavior patterns required for the model to efficiently utilize computational resources. The performance improvement trajectory of the tuned pre-trained Llama-3 model shows a striking consistency with that of the Qwen-2.5-3B model.
The results of these experiments strongly reveal a strong link between a model's initial reasoning behavior and its ability to improve itself. This connection helps explain why some language models are able to efficiently utilize additional computational resources while others stagnate. A deeper understanding of these dynamics is essential for developing AI systems that can significantly improve problem solving.
Countdown game with model selection
The study opens with a surprising observation: language models of similar size, from different model families, show very different performance improvements when trained with reinforcement learning. To explore this phenomenon in depth, the researchers chose the game Countdown as their primary testbed.
Countdown is a math puzzle in which the player needs to combine a given set of numbers to reach a target number using the four basic operations of addition, subtraction, multiplication and division. For example, given the numbers 25, 30, 3, 4 and a target number of 32, the player needs to obtain the exact number 32 through a series of operations, e.g. (30 - 25 + 3) × 4 = 32.
The Countdown game was chosen for this study because it examines the mathematical reasoning, planning, and search strategy capabilities of the model, while providing a relatively constrained search space that allows researchers to conduct in-depth analyses. Compared to more complex domains, the Countdown game reduces the difficulty of analysis while still effectively examining complex reasoning. In addition, the success of Countdown relies more on problem solving skills than on pure mathematical knowledge than on other mathematical tasks.
The researchers chose two base models, Qwen-2.5-3B and Llama-3.2-3B, to compare the learning differences between the different model families. The reinforcement learning experiments were based on the VERL library and implemented using TinyZero. They use the PPO (Proximal Policy Optimization) algorithm to train the model for 250 steps, sampling 4 trajectories per cue. The reason for choosing the PPO algorithm is that, in comparison to the GRPO and other reinforcement learning algorithms such as REINFORCE, PPO shows better stability under various hyperparameter settings, although the overall performance difference between the different algorithms is not significant. (Editor's note: It is suspected that the original "GRPO" is a clerical error and should read PPO.)
The experimental results reveal very different learning trajectories for the two models. Although both perform similarly at the beginning of the task, with low scores, Qwen-2.5-3B shows a "qualitative leap" around the 30th step of training, as evidenced by the significantly longer responses generated by the model, and a significant increase in accuracy. At the end of training, Qwen-2.5-3B achieves an accuracy of about 601 TP3T, which is much higher than the 301 TP3T of Llama-3.2-3B.
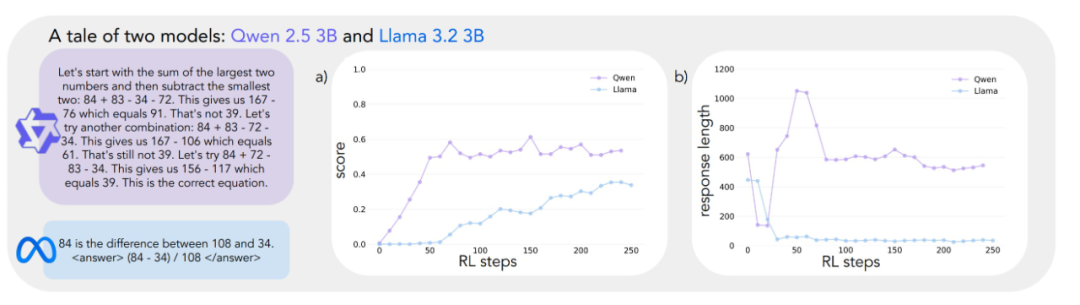
Later in training, the researchers observed an interesting shift in Qwen-2.5-3B's behavior: the model gradually transitioned from using explicit validation statements (e.g., "8*35 is 280, too high") to implicit solution checking. The model последовательно (Russian for "последовательно land" or "sequentially") tries out different solutions until it finds the right one, and no longer evaluates its own work using words. The contrast is striking. This contrast leads to a central question: what are the underlying capabilities that allow a model to successfully realize self-improvement based on reasoning? Answering this question requires a systematic framework for analyzing cognitive behavior.
Cognitive Behavioral Analysis Framework
In order to gain a deeper understanding of the very different learning trajectories of the two models, the researchers developed a framework for identifying and analyzing key cognitive behaviors in the model outputs. The framework focuses on four basic behaviors:
- Backtracking: Explicitly modify the method when an error is detected (e.g., "This method won't work because ..."). .").
- Verification: Systematically check intermediate results (e.g., "Let's validate this result by ... to verify this result").
- Sub-goal Setting: Break down complex problems into manageable steps (e.g., "To solve this problem, we first need to ..."). .
- Reverse Thinking: In goal-directed reasoning problems, start with a desired outcome and work backwards to find a path to the solution (e.g., "To reach the goal of 75, we need a number that can be divided by ..."). to reach the goal of 75, we need a number that is divisible by ...").
These behaviors were chosen because they represent problem-solving strategies that are very different from the linear, monotonic reasoning patterns common in language models. These cognitive behaviors enable more dynamic, search-like reasoning trajectories, where solutions can evolve in a non-linear fashion. While this set of behaviors is not exhaustive, the researchers chose them because they are easy to identify and fit naturally with human problem-solving strategies in Countdown games and in broader mathematical reasoning tasks, such as the construction of mathematical proofs.
Each cognitive behavior can be understood through its role in reasoning the token For example, backtracking is characterized by explicitly negating and replacing token sequences of previous steps. For example, backtracking is manifested as a sequence of tokens that explicitly negate and replace previous steps; validation is manifested as generating tokens that compare results to solution criteria; backtracking is manifested as constructing tokens that incrementally build solution paths to the initial state from the goal; and subgoal setting is manifested as explicitly suggesting intermediate steps to be achieved along the path to the final goal. The researchers developed a classification pipeline using the GPT-4o-mini model that reliably identifies these patterns in the model output.
The effect of initial behavior on self-improvement
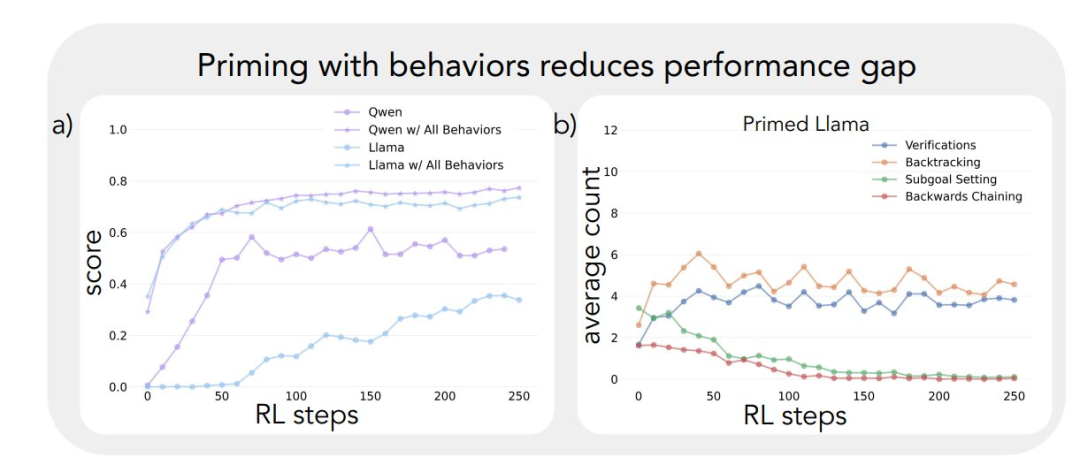
Applying the above analytical framework to the initial experiments yielded a key insight: The significant improvement in the performance of the Qwen-2.5-3B model occurs in parallel with the emergence of cognitive behaviors, especially verification and backtracking behaviors. In contrast, the Llama-3.2-3B model showed few signs of these behaviors throughout training.
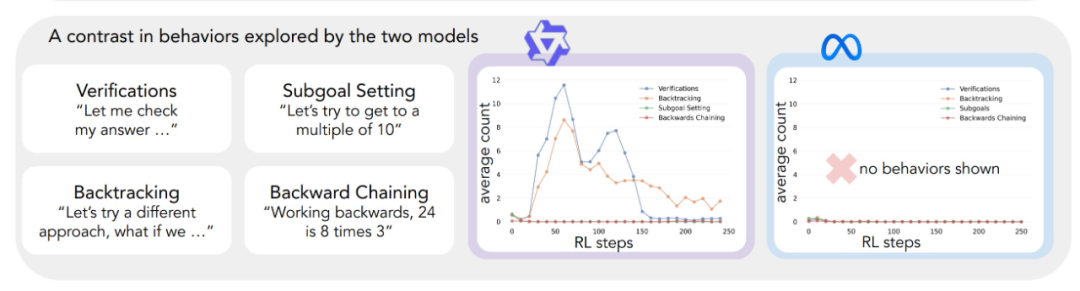
In order to gain a deeper understanding of this difference, the researchers further analyzed the baseline reasoning patterns of the three models: Qwen-2.5-3B, Llama-3.2-3B, and Llama-3.1-70B. The results of the analyses showed that the Qwen-2.5-3B model produced a higher proportion of all cognitive behaviors than the two Llama model variants, Llama-3.2-3B and Llama-3.1-70B. 2.5-3B model produced a higher proportion of all cognitive behaviors. Although the larger Llama-3.1-70B model generally activated these behaviors more frequently than the Llama-3.2-3B model, this increase was uneven, especially for retrospective behaviors, which remained limited even in the larger model.

These observations reveal two important insights:
- The presence of certain cognitive behaviors in the initial strategy may be a prerequisite necessary for the model to effectively utilize the increased test time computation by extending the inference sequence.
- Increasing the model size can improve the frequency of contextual activation of these cognitive behaviors to some extent.
This model is critical because reinforcement learning can only amplify behaviors that are already present in successful trajectories. This means that the initial availability of these cognitive-behavioral capabilities is a prerequisite for effective learning in the model.
Intervening in initial behavior: guiding model learning
Having established the importance of the cognitive behaviors in the base model, the next question is: Can these behaviors be artificially induced in the model through targeted interventions? The researchers hypothesized that by creating variants of the base model that selectively display specific cognitive behaviors prior to reinforcement learning training, they could gain a deeper understanding of which behavioral patterns are critical for effective learning.
To test this hypothesis, they first designed seven different starter datasets using the Countdown game. Five of these datasets emphasized different combinations of behaviors: all strategy combinations, backtracking only, backtracking and validation, backtracking and subgoal setting, and backtracking and backwards thinking. They used the Claude-3.5-Sonnet model to generate these datasets because of Claude-3.5-Sonnet's ability to generate inference trajectories with precisely specified behavioral characteristics.
In order to verify that the performance gains were due to specific cognitive behaviors and not simply an increase in computation time, the researchers also introduced two control conditions: an empty Chain of Thought and a control condition that populated the chain of placeholder tokens and matched the length of the data points to the "all strategy combinations" dataset. " dataset. These control datasets helped the researchers verify that any observed performance improvements were indeed due to specific cognitive behaviors, rather than just an increase in computation time.
In addition, the researchers created a variant of the "Full Strategy Combination" dataset, which contains only incorrect solutions, but retains the required reasoning patterns. The purpose of this variant is to distinguish the difference between the importance of cognitive behavior and the accuracy of solutions.
Experimental results show that both the Llama-3 and Qwen-2.5-3B models exhibit significant performance improvements through reinforcement learning training when initialized with a dataset containing retrospective behavior. Behavioral analysis further shows that Reinforcement learning selectively amplifies behaviors that have been empirically proven to be useful while inhibiting other behaviors. For example, in the Full Strategy Combination condition, the model retains and enhances retrospective and validation behaviors, while decreasing the frequency of backtracking and subgoal-setting behaviors. However, when paired only with retrospective behaviors, suppressed behaviors (e.g., backward thinking and subgoal setting) persist throughout training.
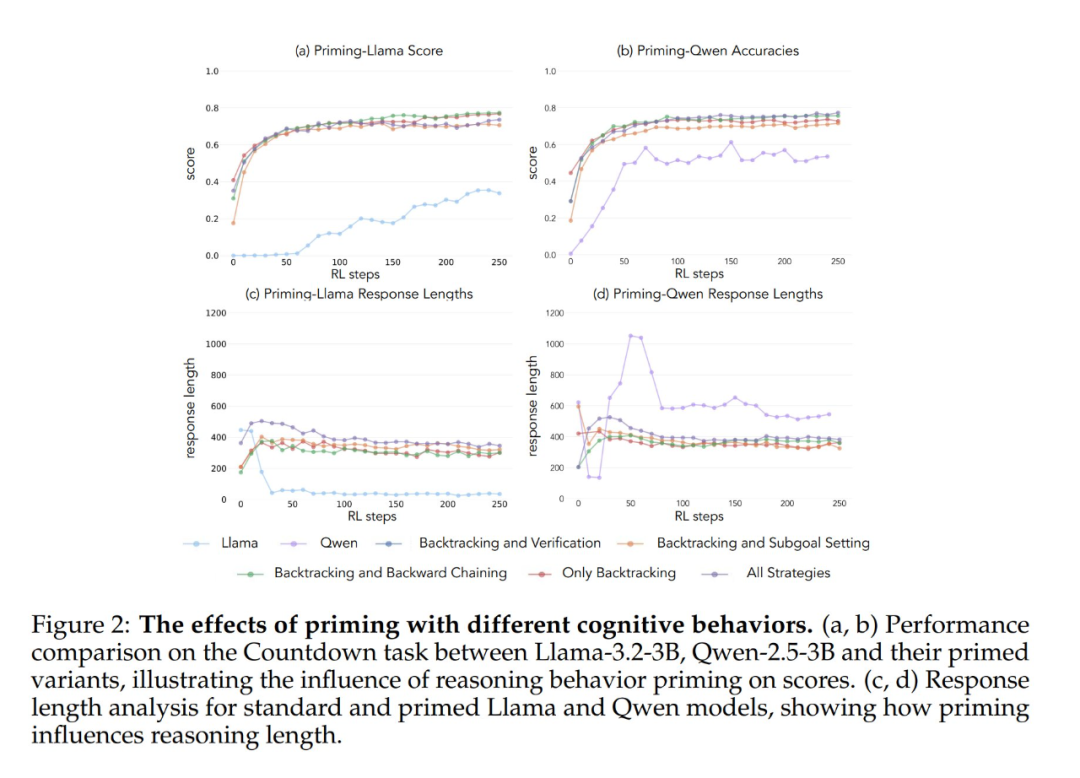
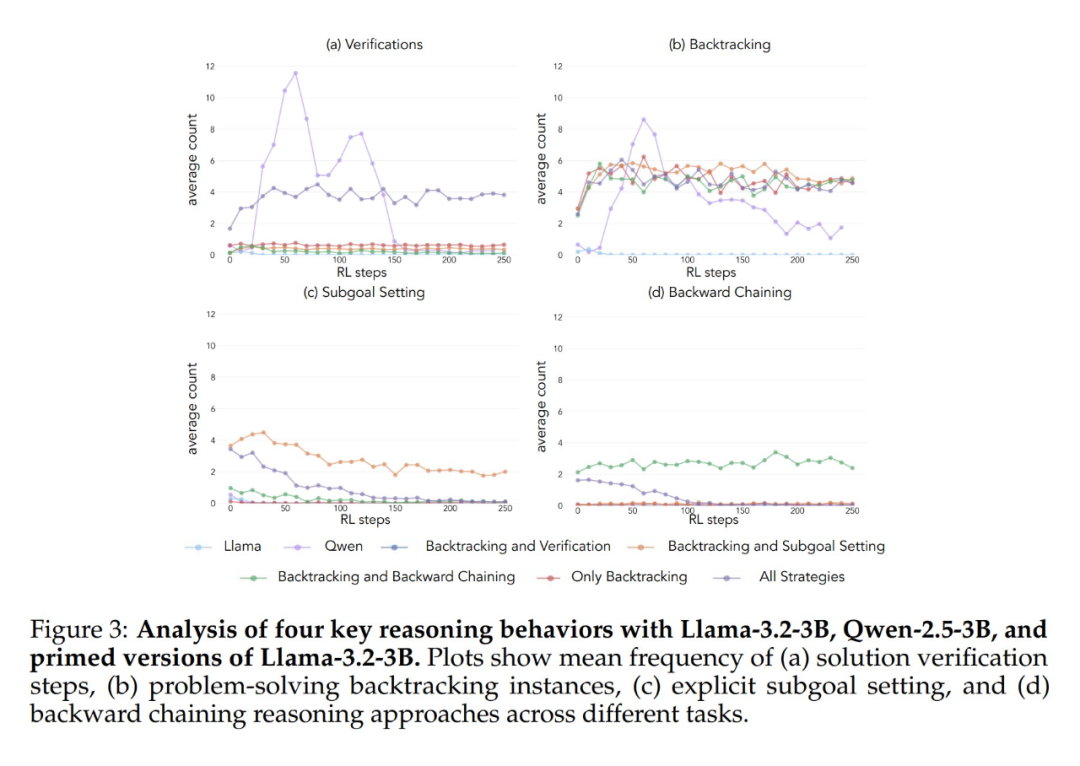
When initiated using an empty thought chain as a control condition, both models performed comparably to the basic Llama-3 model (accuracies of approximately 30%-35%). This suggests that simply assigning additional tokens without including cognitive behaviors is not an efficient use of test time computation. Even more surprisingly, training with an empty thought chain even had a detrimental effect, as the Qwen-2.5-3B model stopped exploring new behavioral patterns. This is further evidence that These cognitive behaviors are crucial for the model to efficiently utilize extended computational resources through longer inference sequences.
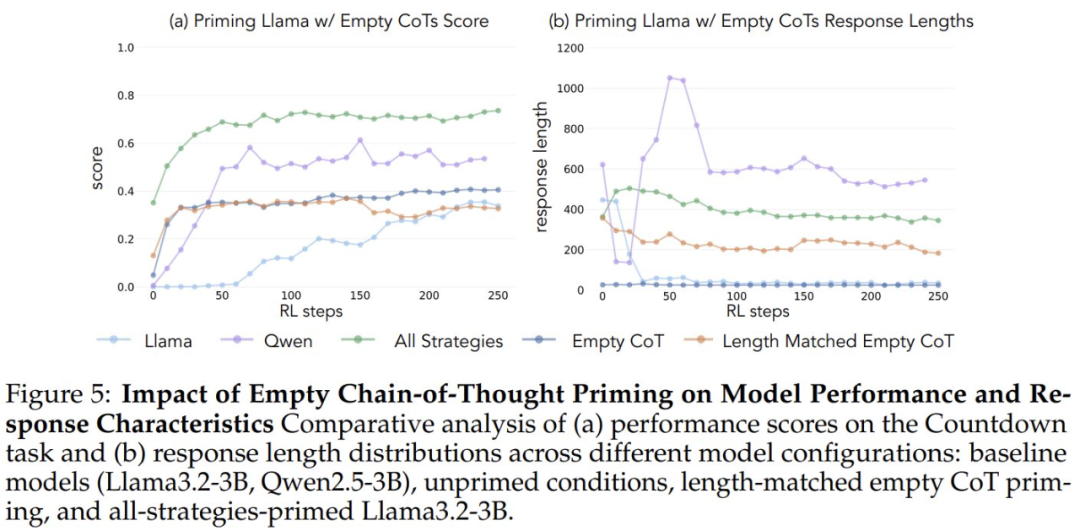
Even more surprisingly, models initialized with incorrect solutions, but with correct cognitive behaviors, achieved almost the same level of performance as models trained on datasets containing correct solutions. This result strongly suggests that The presence of cognitive behaviors (not the acquisition of correct answers) is a key factor in successful self-improvement through reinforcement learning. Thus, reasoning patterns from relatively weak models can effectively guide the learning process to build stronger models. This proves once again that The presence of cognitive behavior is more important than the correctness of the outcome.

Behavioral selection in pre-trained data
The results of these experiments suggest that certain cognitive behaviors are essential for model self-improvement. However, the methods used to induce specific behaviors in the initial models in the previous study were domain-specific and relied on Countdown games. This may adversely affect the generalization ability of the final inference. So, is it possible to increase the frequency of beneficial inference behaviors by modifying the model's pre-training data distribution to achieve a more generalized self-improvement capability?
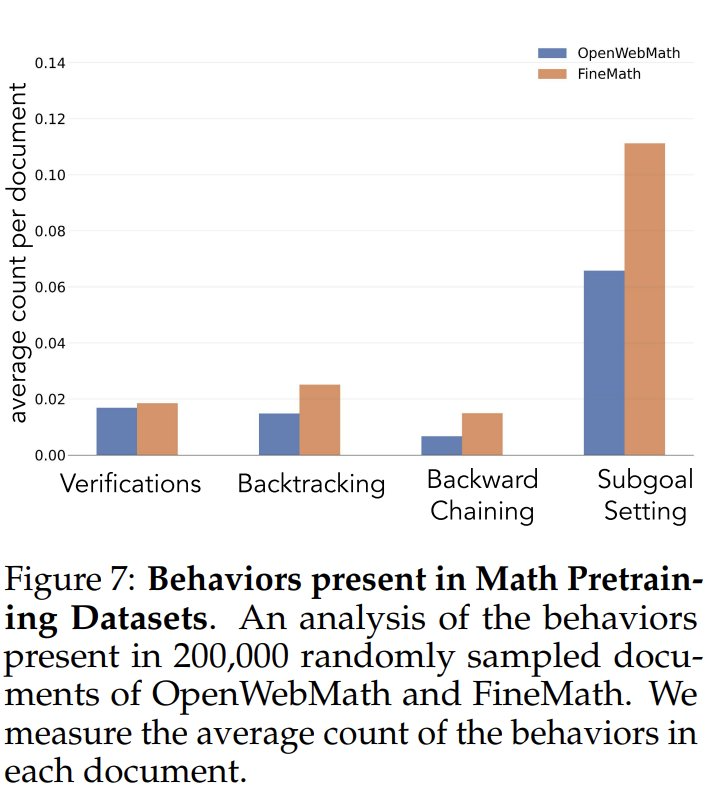
To investigate the frequency of cognitive behaviors in the pretraining data, the researchers first analyzed the natural frequencies of cognitive behaviors in the pretraining data. They focused on the OpenWebMath and FineMath datasets, which were built specifically for mathematical reasoning. Using the Qwen-2.5-32B model as a classifier, the researchers analyzed 200,000 randomly selected documents from these two datasets for the presence of the target cognitive behavior. The results showed that even in these math-focused corpora, the frequency of cognitive behaviors such as backtracking and validation remained low. This suggests that standard pre-training processes have limited exposure to these key behavioral patterns.
In order to test whether artificially increasing exposure to cognitive behaviors enhances a model's self-improvement potential, the researchers developed a targeted continuous pre-training dataset from the OpenWebMath dataset. They first used the Qwen-2.5-32B model as a classifier to analyze mathematical documents from the pre-training corpus to identify the presence of target reasoning behaviors. Based on this, they created two comparison datasets: one rich in cognitive behaviors and a control dataset with very little cognitive content. They then used the Qwen-2.5-32B model to rewrite each document in both datasets into a structured question-and-answer format, while preserving the natural presence or absence of cognitive behaviors in the source documents. The final pre-training datasets each contained a total of 8.3 million tokens. This approach allowed the researchers to effectively isolate the effects of reasoning behavior while controlling the format and amount of mathematical content during pre-training.
After pre-training the Llama-3.2-3B model on these datasets and applying reinforcement learning, the researchers observed:
- Behaviorally enriched pre-trained models ultimately achieve a level of performance comparable to that of the Qwen-2.5-3B model, with relatively limited improvement in the performance of the control model.
- Behavioral analysis of the post-training models showed that the behaviorally rich pre-trained model variants maintained high activation of inference behavior throughout the training process, while the control model exhibited behavioral patterns similar to those of the basic Llama-3 model.
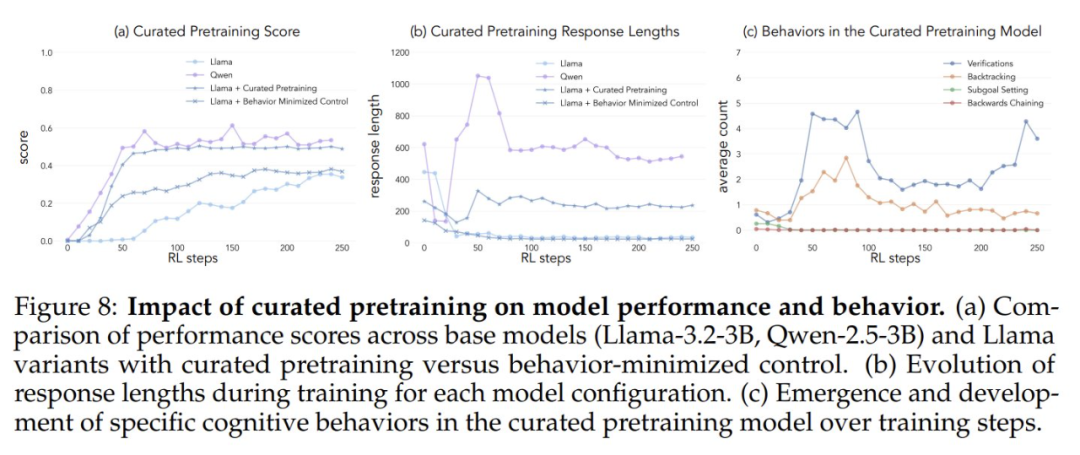
The results of these experiments strongly suggest that Targeted modification of pre-training data can successfully generate key cognitive behaviors necessary for effective self-improvement through reinforcement learning. This study provides new ideas and methods for understanding and improving the self-improvement capabilities of large language models. For more details, please refer to the original paper.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...