Crawl4AI: open source asynchronous web crawler tool to extract structured data without LLM

General Introduction
Crawl4AI is an open source asynchronous web crawler tool designed for large-scale language models (LLMs) and artificial intelligence (AI) applications. It simplifies the web crawling and data extraction process , supports efficient web crawling and provides LLM-friendly output formats such as JSON, cleaned HTML and Markdown.Crawl4AI supports crawling multiple URLs at the same time , completely free and open source , suitable for a variety of data crawling needs.
Function List
- Asynchronous architecture: efficient processing of multiple web pages, fast data crawling
- Multiple Output Formats: Support JSON, HTML, Markdown
- Multi-URL crawling: crawl multiple web pages at the same time
- Media tag extraction: extract image, audio and video tags
- Link extraction: extract all external and internal links
- Metadata extraction: extracting metadata from pages
- Custom hooks: support for authentication, request headers and page modifications
- User agent customization: custom user agents
- Page Screenshot: Screenshot of the crawl page
- Execute custom JavaScript: Execute multiple custom JavaScripts before crawling
- Proxy Support: Enhancing Privacy and Access
- Session management: handling complex multi-page crawling scenarios
Using Help
Installation process
Crawl4AI offers flexible installation options for a variety of usage scenarios. You can install it as a Python package or use Docker.
Installation with pip
- Basic Installation
pip install crawl4aiThis will install the asynchronous version of Crawl4AI by default, using Playwright for web crawling.
- Manual installation of Playwright (if required)
playwright installor
python -m playwright install chromium
Installing with Docker
- Pulling a Docker image
docker pull unclecode/crawl4ai - Running a Docker Container
docker run -it unclecode/crawl4ai
Guidelines for use
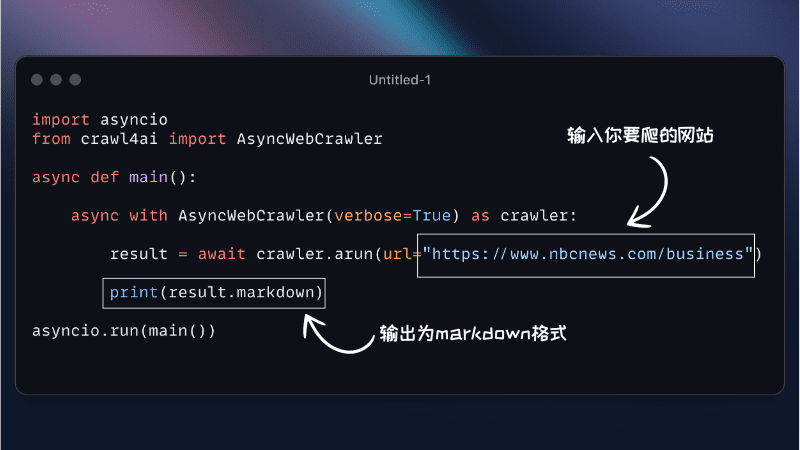
- Basic use
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - Customized settings
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - Extracting specific data
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - Session Management
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI offers a rich set of features and flexible configuration options for a variety of web crawling and data crawling needs. With a detailed installation and usage guide, users can easily get started and take full advantage of the tool's powerful features.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...