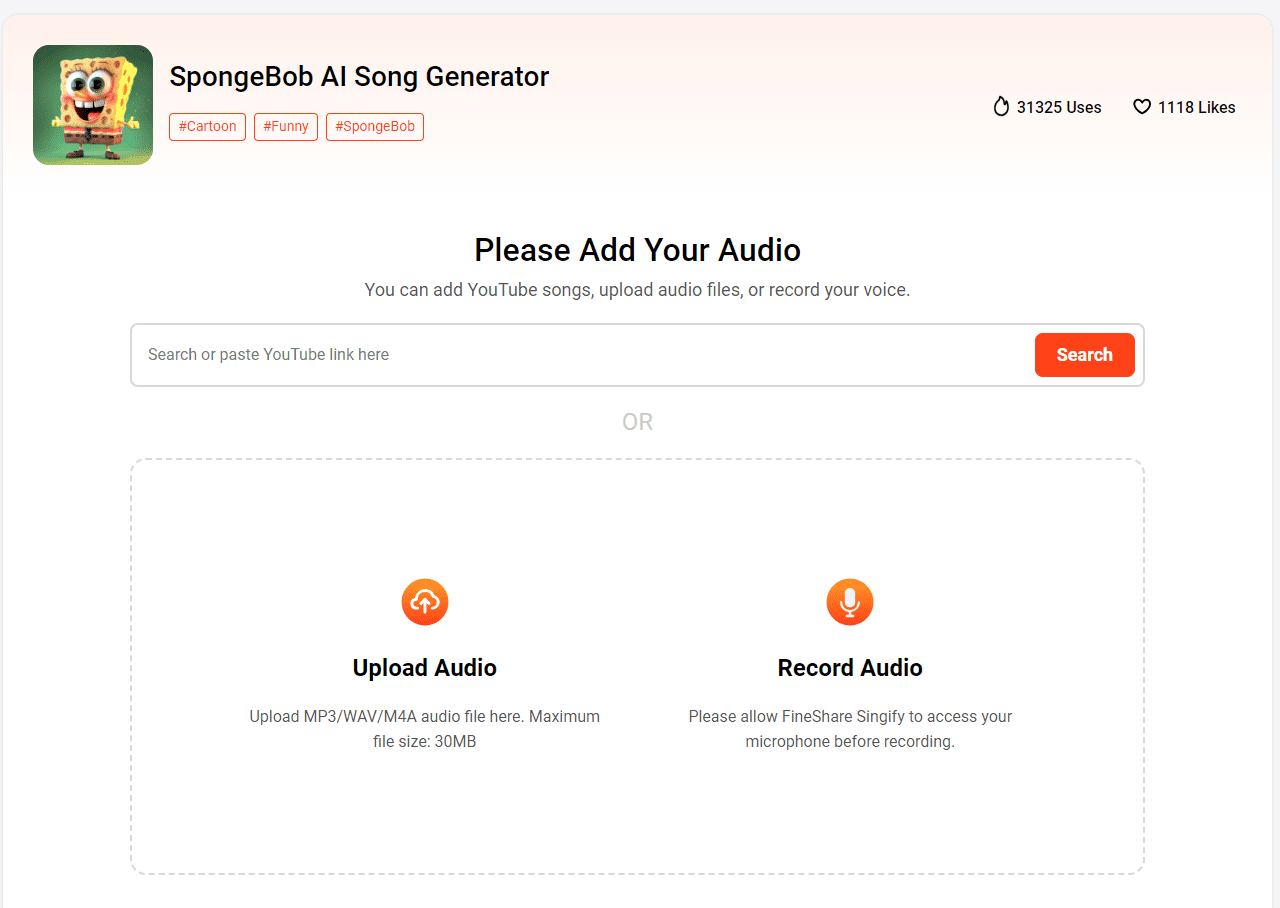
CogView3: Wisdom Spectrum Light Word open source cascade diffusion text to generate image models

General Introduction
CogView3 is an advanced text generation image system developed by Tsinghua University and Think Tank Team (Chi Spectrum Qingyan). It is based on the cascading diffusion model and generates high-resolution images through multiple stages.The main features of CogView3 include multi-stage generation, innovative architecture and efficient performance, which are applicable to many fields such as art creation, advertisement design, game development, and so on.
The capabilities of this series of models are now online at "Smart Spectrum Clear Words" (chatglm.cn) and can be experienced on Clear Words.


Top: A pink colored car. Bottom: A stack of 3 cubes. A red cube is on the top, sitting on a red cube. The red cube is in the middle, sitting on a green cube. The green cube is on the bottom.
Function List
- Multi-stage generation: First generate low-resolution images, then gradually increase the image resolution through a relay diffusion process, and finally generate high-resolution images up to 2048x2048.
- Efficient Performance: CogView3 significantly reduces training and inference costs while generating high quality images. Compared to SDXL, the current state-of-the-art open source model, CogView3's inference time is only 1/10th of that of SDXL.
- Innovative Architecture: CogView3 introduces the latest DiT (Diffusion Transformer) architecture, which utilizes Zero-SNR diffusion noise scheduling and combines the text-image joint attention mechanism to further improve the overall performance.
- Open source code: The code and model of CogView3 have been open sourced on GitHub and can be freely downloaded and used by users.
Using Help
Installation and Registration
- Visit the website: Open the official CogView3 website. GitHubThe
- Download Code : Click the "Code" button on the page and select "Download ZIP" to download the project file, or use the git command to download it:
git<span> </span>clone<span> </span>https://github.com/THUDM/CogView3.gitThe - Install dependencies: Ensure that the diffusers library is installed from source:
pip install git+https://github.com/huggingface/diffusers.git
Usage Process
- Cue Optimization :
- Although the CogView3 family of models is trained with long image descriptions, we strongly recommend rewriting the cues using Large Language Models (LLMs) before generating text to images, which will significantly improve the quality of the generation.
- Run the following script to optimize the prompt:
python prompt_optimize.py --api_key "Zhipu AI API Key"--prompt {your prompt} --base_url "https://open.bigmodel.cn/api/paas/v4"--model "glm-4-plus"
- Reasoning Models (Diffusers) :
- First, make sure you install the diffusers library from source:
pip install git+https://github.com/huggingface/diffusers.git - Then, run the following code:
fromdiffusers importCogView3PlusPipeline importtorch pipe = CogView3PlusPipeline.from_pretrained("THUDM/CogView3-Plus-3B", torch_dtype=torch.float16).to("cuda") pipe.enable_model_cpu_offload() pipe.vae.enable_slicing() pipe.vae.enable_tiling() prompt = "A vibrant cherry red sports car sits proudly under the gleaming sun, its polished exterior smooth and flawless, casting a mirror-like reflection. The car features a low, aerodynamic body, angular headlights that gaze forward like predatory eyes, and a set of black, high-gloss racing rims that contrast starkly with the red. A subtle hint of chrome embellishes the grille and exhaust, while the tinted windows suggest a luxurious and private interior. The scene conveys a sense of speed and elegance, the car appearing as if it's about to burst into a sprint along a coastal road, with the ocean's azure waves crashing in the background." image = pipe( prompt=prompt, guidance_scale=7.0, num_images_per_prompt=1, num_inference_steps=50, width=1024, height=1024, ).images[0] image.save("cogview3.png")
- First, make sure you install the diffusers library from source:
- Reasoning Model (SAT) :
- Refer to the SAT tutorial for step-by-step model reasoning instructions.
common problems
- Installation Failure: Make sure the Python version meets the requirements, and pay attention to version compatibility when installing PyTorch.
- Image quality : The specificity of the text description and the richness of the training dataset will affect the results of the generated images, it is recommended to use detailed text description and diverse datasets for training.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...