
Baichuan Intelligence Releases Baichuan-Omni-1.5 Omnimodal Large Model, Surpassing GPT-4o Mini in Several Measurements

Toward the end of the year, the domestic large model field again spread good news. BCinks Intelligence recently released a number of large model products, following theFull-scene deep inference model Baichuan-M1-previewcap (a poem)Medical enhancement open source model Baichuan-M1-14BThis was followed by the relaunch of theFull modal model Baichuan-Omni-1.5The
Baichuan-Omni-1.5 is known as "Big Model Generalist", which marks the significant progress of domestic big model in multimodal fusion technology.Baichuan-Omni-1.5 is equipped with excellent all-modal understanding and generating capability, which is not only capable of simultaneously handlingText, images, audio, videoand other multimodal information, and more support forText and AudioBimodal content generation.
At the same time, Baichuan Intelligence has also open-sourcedOpenMM-Medicalcap (a poem)OpenAudioBenchThe two high-quality evaluation datasets aim to promote the prosperous development of the domestic all-modal modeling technology ecosystem. According to the comprehensive evaluation results that have been made public, Baichuan-Omni-1.5 in a number of multimodal capabilitiesOverall performance exceeds that of the GPT-4o Mini, especially in the medical field where BCinks Intelligence continues to specialize in, itsMedical image review scores have achieved even more significant leadsThis fully demonstrates the strong strength and determination of BCinks Intelligence as a leading enterprise in the field of domestic large model. This fully demonstrates Baichuan Intelligence, as a leading enterprise in the field of domestic large model, the strong strength and firm determination in technological innovation and industry application landing.
Model weight address:
Baichuan-Omini-1.5: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5 https://modelers.cn/models/Baichuan/Baichuan-Omni-1d5
Baichuan-Omini-1.5-Base: https://huggingface.co/baichuan-inc/Baichuan-Omni-1d5-Base https://modelers.cn/models/Baichuan/Baichuan- Omni-1d5-Base
GitHub address: https://github.com/baichuan-inc/Baichuan-Omni-1.5
Technical report: https://github.com/baichuan-inc/Baichuan-Omni-1.5/blob/main/baichuan_omni_1_5.pdf
01 . Comprehensive breakthrough in multimodal capabilities: outstanding performance in text, graphic, audio and video processing evaluation
The performance highlights of the Baichuan-Omni-1.5 can be summarized as "Comprehensive capabilities and high performance". The most notable feature of the model is itscomprehensivelys multimodal comprehension and generation capabilities, specifically, it not only comprehends multimodal content such as text, images, video, and audio, but also supports bimodal generation of text and audio.
In terms of image understanding, according to the test results on common image evaluation benchmarks such as MMBench-dev, TextVQA val, etc., Baichuan-Omni-1.5 performsBetter than GPT-4o Mini. Of particular interest is the fact that, in addition to the general capabilities, BCinks Intelligence's all-modal model is particularly prominent in the healthcare vertical. InMedical Image Review Dataset Reviews on GMAI-MMBench and Openmm-Medical have shown that Baichuan-Omni-1.5's capabilities in medical image understanding have beenSignificantly outperforms GPT-4o MiniThe
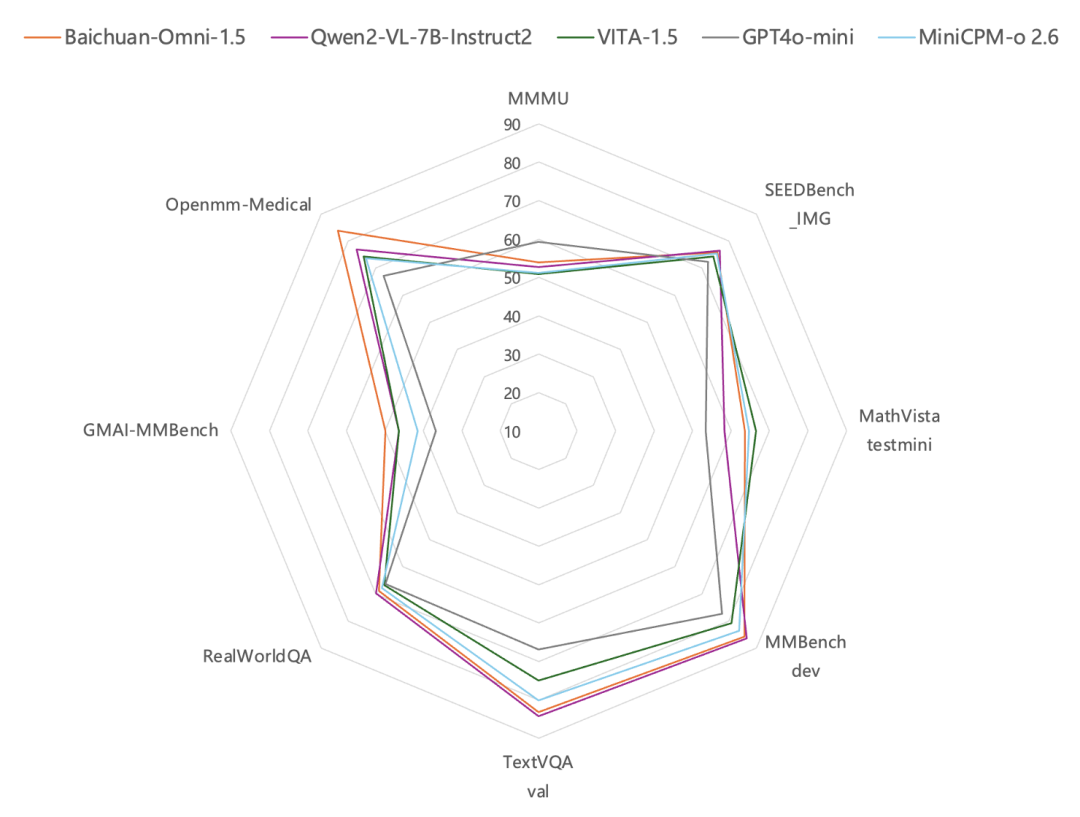
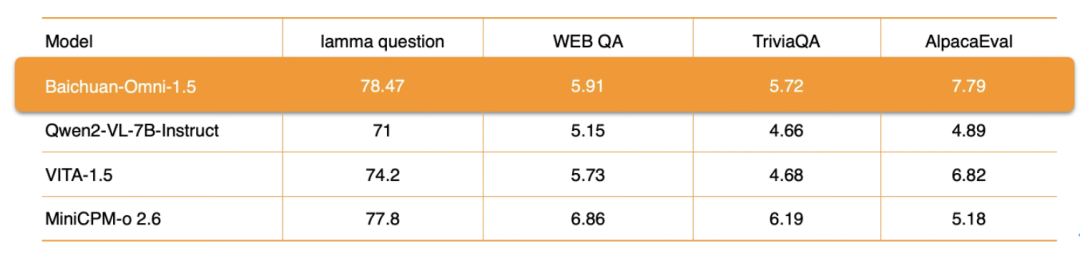
In terms of audio processing, Baichuan-Omni-1.5 not only supports themultilingual dialogIt also relies on its end-to-end audio synthesis capabilities, integrating the ASR (Automatic Speech Recognition) cap (a poem) TTS (text-to-speech) functions. Going a step further, the model also supports the implementation of theAudio-video real-time interaction. In terms of specific performance metrics, the overall performance of Baichuan-Omni-1.5 on datasets such as lamma question and AlpacaEvalsignificantly better than Qwen2-VL-2B-Instruct, VITA-1.5 and MiniCPM-o 2.6 are comparable models.
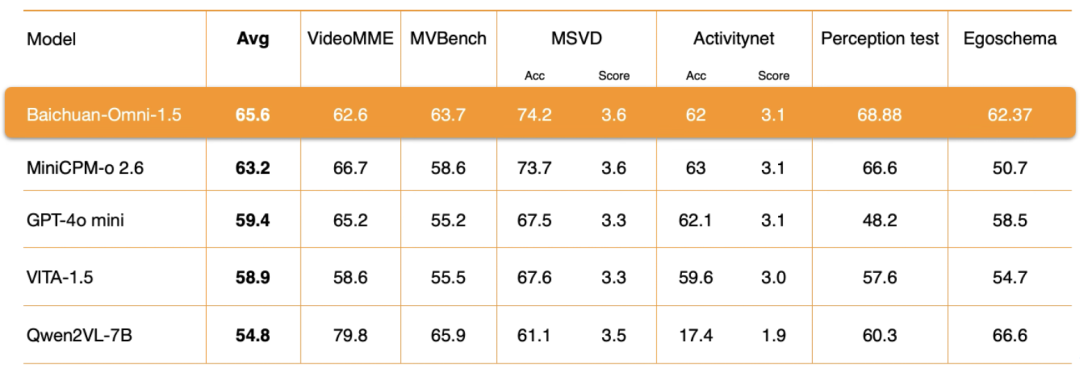
Video comprehensionAt the level of Baichuan-Omni-1.5, Baichuan Intelligence has carried out in-depth optimization in several key aspects such as encoder architecture, training data quality and training method strategy. The evaluation results show that its video understandingOverall performance is also significantly ahead of the GPT-4o-miniThe
In summary, Baichuan-Omni-1.5 not only surpasses GPT4o-mini in terms of general-purpose capability as a whole, but more importantly realizes theUnification of holomodal understanding and generationthat lays the foundation for building more generalized AI systems.
In order to further promote the progress of multimodal modeling research, Baichuan Intelligence has open-sourced two professional review datasets:OpenMM-Medical and OpenAudioBench. Among them OpenMM-Medical data setDesigned to evaluate model performance in medical multimodal tasksIt integrates data from 42 publicly available medical image datasets, such as ACRIMA (fundus images), BioMediTech (microscopy images) and CoronaHack (X-rays), totaling 88,996 images.
Download Address:
https://huggingface.co/datasets/baichuan-inc/OpenMM_Medical
OpenAudioBench then it is aA Comprehensive Rubric for Efficiently Assessing Modeled Audio Comprehension SkillsIt contains 5 sub-assessment sets for audio end-to-end understanding, 4 of which are derived from public assessment datasets (Llama Question, WEB QA, TriviaQA, AlpacaEval), and the other one is a self-constructed speech logical reasoning assessment set by Baichuan Intelligence, which contains 2,701 pieces of data.
Download Address:
https://huggingface.co/datasets/baichuan-inc/OpenAudioBench
BCinks Intelligence has been actively participating in and promoting the construction and prosperity of the domestic open source ecosystem. The open source evaluation dataset provides researchers and developers with a unified and standardized evaluation tool, which helps to conduct objective and fair comparative analysis of the performance of different multimodal models, thus promoting the innovative development of new-generation language understanding algorithms and model architectures.
02 . Comprehensive technology optimization: data, architecture and process synergy to break through the bottleneck of multimodal models
From the early development of unimodal models to multimodal fusion, and then to today's all-modal models, this technological evolutionary journey has expanded a broader space for the application of AI technology in all walks of life. However, with the in-depth development of AI technology, theHow to effectively realize the unification of comprehension and generation in multimodal models has become a key hotspot and technical difficulty in the current research in the field of multimodalityThe
On the one hand, the unity of comprehension and generation is the key to simulate the natural interaction of human beings, to realize more natural and efficient human-machine communication, and an important link to general artificial intelligence (AGI); on the other hand, there are significant differences between different modal data in terms of feature representations, data structures, and semantic connotations, etc., so how to effectively extract multimodal features and realize effective interaction and fusion of cross-modal information is recognized as one of the one of the biggest challenges facing all-modal model training.
The release of Baichuan-Omni-1.5 shows that Baichuan Intelligence has made significant progress in solving the above technical problems and explored an effective technical path. In order to overcome the common problem of "intellectual degradation" in the training of omnimodal models, Baichuan's research team has carried out in-depth optimization of the whole process from the design of the model structure, optimization of the training strategy and the construction of the training data in multiple dimensions, and ultimately achieved effective unification of comprehension and generation.
first inmodel structureOn the other hand, the input layer of Baichuan-Omni-1.5 supports a variety of modal data, which are fed into the large-scale language model for processing through the corresponding Encoder/Tokenizer; on the output layer, the model adopts a text-audio interleaved output design, which can simultaneously generate both text and audio content through the Text Tokenizer and Audio Decoder. In the output layer, the model adopts a text-audio interleaved output design, through which both text and audio modalities can be generated simultaneously. The Audio Tokenizer is based on the OpenAI open source speech recognition and translation model. Whisper The model is incrementally trained to provide advanced semantic extraction and high-fidelity audio reconstruction. In order to enable the model to handle images with different resolutions, Baichuan-Omni-1.5 introduces the NaViT model, which supports image inputs up to 4K resolution and multi-image inference, thus ensuring that the model can fully capture the image information and accurately understand the image content.
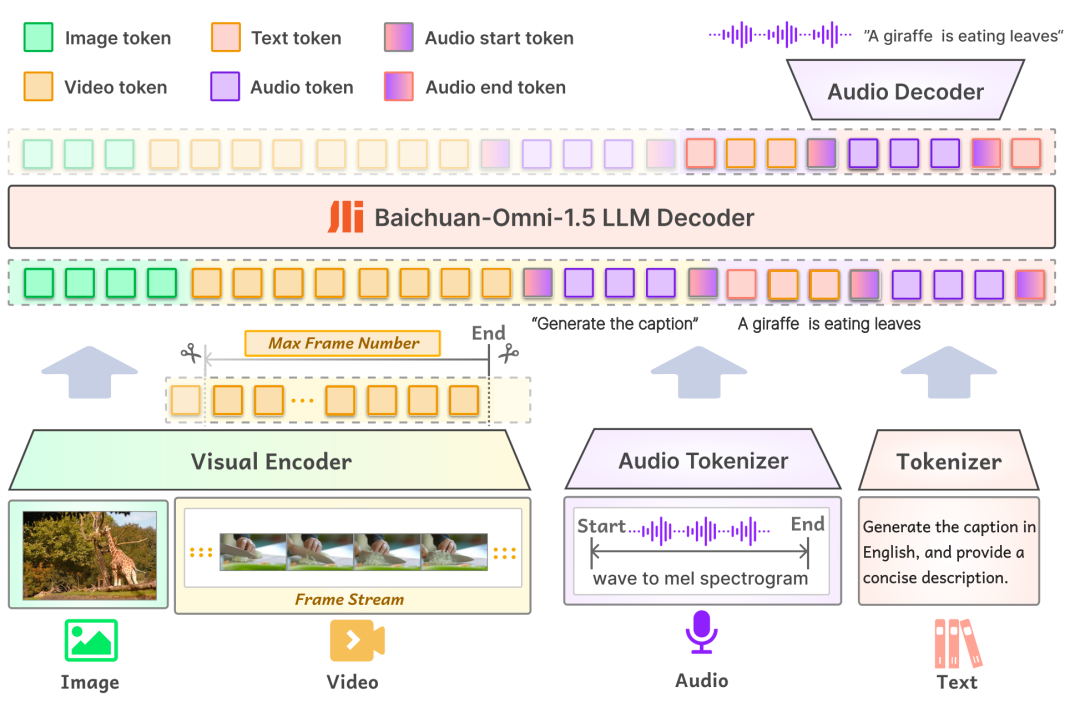
Secondly, inData levelBCI has constructed a massive database containing 340 million high-quality image/video-text data and nearly 1 million hours of audio data, from which 17 million pieces of full-modal data have been selected for the SFT (supervised fine-tuning) phase of the model. Unlike the data composition of traditional models, the training of omnimodal models requires not only a large data size, but also a diversity of data types and inter-modality. In the real world, information is usually presented as a fusion of multiple modalities, and data of different modalities contain complementary information, and the effective fusion of multimodal data helps the model learn more general patterns and laws, thus improving the generalization ability of the model. This is also one of the key elements in building high-performance all-modal models.
In order to enhance the model's cross-modal comprehension ability, Baichuan Intelligence constructed high-quality visual-audio-text interleaved data and trained the model with alignment using 16 million graphic data, 300,000 plain text data, 400,000 audio data, as well as the cross-modal data mentioned above. In addition, in order to enable the model to simultaneously perform diverse audio tasks such as ASR, TTS, tone switching, and audio end-to-end Q&A, the research team also constructed data samples related to these tasks specifically in the aligned data.
The third key technology point isTraining processThe optimized design of the model is the core link to ensure that high-quality data can effectively improve the performance of the model. BCinks Intelligence adopts a multi-stage training program in both the pre-training and SFT phases to comprehensively improve the model's effect. The training process is divided into four phases: the first phase is based on graphic data training; the second phase adds audio data for pre-training; the third phase introduces video data for training; and the last phase is the multimodal alignment phase, which ultimately enables the model to have the ability to comprehensively comprehend all-modal content.
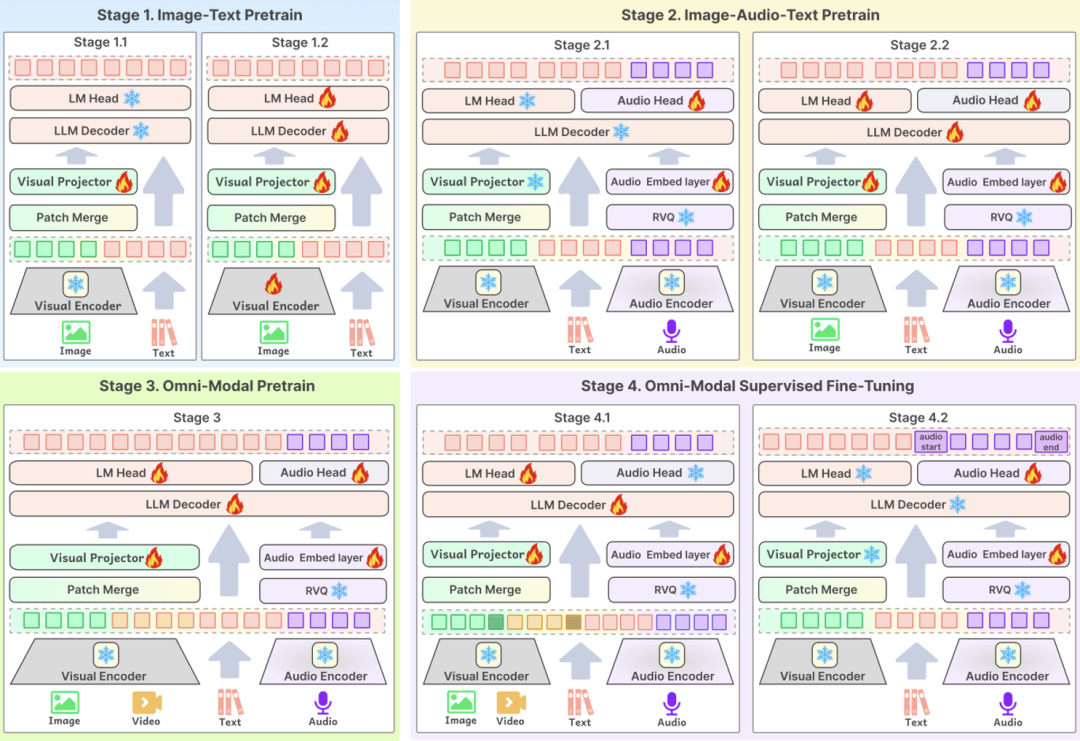
Based on the above all-round technical optimization, the overall capability of Baichuan-Omni-1.5 has been significantly improved compared with traditional single-modal large language models or multimodal models. the release of Baichuan-Omni-1.5 is not only another important milestone in Baichuan Intelligence's technological research and development, but also signifies that the center of development of artificial intelligence is shifting from focusing on the enhancement of the basic capability of models to the acceleration of practical applications.
Previously, the capability enhancement of the large model mainly focused on basic capabilities such as language understanding and image recognition, while Baichuan-Omni-1.5's powerful multimodal fusion capability will help the technology realize a closer integration with practical application scenarios. By enhancing the model's comprehensive capabilities in multimodal information processing, such as language, vision, audio, etc., Baichuan-Omni-1.5 is able to effectively respond to more complex and diverse practical application tasks. For example, in the medical industry, the powerful comprehension and generation capabilities of the omnimodal model can be used to assist doctors in disease diagnosis and improve the accuracy and efficiency of diagnosis, which is an important exploration value for promoting the in-depth application of AI technology in the medical field. Looking ahead, the release of Baichuan-Omni-1.5 may be the beginning of the application of AI technology in the medical and healthcare fields in the AGI era, and we have reason to expect that AI will play a greater role in the medical and other fields in the near future, profoundly changing our lives.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...