Baichuan-Audio: an end-to-end audio model supporting real-time voice interaction

General Introduction
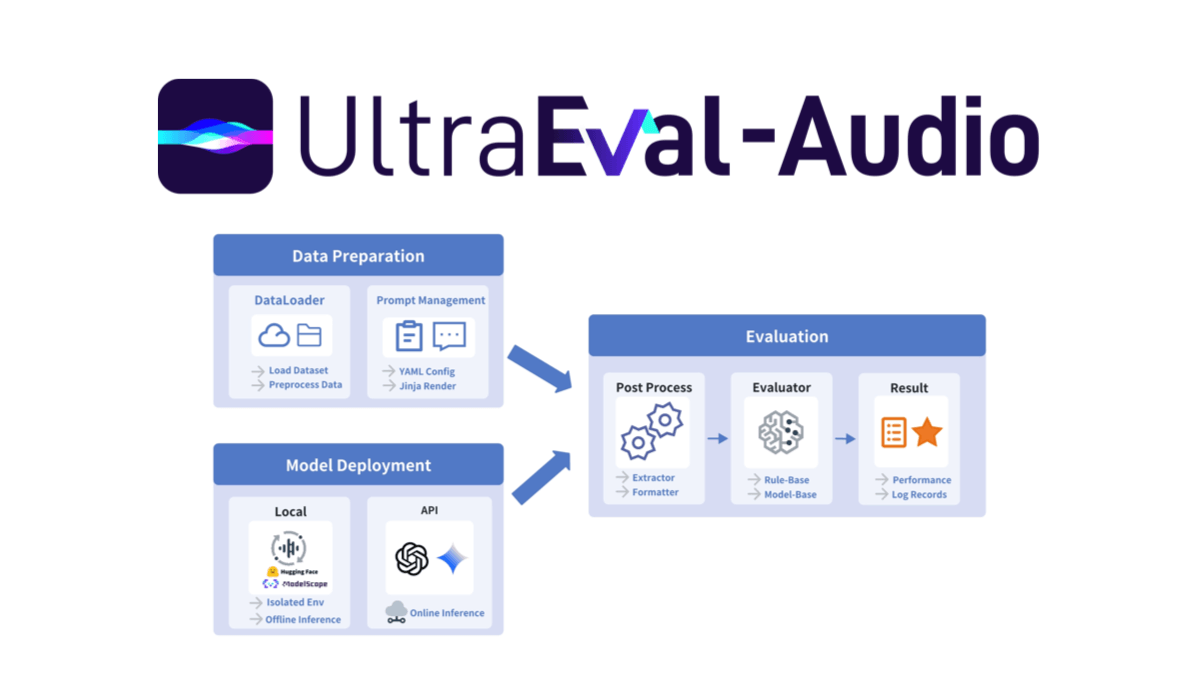
Baichuan-Audio is an open source project developed by Baichuan Intelligence (baichuan-inc), hosted on GitHub, focusing on end-to-end voice interaction technology. The project provides a complete audio processing framework that can convert speech input into discrete audio tokens , and then generate the corresponding text and audio output through a large model , to achieve high-quality real-time dialog features . Support for Chinese and English bilingual , applicable to the need for speech understanding and generation of the scene , such as intelligent assistants , voice chat robots and so on. In addition, the project also open-sources the base model Baichuan-Audio-Base and the evaluation benchmark OpenAudio-Bench to provide developers with powerful research and development support. The project follows the Apache 2.0 license, which is suitable for academic research and commercial applications under specific conditions.

Function List
- speech-to-audio taggingThe Baichuan-Audio Tokenizer converts incoming speech into discrete audio tokens and is designed to support a 12.5Hz frame rate to ensure information retention.
- real time voice interaction: Combined with Audio LLM, it supports bilingual conversations in English and Chinese, generating high-quality voice and text responses.
- Audio Generation: Generate high-fidelity Mel spectrograms and waveforms from audio markers using the Flow-matching Audio Decoder.
- modeling open source: Baichuan-Audio-Base, an uncommanded fine-tuned base model, is provided, and developers can customize the training according to their needs.
- Benchmarks: Includes OpenAudio-Bench, an audio comprehension and generation assessment tool with 2701 data points.
- multimodal support: Supports mixed text and audio input for seamless inter-modal switching.
Using Help
Installation process
To use Baichuan-Audio locally, you need to set up the development environment and download the relevant model files. The following are the detailed installation steps:
- environmental preparation
- Make sure Python 3.12 and Conda are installed on your system.
- Create and activate a virtual environment:
conda create -n baichuan_audio python=3.12 conda activate baichuan_audio - Install the necessary dependency libraries:
pip install torch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 --index-url https://download.pytorch.org/whl/cu124 pip install -r requirements.txt pip install accelerate flash_attn==2.6.3 speechbrain==1.0.0 deepspeed==0.14.4 - Installation of system tools:
apt install llvm ffmpeg
- Download model
- Clone the code from the GitHub repository (https://github.com/baichuan-inc/Baichuan-Audio):
git clone https://github.com/baichuan-inc/Baichuan-Audio.git cd Baichuan-Audio - modifications
web_demo/constants.pyhit the nail on the headMODEL_PATHThis is the path to the local model (you need to download it manually or use Hugging Face to get the model weights, for example).baichuan-inc/Baichuan-Audio).
- Clone the code from the GitHub repository (https://github.com/baichuan-inc/Baichuan-Audio):
- Run the Demo
- Start the Speech Recognition Demo:
cd web_demo python base_asr_demo.py - Start the Speech Synthesis Demo:
python base_tts_demo.py - Start a multi-round dialog Demo:
python s2s_gradio_demo_cosy_multiturn.py
- Start the Speech Recognition Demo:
Functional operation flow
1. Speech-to-audio tokenizer (Baichuan-Audio Tokenizer)
- Functional Description: Converts incoming speech files or live microphone input into discrete audio tokens for subsequent processing.
- procedure::
- Prepare an audio file (WAV format supported) or connect a microphone device.
- running
base_asr_demo.pyAfter that, the interface will prompt to upload audio or turn on the microphone. - The system automatically calls Whisper Large Encoder extracts features and generates audio tokens through 8 layers of RVQ (residual vector quantization).
- The output can be viewed on the console and is formatted as a sequence of discrete markers.
- caveat: Ensure that audio is clear and background noise is low to improve recognition accuracy.
2. Real-time voice interaction (Audio LLM)
- Functional Description: Supports users to have bilingual real-time dialog with the model through voice or text input.
- procedure::
- (of a computer) run
s2s_gradio_demo_cosy_multiturn.pyThe Gradio interface opens. - Click the "Record" button to start voice input (e.g. "Please tell me today's weather in Chinese").
- The system converts speech to tags and Audio LLM generates text and speech responses.
- The response is simultaneously displayed in text and played through the speakers.
- (of a computer) run
- Featured Usage::
- Input mixed-modal content, e.g., enter the text "Hi" and then say "Please continue to answer in English" with your voice.
- The system enables modal switching through special markers to keep the dialog coherent.
3. Audio generation (Flow-matching Audio Decoder)
- Functional Description: Generate high-quality speech output based on text or audio input.
- procedure::
- (of a computer) run
base_tts_demo.py, enter the text-to-speech interface. - Enter something in the text box (e.g., "Hello, it's Friday").
- Click the "Generate" button, the system will convert the text into audio tokens, and then generate Mel spectrogram by stream matching decoder.
- Use the built-in vocoder to convert the spectrogram to a WAV file for automatic playback or download.
- (of a computer) run
- Advanced Features: Support adjusting the speed and pitch of speech, the specific parameters can be modified in the code.
4. Use of benchmarks (OpenAudio-Bench)
- Functional Description: Evaluating the audio comprehension and generation capabilities of models.
- procedure::
- Download the OpenAudio-Bench dataset (located in the GitHub repository).
- Run the evaluation script locally (you need to write it yourself or refer to the repository documentation).
- Enter the test audio or text to obtain the model's performance scores on the 5 sub-evaluation sets.
- application scenario: Developers can use it to compare the performance of different models and optimize training strategies.
caveat
- hardware requirement: CUDA-enabled GPUs (e.g. NVIDIA cards) are recommended; CPU operation may be slower.
- network dependency: Internet access is required to download the model weights for the first run, and subsequent offline use is possible.
- commercial use: It is required to comply with the Apache 2.0 protocol and confirm that the Daily Active Users (DAU) is less than 1 million.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...