
Youtu-Embedding - Tencent Youtu open source generalized text representation model
Youtu-Embedding is a generalized text representation model open-sourced by Tencent's Youtu Lab, designed for enterprise-level applications. Through deep neural networks to map the text to a high-dimensional vector space, so that semantically similar sentences are closer in that space, to achieve accurate semantic retrieval.

SAIL-VL2 - ByteHop's open source multimodal visual language model
SAIL-VL2 is an open source multimodal visual language model by the Byte Jump team, focusing on joint modeling of multimodal inputs such as images and text. Using the sparse mixture of experts (MoE) architecture and progressive training strategy, it achieves high performance at parameter scales from 2B to 8B, especially in the areas of graphic comprehension, math...

MineContext - Bytes Open Source Active Context-Aware AI Partner
MineContext is an active context-aware AI partner open-sourced by the ByteDance Viking team to help users efficiently manage massive amounts of information and improve the efficiency of knowledge work. Over the screenshot and content understanding technology, automatically record the user's daily operations (such as browsing the web, editing documents, etc.), support...

nanochat - Karpathy's free and open source low-cost model training program
nanochat is an open source project released by AI legend and former Tesla AI Director Andrej Karpathy that allows individuals to quickly train a small ChatGPT-like language model at a very low cost and simplicity. The entire project uses only about 800...
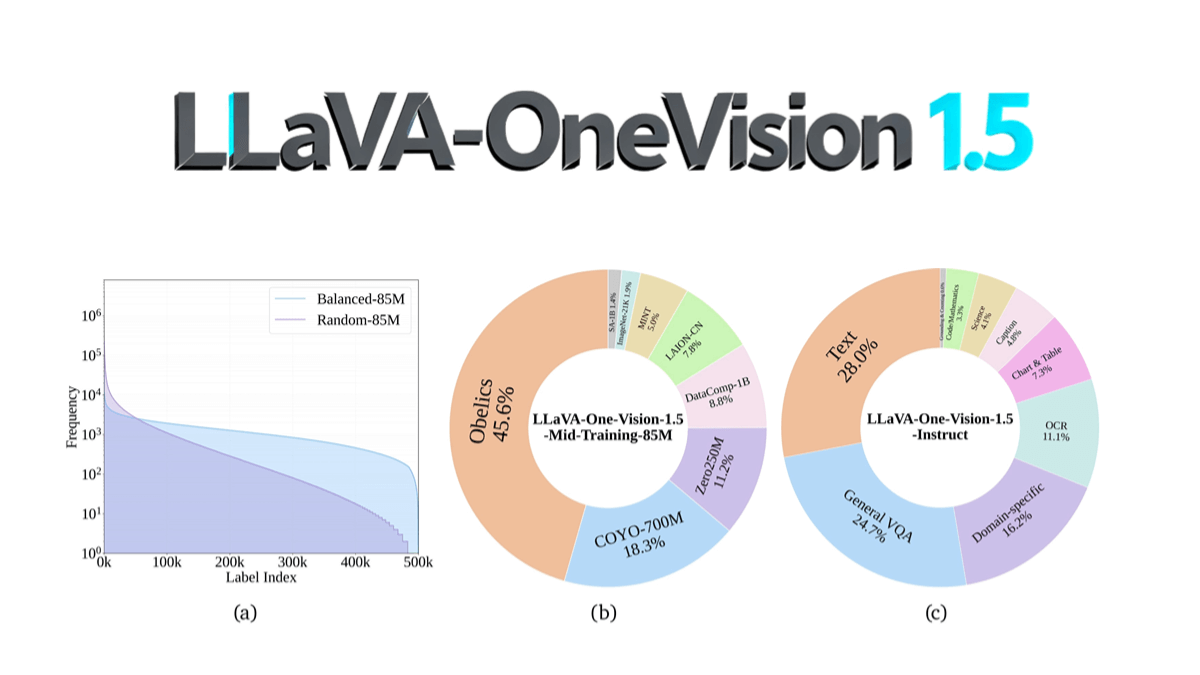
LLaVA-OneVision-1.5 - Free and open source multimodal modeling, high performance multimodal understanding
LLaVA-OneVision-1.5 is an open-source multimodal model by the EvolvingLMMS-Lab team, using 8B parameter scale, through a compact three-phase training process (language-image alignment, conceptual equalization and knowledge injection, and instruction fine-tuning) on 128 A800...
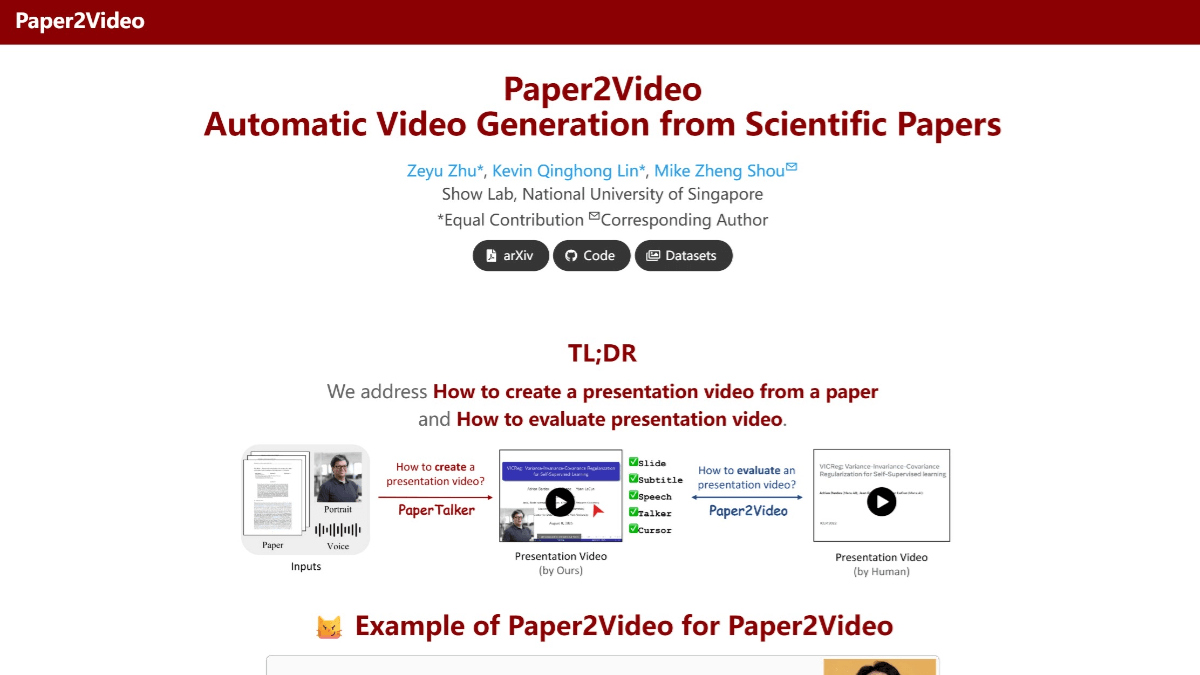
Paper2Video - NUS open source project to automatically generate demo videos for academic papers
Paper2Video is an open-source presentation video project for automatic generation of academic papers by Show Lab at National University of Singapore. Using the PaperTalker multi-intelligence framework, papers are transformed into full presentation videos containing slides, subtitles, voiceover and speaker avatar...

NeuTTS Air - Free and Lightweight Speech Synthesis Model with Offline CPU Running Support
NeuTTS Air is open source lightweight speech synthesis model, developed by Neuphonic team, which can run in real time on local devices (e.g. cell phones, laptops, Raspberry Pi) without relying on the cloud. Using 0.5B parameter Qwen architecture and self-developed NeuCodec codec...

KAT-Dev-72B-Exp - Racer open source free programming-specific models
KAT-Dev-72B-Exp is an open-source programming-specific large language model launched by the Racer team, optimized based on reinforcement learning technology, which achieved an accuracy rate of 74.6% in the SWE-Bench Verified benchmark test, the best performance of any open-source model at present. The model uses innovative...

Jamba Reasoning 3B - Israel AI21 Labs open source lightweight reasoning model
Jamba Reasoning 3B is a lightweight inference model open-sourced by Israeli AI startup AI21 Labs with strong performance and potential for a wide range of applications. It utilizes a hybrid SSM-Transformer architecture that combines Trans...
Free Course on the Latest Intelligentsia from Agentic AI by Ernest Ng
Agentic AI is the newest course on intelligent bodies launched by Ernest Ng.The course focuses on the design and construction of intelligent bodies, covering the four major design patterns of reflection, tool use, planning, and multi-intelligent body collaboration. Learners will master how to make intelligent bodies check outputs, autonomously adjust through theoretical explanations and code practice...