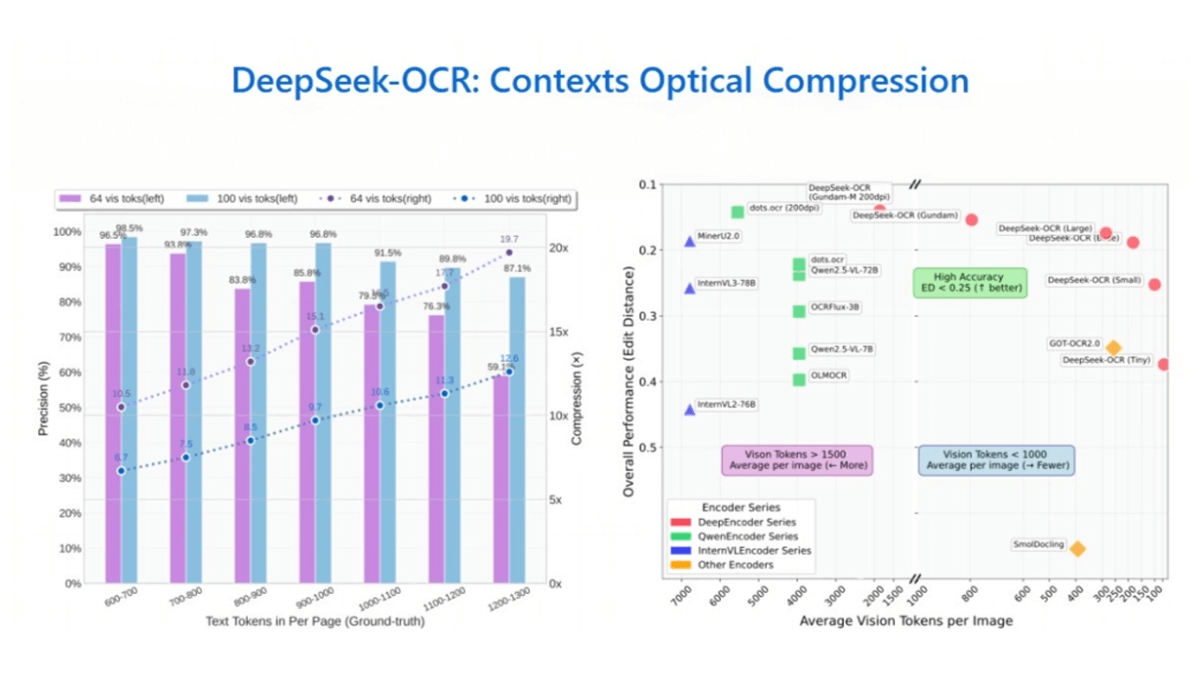
DeepSeek-OCR - DeepSeek open source optical character recognition model
DeepSeek-OCR is an advanced optical character recognition (OCR) model open-sourced by the DeepSeek team, which converts text into images through "contextual optical compression" technology, and utilizes visual tokens for compression and decoding to achieve efficient long text processing.

VitaBench - MMT LongCat Open Source Interactive Agent Review Benchmarks
VitaBench is the first interactive Agent evaluation benchmark for complex life scenarios released by the LongCat team of Meituan, assessing the comprehensive capabilities of large model intelligences in real life scenarios. The three high-frequency life scenarios of take-away ordering, restaurant dining, and traveling are used as the carrier to build the package...
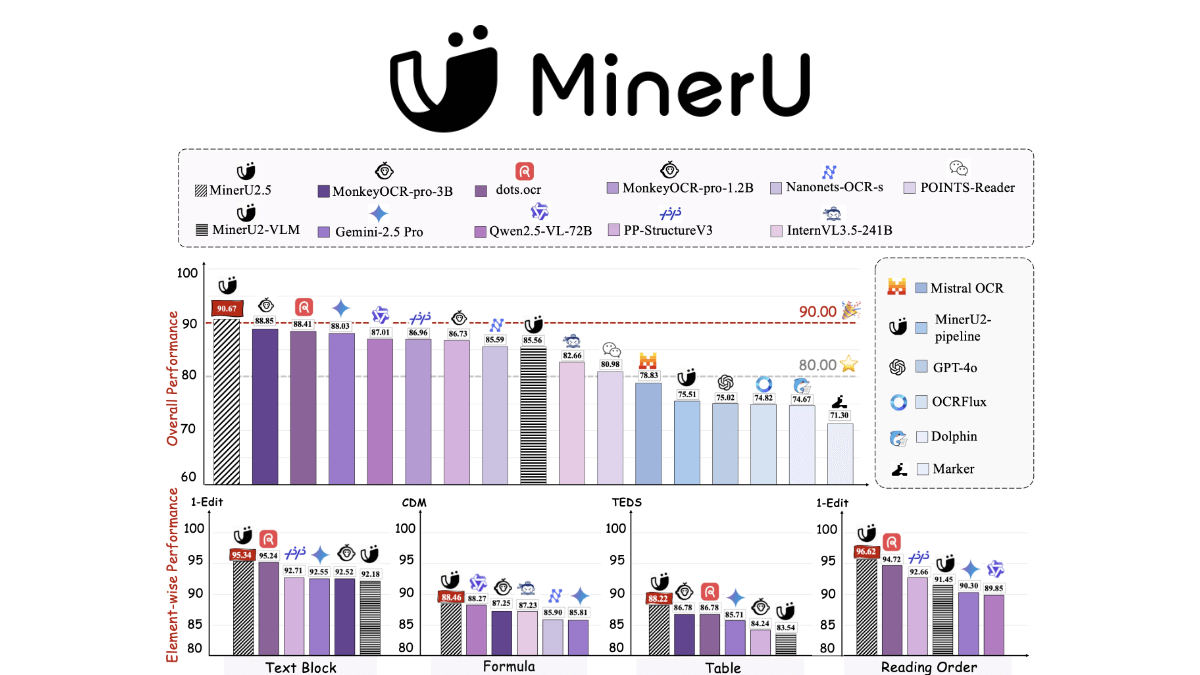
MinerU2.5 - Shanghai AI Lab and Peking University open source document parsing model
MinerU2.5 is a decoupled visual language model jointly developed by Shanghai Artificial Intelligence Laboratory (AIL) and Peking University, focusing on efficiently processing high-resolution document image parsing. The core innovation lies in the two-phase design of "global layout detection followed by local content recognition": the first phase is a low-resolution...

LongCat-Audio-Codec - LongCat open source voice codec solution for Meituan
LongCat-Audio-Codec is an open source speech codec solution from the LongCat team of Meituan. The program is designed for Speech Large Language Model (Speech LLM), through the semantic and acoustic dual Token parallel extraction mechanism , taking into account the semantic and acoustic features of speech ...

PaddleOCR-VL - Baidu open source ultra-lightweight visual-linguistic models
PaddleOCR-VL is Baidu's open source ultra-lightweight visual-language model, optimized for document parsing scenarios. The model contains only 0.9B parameters , through the fusion of dynamic high-resolution visual coder and lightweight ERNIE language model , while maintaining high accuracy and significantly reduce the computational overhead .
UniPixel - Pixel-level multimodal model open-sourced by Hong Kong Polytechnic, Tencent, Chinese Academy of Sciences and others
UniPixel is a novel multimodal model jointly proposed by Hong Kong Polytechnic University, Tencent, Chinese Academy of Sciences and Vivo to achieve pixel-level visual language understanding. By unifying object referencing and segmentation capabilities, it supports a variety of fine-grained tasks such as image segmentation, video segmentation, region understanding, and pi...
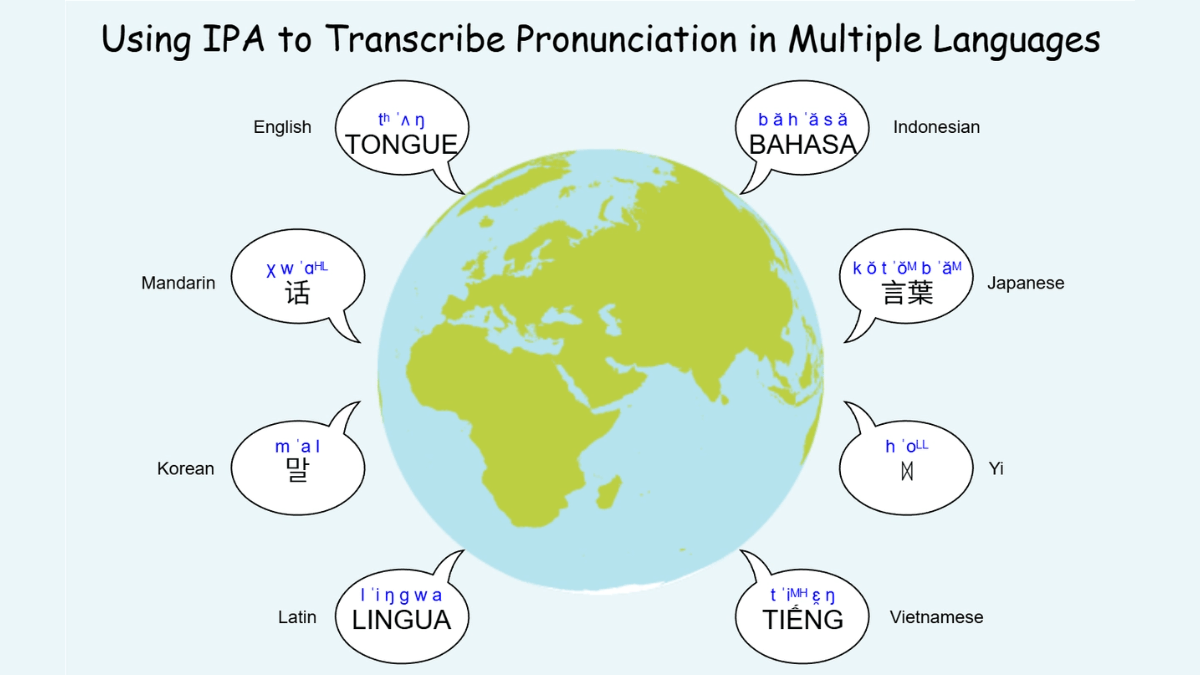
DiaMoE-TTS - Tsinghua and Giant Networks open source multi-dialect speech synthesis framework
DiaMoE-TTS is a multi-dialect speech synthesis framework jointly open-sourced by Tsinghua University and Giant Network, based on the International Phonetic Alphabet (IPA), to solve the problems of dialect data scarcity, orthographic inconsistency, and complex phonological changes. Through a unified IPA front-end standardized phoneme representation to eliminate cross-dialect differences ...
Kandinsky 5.0 - Russian AI Team's Open Source Video Generation Model Series
Kandinsky 5.0 is the latest video generation model series developed by Russian AI team, focusing on lightweight design and high performance performance. The first model in the series, Kandinsky 5.0 Video Lite, has only 2 billion parameters but surpasses similar 14B models, especially...

SongBloom - Tencent's open source song generation model with HKCNU and NTU.
SongBloom is an open source song generation model developed by Tencent AI Lab in collaboration with The Chinese University of Hong Kong (Shenzhen) and Nanjing University, which solves the problem of "plasticity" in AI music generation, and realizes high-quality, structurally complete song generation. Simply enter 10 seconds of reference audio and corresponding lyrics, and you can...

Pyscn - Free AI code quality analysis tool open-sourced specifically for Python developers
Pyscn is an intelligent code quality analysis tool designed for Python developers to detect potential problems in code to improve maintainability. It analyzes dead code through control flow diagrams, identifies duplicate code using APTED+LSH algorithm, calculates metrics such as module coupling and circle complexity...