
Open-o3 Video - A Video Reasoning Model Open-Sourced by Peking University United Bytes
Open-o3 Video is an open source video inference model jointly developed by Peking University and ByteDance, focusing on enhancing video inference through temporal and spatial evidence. By explicitly labeling key evidence with timestamps and bounding boxes, it helps the model better understand and interpret video content.
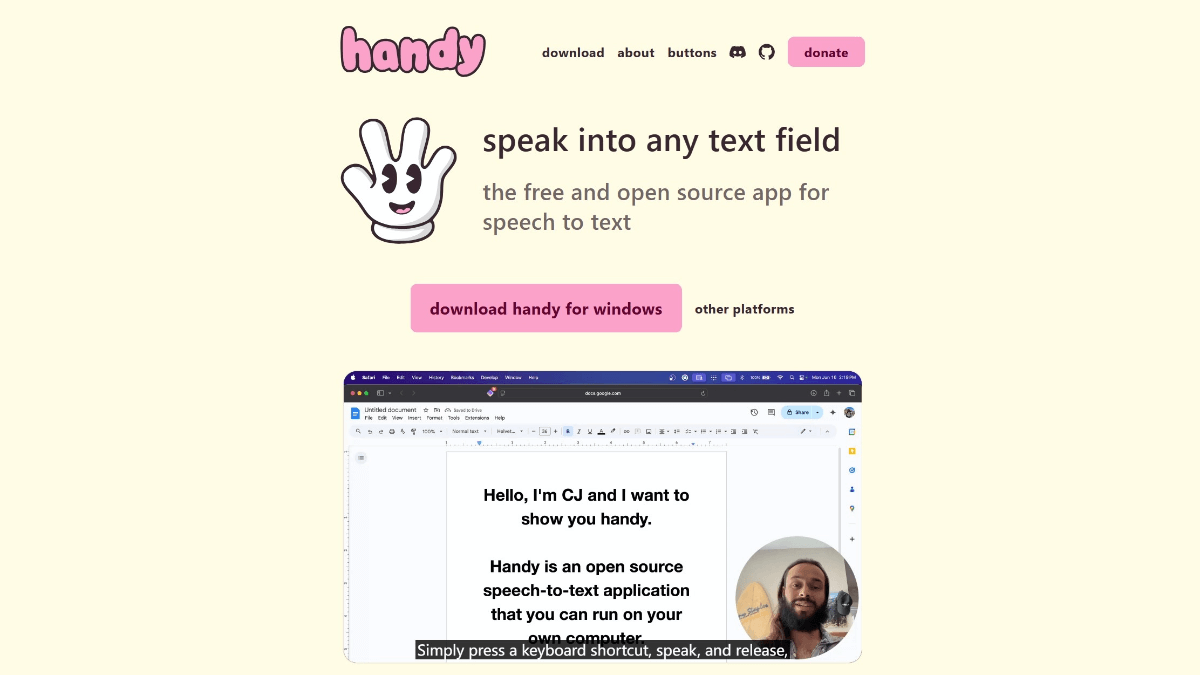
Handy - Open Source Free Native AI Speech to Text Tool
Handy is open source and free local speech to text tool, supporting Windows, MacOS and Linux systems, developed by Rust and React. It is suitable for quick transcription and text input by processing voice data locally without uploading it to the cloud to ensure privacy and security.
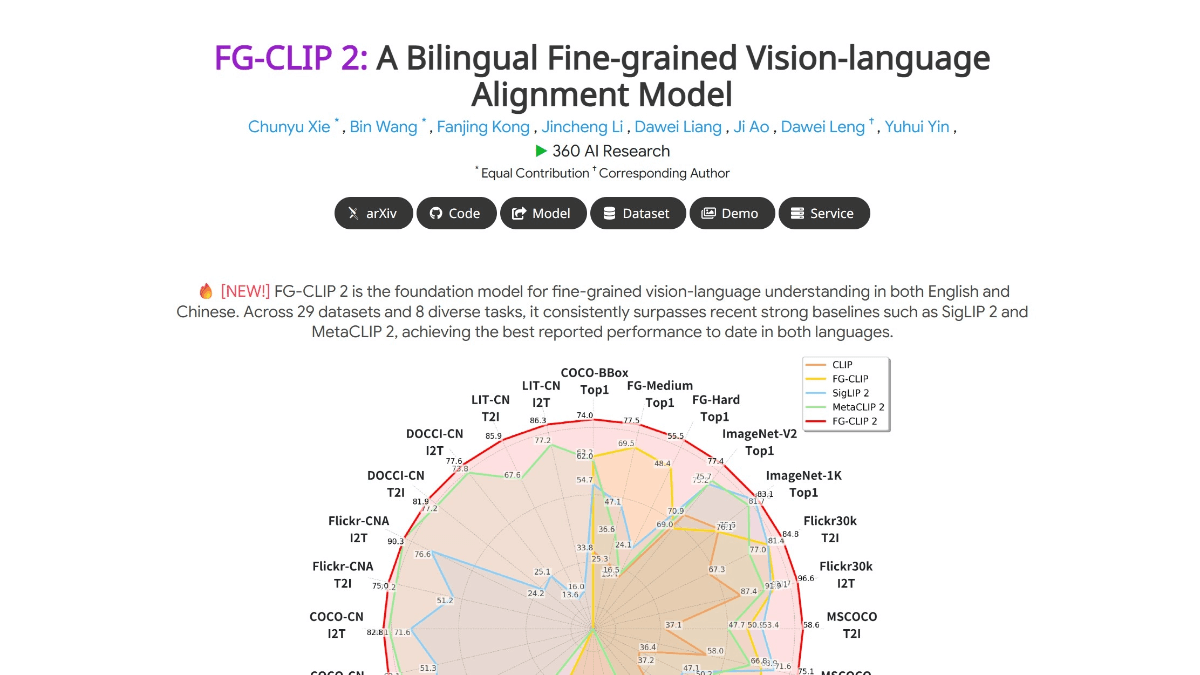
FG-CLIP 2 - 360 Open Source Cross-Modal Visual Language Model for Graphic Texts
FG-CLIP 2 is the world's leading graphical cross-modal visual language model (VL-M) launched by 360 Artificial Intelligence Research Institute, which surpasses similar models from Google and Meta in 29 authoritative benchmark tests, making it the most powerful VL-M at present.It is able to accurately recognize the gross...

BettaFish - Open Source Multi-Intelligence Public Opinion Analyzing System
BettaFish is an open source multi-intelligence system for public opinion analysis. Using multi-intelligent body architecture, through Query, Media, Insight, Report and other Agents work together to achieve retrieval, extraction and reporting closed loop. The system supports AI-driven full ...

Ouro - A new cyclic language model open-sourced by the ByteHopper Seed team
Ouro is a new type of Looped Language Models (LLMs) developed by the ByteDance Seed team, with the core innovation of directly building inference capabilities in the pre-training phase through a parameter-sharing recurrent computation structure. The model uses 24 layers as the base block through...
ChronoEdit - AI image editing framework jointly open-sourced by NVIDIA and the University of Toronto
ChronoEdit, an open-source AI image editing framework developed by NVIDIA in conjunction with the University of Toronto, redefines the image editing task as a video generation task to ensure that the editing results are temporally and physically consistent. By distilling a pre-trained video generation model with 14B parameters from a...

LongCat-Flash-Omni - A Fully Modal Large Language Model for Meituan Open Source
LongCat-Flash-Omni is an open source fully modal big language model released by the LongCat team of Meituan. With a parameter scale of 560 billion (27 billion activated parameters), it realizes millisecond-level real-time audio and video interaction capabilities while maintaining a large number of parameters.
Petri - Anthropic's open source AI security auditing framework
Petri is an open source AI security auditing framework developed by Anthropic that systematically assesses the security and behavioral alignment of AI models. By simulating a real-world scenario where an automated auditor engages in multiple rounds of conversations with a target model, followed by a judge agent that acts on the model's...
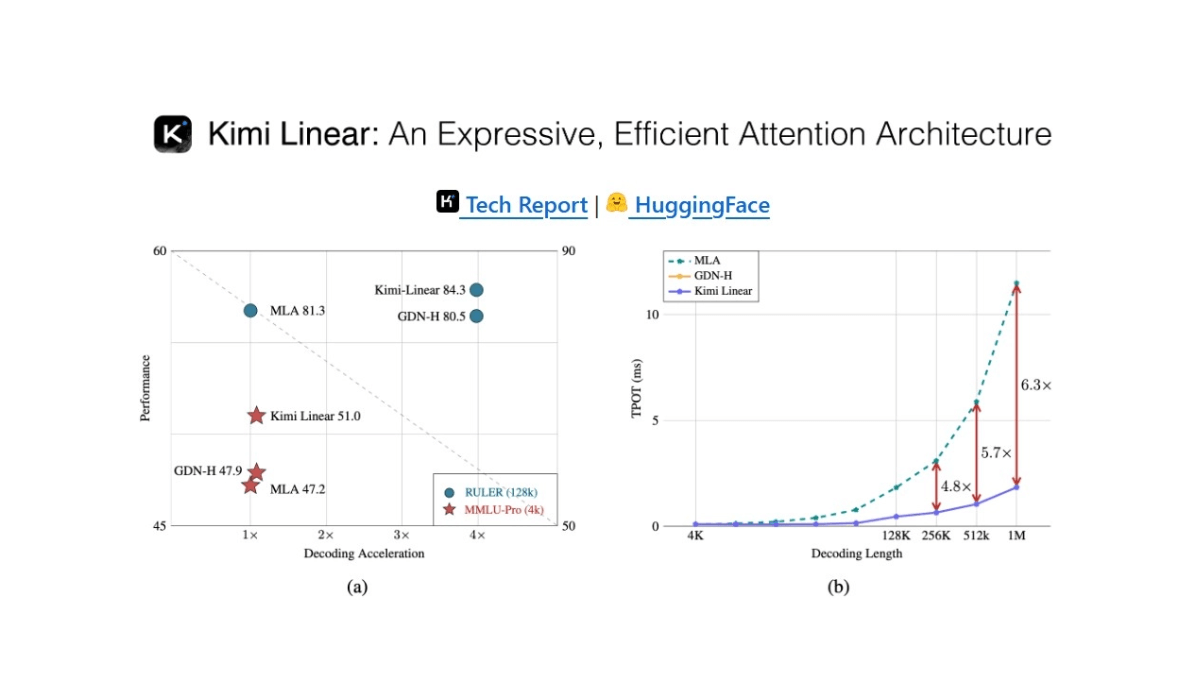
Kimi Linear - A New Hybrid Linear Attention Architecture Open-Sourced by Dark Side of the Moon
Kimi Linear is a new hybrid linear attention architecture open-sourced by Dark Side of the Moon, with Kimi Delta Attention (KDA) as the core, optimizing the traditional attention model through a finer-grained gating mechanism, which significantly improves the hardware efficiency and memory control ability ...

FIBO - The world's first open-source native JSON-enabled text to image modeling
FIBO is the world's first open source text generation image model with native JSON support developed by Bria AI. Based on the DiT (Diffusion Transformer) architecture with 8B parameters, it adopts the Flow Matching training method...