
LazyCraft - Open Source AI Agent Application Development and Management Platform, built on LazyLLM
LazyCraft is an open source AI Agent application development and management platform built by Shangtang based on the open source framework LazyLLM, which provides one-stop AI application development solutions for enterprises and developers. It helps developers to quickly build and release large model applications with low threshold and low cost...

Kosong - Moonshot AI's New Open Source AI Agent Development Framework
Kosong is a new AI Agent development framework open-sourced by Dark Side of the Moon (Moonshot AI) that provides developers with a lightweight, flexible, and highly scalable underlying support for building next-generation intelligent body applications. With an asynchronous tool orchestration engine that efficiently schedules multiple tools...

SenseNova-SI - A Family of Open Source Spatial Intelligence Large Models from ShangTech
SenseNova-SI is an open source spatial intelligence grand model released by ShangTech, focusing on improving AI's ability in spatial understanding and reasoning. The model excels in six core dimensions, including spatial measurement, reconstruction, relationship judgment, perspective transformation, deformation analysis, and spatial reasoning, significantly outperforming other...
Omnilingual ASR - Multilingual Speech Recognition Framework from Meta
Omnilingual ASR is a multilingual speech recognition framework introduced by Meta, covering 1600+ languages, with 78% language character error rate lower than 10%. its 7 billion parameter wav2vec 2.0 encoder combined with CTC and Transformer decoder, support...
Frappe Builder - Open source AI low-code website builder, drag-and-drop components for fast building
Frappe Builder is open source low-code website builder, developed by Frappe, the core feature is to provide a Figma-like visual editor that supports drag-and-drop components to build websites quickly. Part of the Frappe ecology (Frappeverse)...
DeepOCR - Open source replica project based on the DeepSeek-OCR model
DeepOCR is an open source replication project that implements the core architecture of DeepSeek-OCR, which efficiently processes textual information through optical compression techniques. The core is DeepEncoder, consisting of SAM-base (processing high-resolution images), 16× convolutional compressor...
NocoBase - Free and open source AI no-code development platform to build apps visually
NocoBase is based on AI-driven open-source no-code development platform that supports the rapid construction of business systems, without programming to complete the application development through configuration. The project uses Apache-2.0 protocol , provides private deployment and flexible scalability , suitable for enterprise management , collaboration platforms and other fields ...

UniWorld V2 - A New Generation of Image Editing Models Launched by Rabbit Show Intelligence in Association with Peking University
UniWorld V2 is a new generation of image editing model jointly launched by RabbitZhan Intelligence and UniWorld team of Peking University. It has significant advantages in the field of image editing, especially in Chinese comprehension and execution of complex commands. The model can accurately render artistic Chinese fonts and support fine...
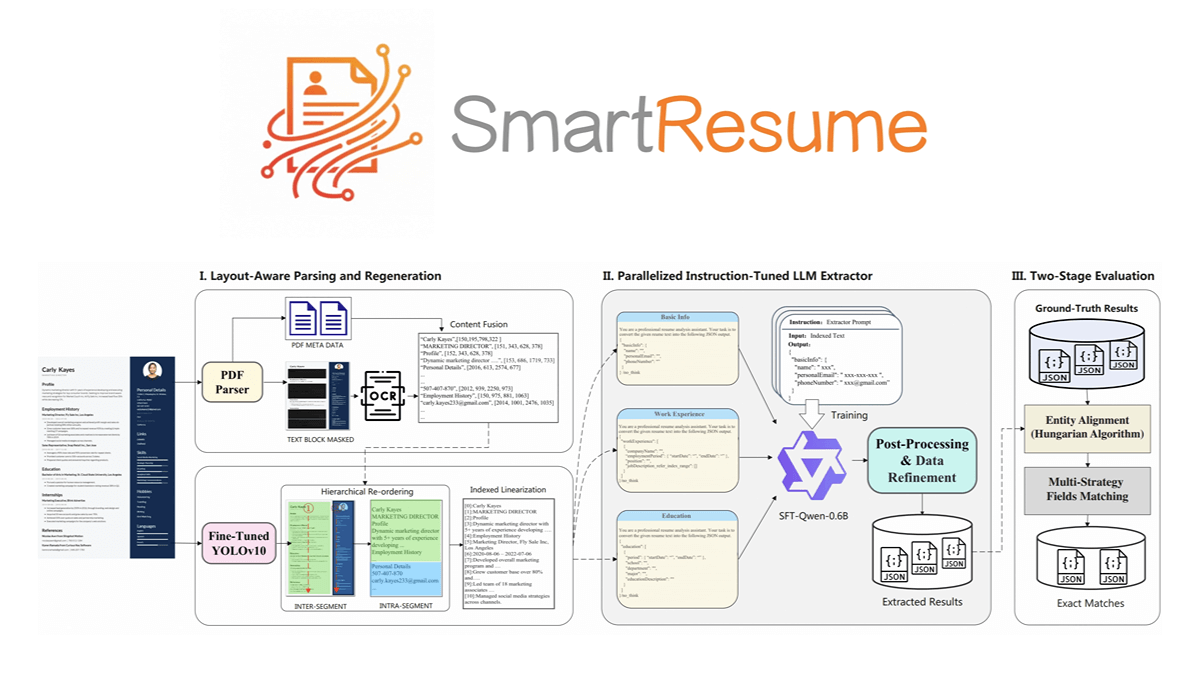
SmartResume - Alibaba open source AI resume parsing and optimization tool
SmartResume is Alibaba open source intelligent resume parsing and optimization tool , can efficiently extract structured information from PDF, images or Office documents , such as basic information , education and work experience . By integrating OCR technology and PDF metadata...

Step-Audio-EditX - Step-Star's first open source LLM-level audio editing large model
Step-Audio-EditX is an open source audio editing grand model, developed by the Step-Star team, focusing on fine-grained manipulation of audio content through artificial intelligence technology. The model can dynamically adjust the mood of the audio, speaking style (such as petulant, old man accent, etc.) and paralinguistic elements (such as laughter, sigh...