
TalkCody - Free and open source AI programming desktop assistant with support for complex tasks
TalkCody is a free and open source AI programming assistant desktop application , built on Rust + Tauri 2 , support for Windows, macOS and Linux three platforms , with native performance , fast startup and low resource consumption advantages . Supports more than 50 mainstream A...
MemMachine - Open Source AI Memory System by MemVerge
MemMachine is an open source AI memory system developed by MemVerge, designed for AI models and intelligences, which can store and recall interaction data like the human brain, solving the problem of AI "stateless memory loss". It adopts a layered architecture (short-term memory, long-term memory, user image...

PartCrafter - NU United Bytes open source single figure 3D generated models
PartCrafter is an advanced 3D generative model, jointly proposed by Peking University, ByteDance and Carnegie Mellon University. It can generate multiple semantically explicit and geometrically diverse 3D mesh parts from a single RGB image at once. The models are modeled through a combinatorial potential space and...

GigaWorld-0 - GigaVision open source world modeling framework
GigaWorld-0 is the open source world modeling framework of domestic Embodied Intelligence startup GigaAI, mainly used to solve the data bottleneck problem in the field of Embodied Intelligence (Embodied AI). Efficiently generating high-quality, diverse and physically realistic training data, push...
Mistral 3 - Mistral AI Releases Open Source's Newest Series of Multimodal Large Models
Mistral 3 is the latest multimodal large model series released as open source by Mistral AI, including the flagship model Mistral Large 3 (675B total parameters) and the lighter version of the Ministral series (3B/8B/14B), both supporting image understanding...

Vidi2 - ByteHop's open source multimodal video understanding and generation of large models
Vidi2 is a second-generation multimodal video understanding and generation big model open-sourced by ByteDance, focusing on video content understanding, analysis and creation. It supports joint input of text, video, and audio modalities, and can simultaneously understand picture content, sound information, and natural language commands to achieve cross-modal interaction and push...
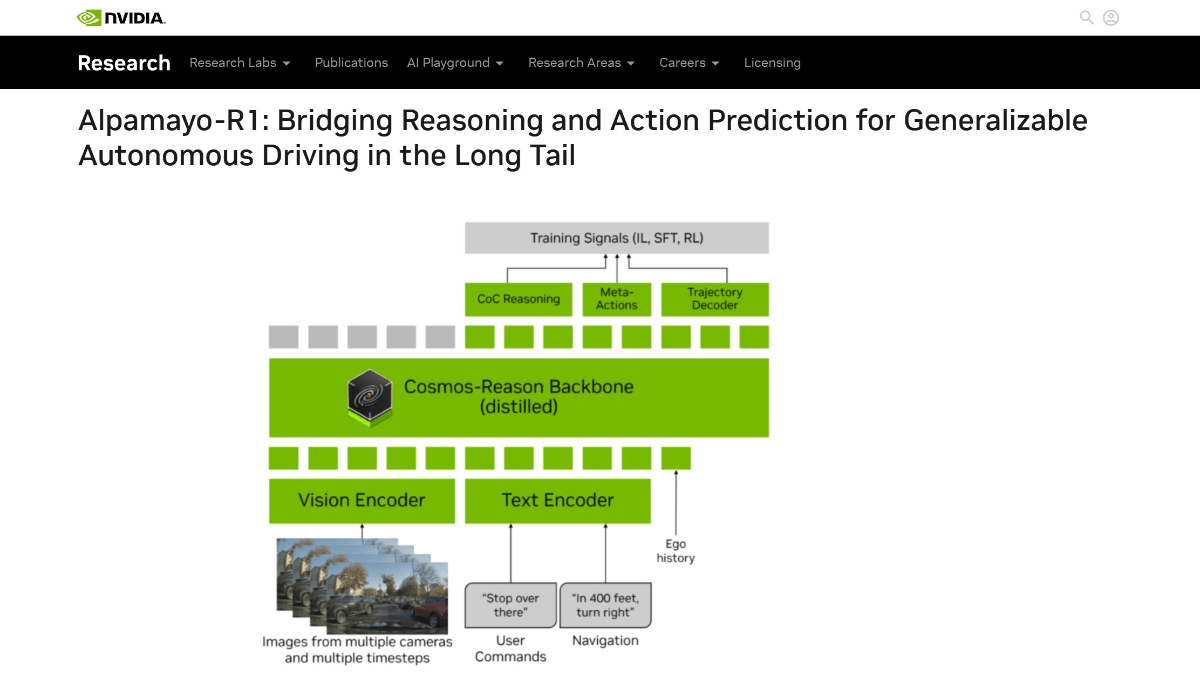
Alpamayo-R1 - NVIDIA's Open Source Vision-Language-Action Model with Reasoning Capabilities
Alpamayo-R1 is a NVIDIA-developed Vision-Language-Action (VLA) model with reasoning capability, designed to enhance the decision-making capability of autonomous driving in complex scenarios. By introducing a causal chain reasoning mechanism, the vehicle is able to analyze scene causality (e.g., "cause before...

Ovis-Image - Ali AIDC-AI team's open source Vincentian graph model
Ovis-Image is a 7 billion parameter text-generated graph model open-sourced by the AIDC-AI team of Alibaba International Digital Commerce Group, focusing on high-quality text rendering. Based on Ovis-U1 architecture, it inherits the advanced visual decoder and bi-directional Token refiner ...

Wujie-Emu3.5 - Wisdom Source Research Institute open source multimodal world big model
Wujie-Emu3.5 is an open source multimodal world grand model from Beijing Zhiyuan Artificial Intelligence Research Institute, with 34 billion references and native world modeling capability. Trained by 10 trillion multimodal Token (including 790 years of video data), it can simulate the laws of physics and realize graphic generation, visual guidance...
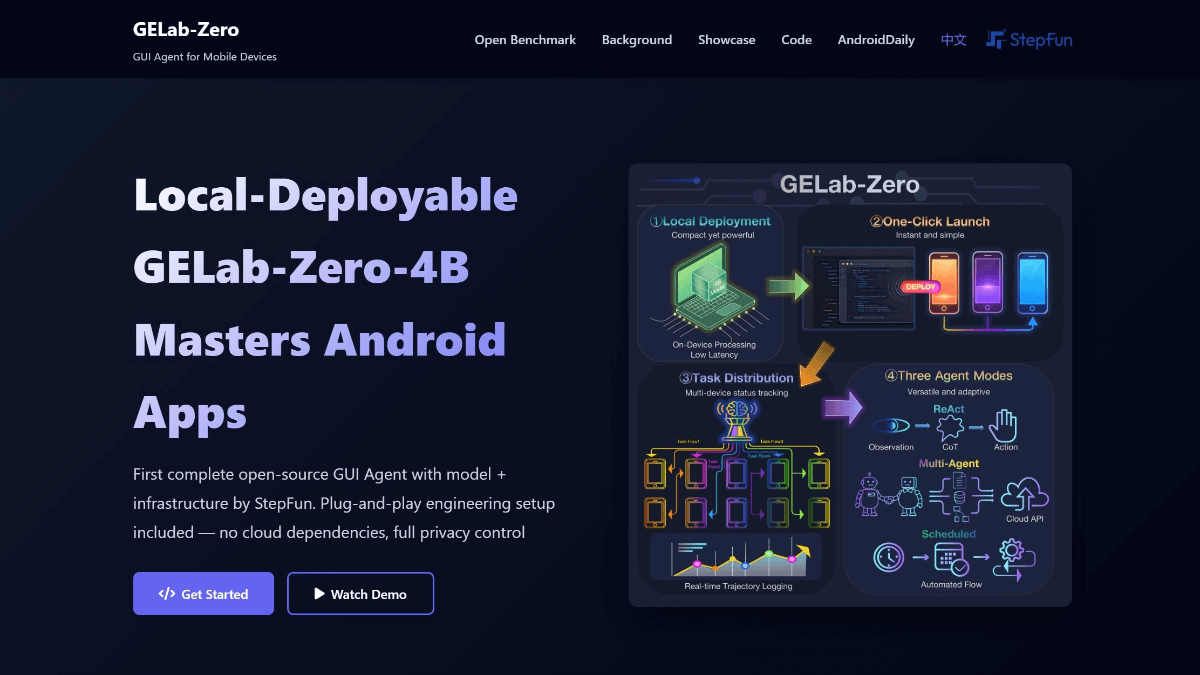
GELab-Zero - Open source end-side multimodal GUI Agent model by Steps team
GELab-Zero is an open source end-side multimodal GUI Agent model by Step Leap Team , built on Qwen3-VL-4B-Instruct base model with 4B parameters.It can recognize UI elements and perform operations such as clicking and sliding, and supports cross-application tasking ...