
Mixed World Model 1.5 - Tencent Mixed Open Source Real-time World Model Generation Framework
Mixed World Model 1.5 (Tencent HY WorldPlay) is the industry's first open source real-time world modeling framework released by Tencent, covering the entire chain of data, training, and streaming inference deployment. The core is the WorldPlay autoregressive diffusion model, which uses Next-F...
Molmo 2 - Ai2 open source multimodal video image understanding model series
Molmo 2 is an open source multimodal model released by the Allen Institute for AI (Ai2) to improve video and multi-image understanding. Three variants are included; Molmo 2 (8B), Molmo 2 (4B) and Molmo 2-O...
LongCat-Video-Avatar - MeiTuan open source avatar video generation model
LongCat-Video-Avatar is an advanced audio-driven video generation model built on LongCat-Video open-sourced by Meituan, focusing on generating hyper-realistic, lip-synchronized long videos with natural dynamics and consistent identity.
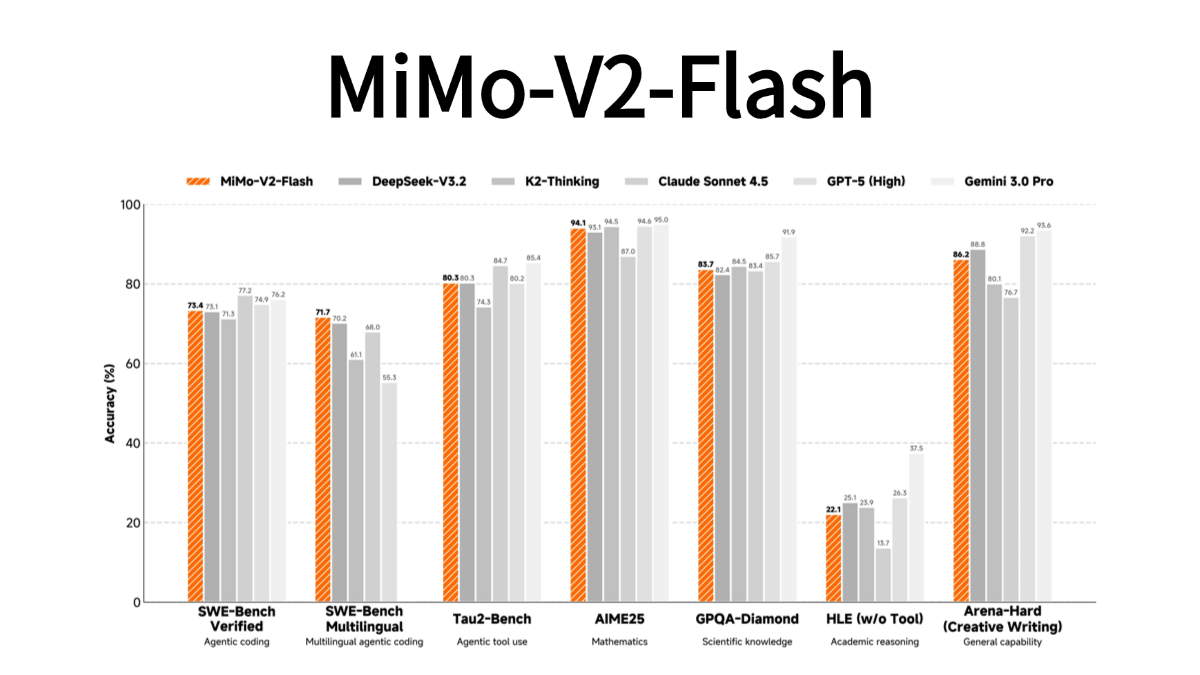
MiMo-V2-Flash - a large model of the open source MoE architecture released by Xiaomi
MiMo-V2-Flash is an open source MoE architecture large model released by Xiaomi, with 309 billion total parameters and 15 billion active parameters, focusing on efficient reasoning and intelligent body applications. The model adopts hybrid attention architecture and multi-word meta-prediction technology, with an inference speed of 150 tokens/second, into...

Nemotron 3 - A family of open source AI models released by NVIDIA
Nemotron 3 is a family of open source AI models released by NVIDIA in Nano, Super and Ultra sizes. It adopts the hybrid potential expert hybrid (latent MoE) architecture to significantly improve inference efficiency and reduce operating costs. Among them...

Wan-Move - Ali Tongyi's open source AI video generation framework with Tsinghua and others
Wan-Move is an open source AI video generation framework jointly developed by Ali Tongyi Labs, Tsinghua University and other organizations, focusing on high-quality video synthesis through precise motion control technology. The core technology is "potential trajectory guidance", which can seamlessly add point-level motion control to the existing image-to-video model...
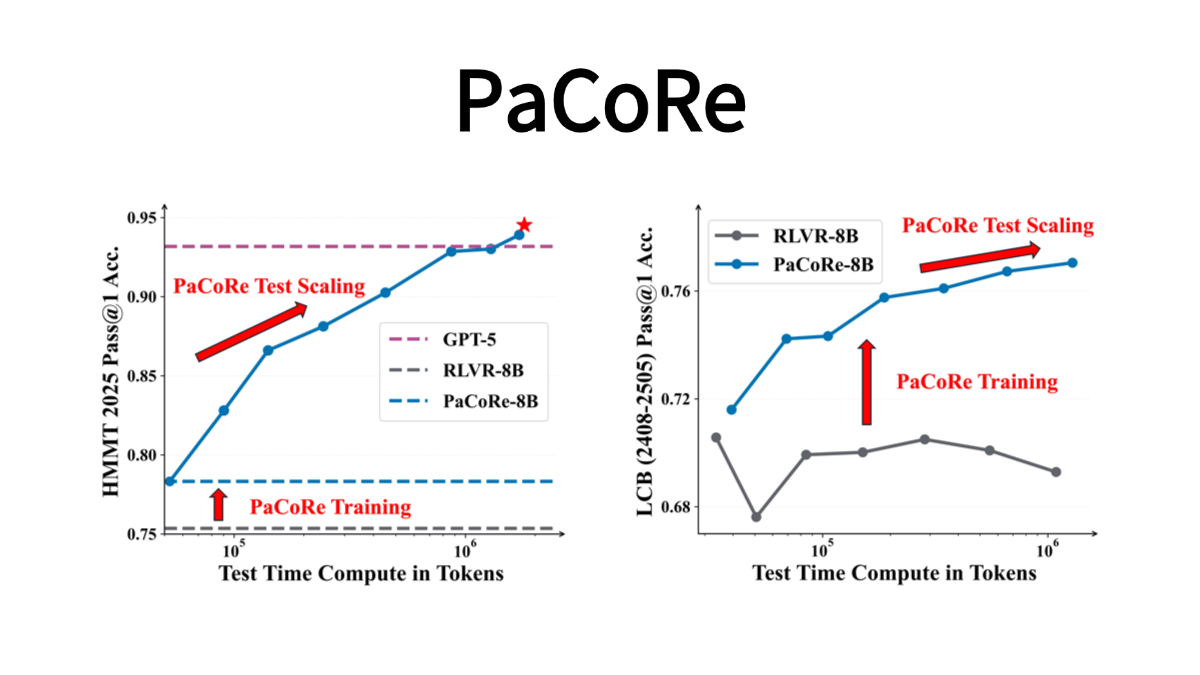
PaCoRe - Step Star's open source parallel collaborative AI reasoning framework
PaCoRe (Parallel Coordinated Reasoning) is StepFun's open source innovative parallel collaborative reasoning framework, through a massively parallel thinking mechanism, from multiple perspectives to simultaneously explore the problem solution, breaking through the traditional...

Banana Slides - Open source AI PPT generation tool based on Nano Banana Pro models
Banana Slides is an open source intelligent PPT generator based on the Nano Banana Pro AI model, which supports the rapid creation of professional presentations using natural language commands. Allows users to describe the topic (e.g. "Human impact on the ecosystem") in a single sentence, which can be self...
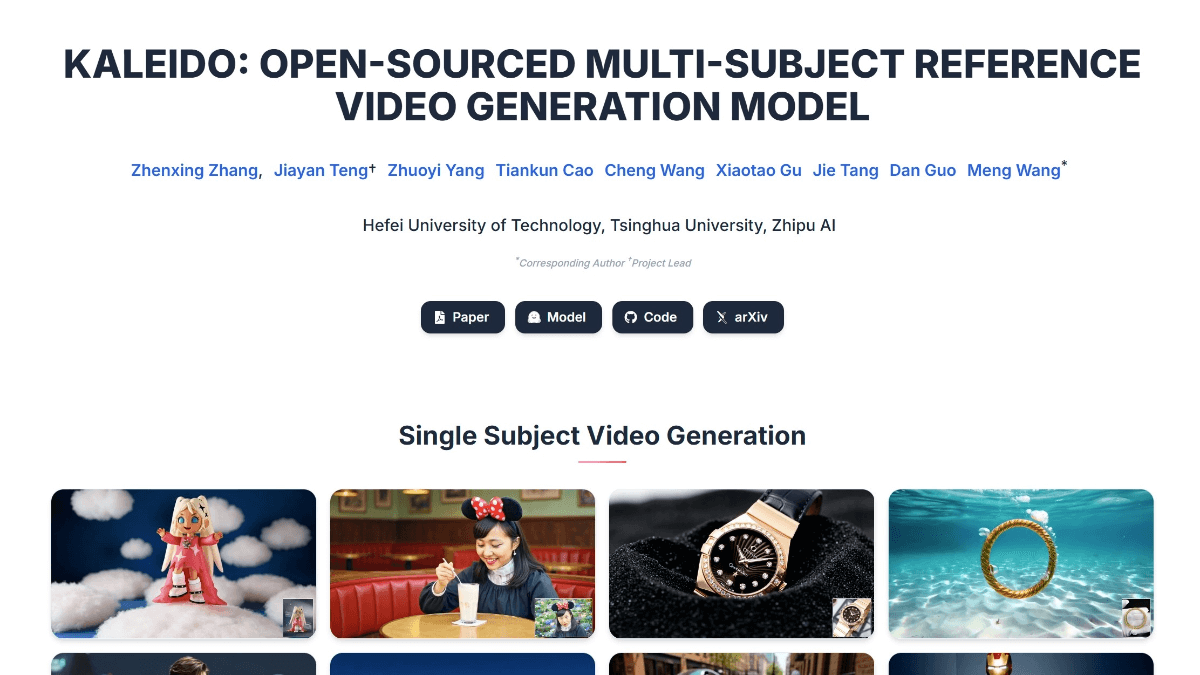
Kaleido - A multi-subject reference video generation model open-sourced by Smart Spectrum AI in collaboration with Tsinghua University and others
Kaleido is an open source multi-subject reference video generation model jointly developed by Hefei University of Technology, Tsinghua University and Smart Spectrum AI. It generates subject-consistent videos through multiple reference images, solving the deficiencies of existing models in multi-subject consistency and background decoupling.Kaleido generates videos through specialized data...

Paper2Slides - HKU open source academic papers into slides AI tool
Paper2Slides is an open source AI tool from the Data Intelligence Laboratory of the University of Hong Kong that converts academic papers into professional slides or posters in one click. Using RAG (Retrieval Augmented Generation) technology, directly parsing the document content rather than relying on network information, to ensure that the generated PPT is highly consistent with the original...