
女娲智能体OS - 西南财经开源的通用智能体操作系统
女娲智能体OS(Nuwax Agent OS)是西南财经大学赵宇教授团队推出的全球首个开源通用智能体操作系统。具备自主执行引擎,可实现从需求拆解到任务规划与执行的全链路自动化。系统支持可视化工作流编排...

Nemotron Speech ASR - 英伟达开源的实时语音识别模型
Nemotron Speech ASR是英伟达开源的实时语音识别模型,专为低延迟场景优化,支持24毫秒极速转录和多人并发对话。核心采用混合Mamba-Transformer MoE架构,通过固定状态缓...

Qwen3-VL-Reranker - 阿里巴巴推出的多模态重排序模型
Qwen3-VL-Reranker是阿里巴巴推出的多模态重排序模型,专门用于提升跨模态检索的精准度。与Qwen3-VL-Embedding协同工作:前者负责快速召回候选结果,后者通过深度跨模态交互(如...
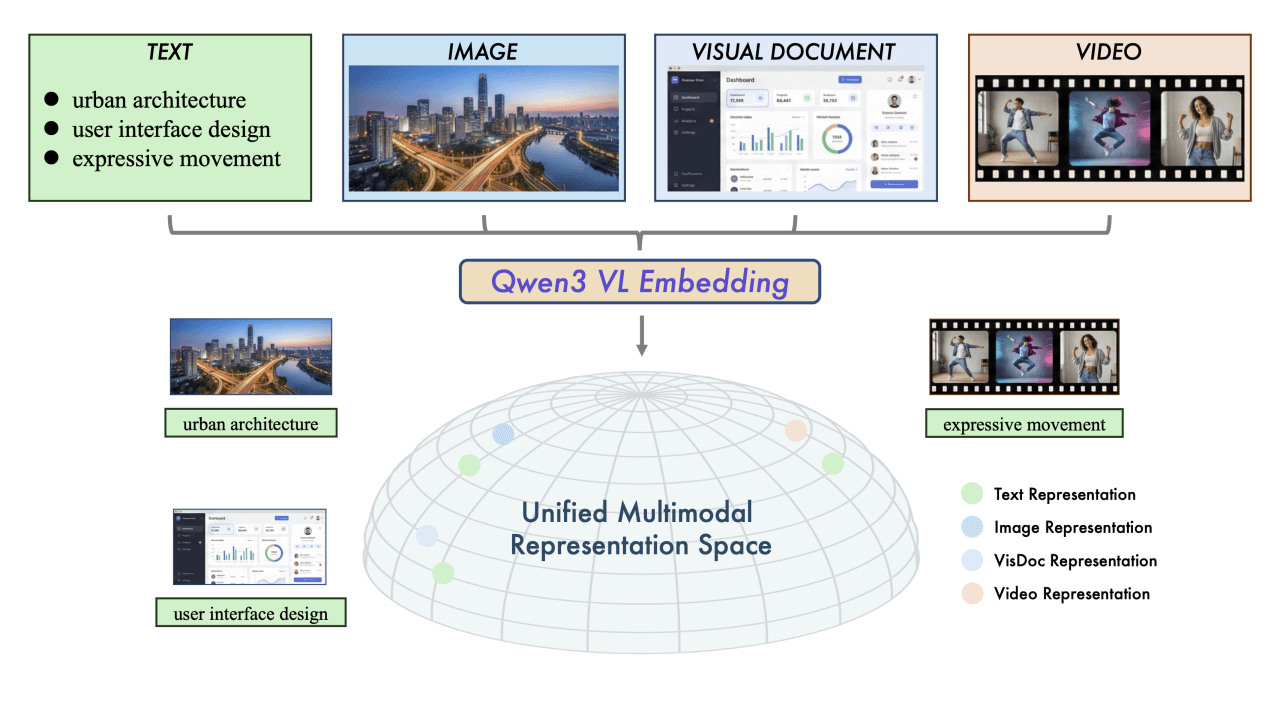
Qwen3-VL-Embedding - 阿里通义团队开源的多模态嵌入模型
Qwen3-VL-Embedding是阿里通义团队开源的多模态嵌入模型,属于Qwen3-VL系列,主要用于跨模态检索任务。模型将文本、图像、视频等不同模态数据映射到同一语义空间,通过双塔架构生成向量表...

AntAngelMed - 蚂蚁联合浙江省卫生健康信息中心开源的医疗大模型
AntAngelMed(蚂蚁·安诊儿医疗大模型)是浙江省卫生健康信息中心、蚂蚁健康、浙江省安诊儿医学人工智能科技有限公司联合开发的开源医疗大模型。模型采用混合专家架构(MoE),总参数量达1000亿...

VoiceSculptor - 西北工业大学联合语图智能开源的音色设计模型
VoiceSculptor 是西北工业大学联合多家机构开源的音色设计模型,基于 LLaSA-3B 和 CosyVoice2 开发,专注于通过自然语言指令生成多样化音色的语音合成。支持对语速、音量、基频...

10Kh RealOmni-Open - 简智机器人开源的具身智能数据集
10Kh RealOmni-Open是简智机器人开源的具身智能数据集,是行业内规模最大的开源具身智能数据集。数据集累计拥有超10000小时数据、100万+片段,覆盖10大场景任务、超过30项技能。数据...
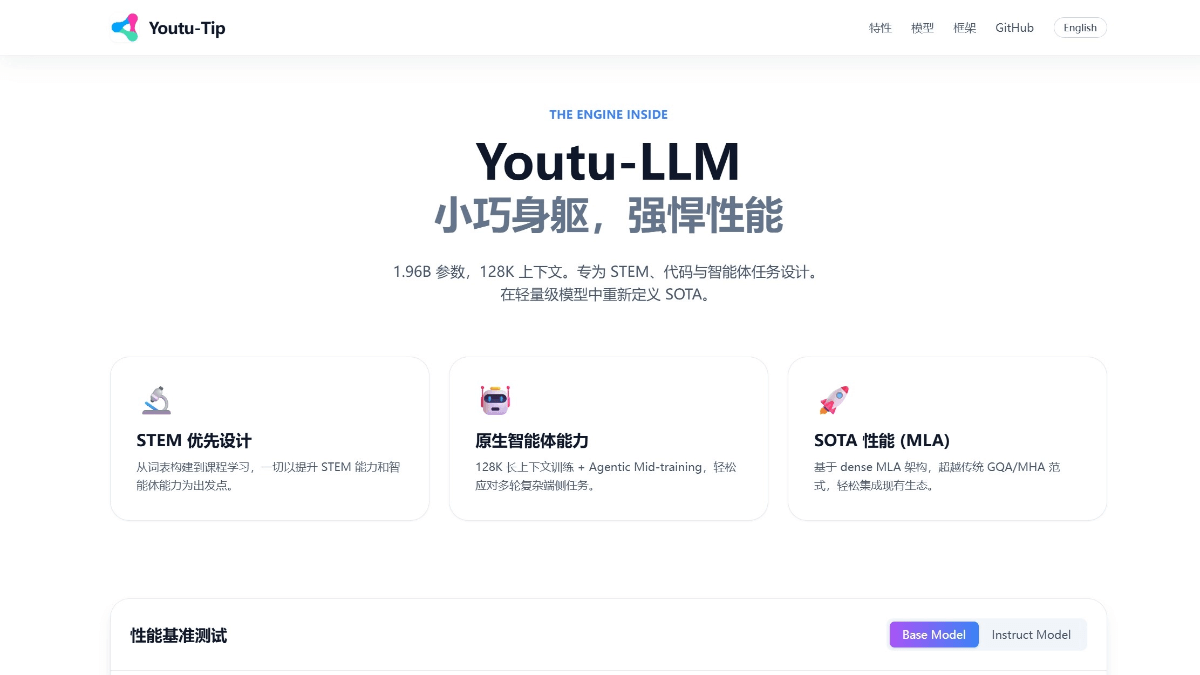
Youtu-LLM - 腾讯 Youtu 团队开源的轻量级语言模型
Youtu-LLM 是腾讯 Youtu 团队开源的轻量级语言模型,参数规模为 19.6 亿。专为智能体任务设计,具备强大的“原生智能体能力”,在多项任务中超越同规模甚至更大模型。
Genie Sim 3.0 - 智元机器人开源首个大语言模型驱动的仿真平台
Genie Sim 3.0是智元机器人发布的首个大语言模型驱动的开源仿真平台。基于NVIDIA Isaac Sim构建,融合三维重建、视觉生成技术与物理引擎,实现毫米级精准复刻真实环境,通过自然语言指...
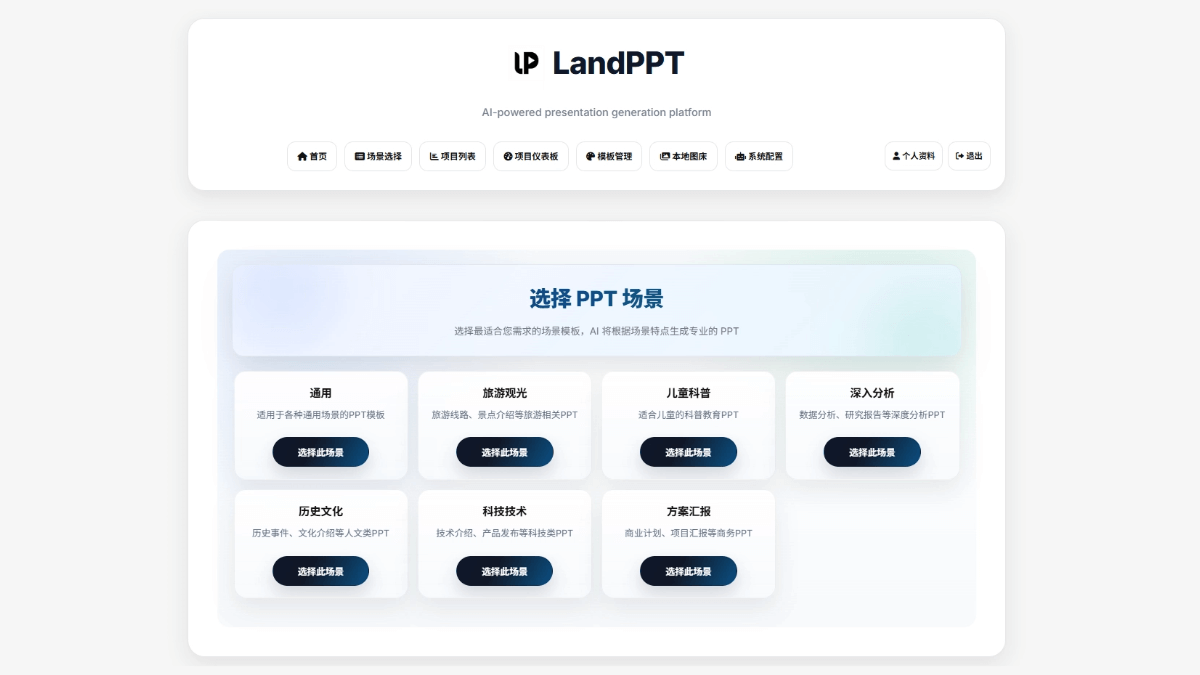
LandPPT - 开源免费的AI PPT生成工具,支持本地部署和云端协作
LandPPT是基于大语言模型的开源AI PPT生成工具,支持通过主题或上传文档(PDF/Word/Excel)一键生成专业演示文稿。集成了多模型驱动、实时联网搜索和AI绘图功能,提供丰富的模板和场景...