
Wan-Dancer - 阿里通义实验室开源的音乐舞蹈视频生成大模型
Wan-Dancer 是阿里巴巴通义实验室万相(Wan)团队推出的音乐驱动舞蹈视频生成大模型,开源版本 Wan-Dancer-14B 拥有140亿参数,采用 Apache 2.0 协议免费商用。用户只...

HyOCR-1.5 - 腾讯混元团队开源的轻量化端到端OCR专家大模型
HyOCR-1.5是腾讯混元团队开源的轻量化端到端OCR专家大模型,参数量仅1B,是领域首个训练、推理、权重完整开源的专家模型 。采用端到端架构,输入图片即可直接输出Markdown正文、HTML表格...
Hy3 - 腾讯开源的旗舰级大语言模型,快慢思考融合
Hy3 是腾讯推出的旗舰级开源大语言模型,采用 MoE 架构,拥有 295B 总参数与 21B 激活参数,支持长达 256K 的上下文窗口。核心亮点在于快慢思考融合(Hybrid Reasoning...
GPT-Live - OpenAI 推出的新一代语音模型,全双工实时对话
GPT-Live 是 OpenAI 推出的新一代语音模型,全面升级 ChatGPT 的语音交互体验。基于全双工(full-duplex)架构构建,能同时倾听和说话,彻底打破了传统 AI 语音助手"你说...
Grok 4.5 - SpaceXAI 发布的旗舰大语言模型,编码与智能代理专用模型
Grok 4.5 是 SpaceXAI(原 xAI)发布的旗舰大语言模型,定位为"Opus 级别"的编码与智能代理专用模型。模型基于 1.5 万亿参数的 V9 架构打造,采用 MoE(混合专家)架构...

Seedream 5.0 Pro - 字节跳动发布的多模态图像创作模型
Seedream 5.0 Pro是字节跳动豆包大模型团队发布的多模态图像创作模型,定位为面向专业创作者和企业级用户的设计工具。相比前代,在图文匹配、结构合理性等基础能力上全面提升
JellyToken - 阿里元境推出的大模型 API 聚合与分发平台
JellyToken 是国内领先的大模型 API 聚合与分发平台,定位为"国内主流 AI 大模型一站式超市"。用户仅需一个 API Key 即可无缝调用通义千问、DeepSeek、智谱、月之暗面、豆包...
Muse Image - Meta 推出的首个自研 AI 图像生成模型
Muse Image 是 Meta 推出的首个自研 AI 图像生成模型,由 Meta Superintelligence Labs 开发。采用独特的智能体(Agentic)架构,在生成图像前会先与 M...
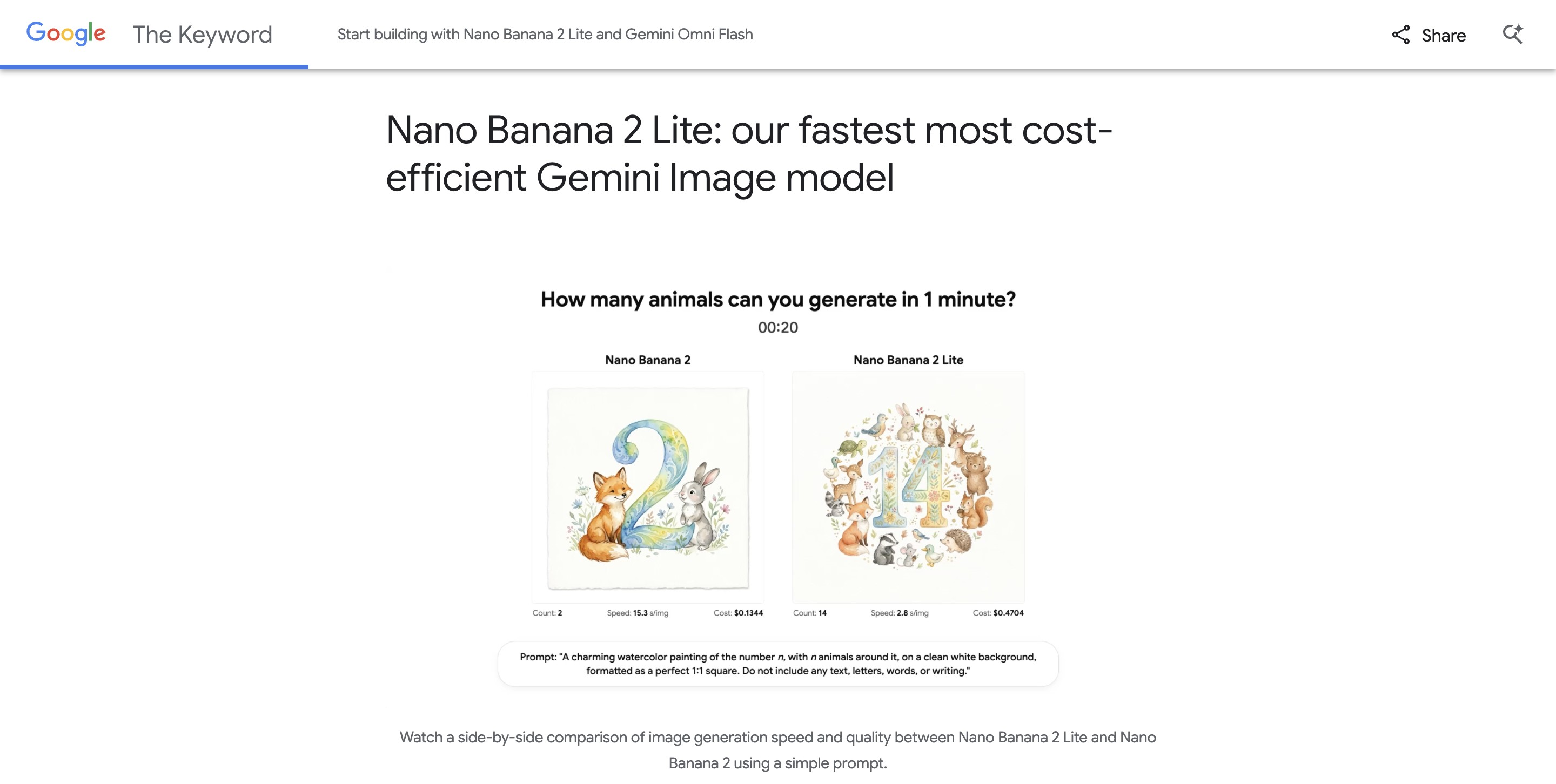
Nano Banana 2 Lite - Google发布的轻量版 AI 图像生成模型
Nano Banana 2 Lite(gemini-3.1-flash-lite-image)是Google发布的AI图像生成模型,定位为Nano Banana家族中速度最快、成本最低的轻量版。可在约...
SeedMusic 1.0 - 字节跳动推出的第一代AI音乐生成模型
SeedMusic 1.0是字节跳动推出的第一代AI音乐生成模型,专注于将用户的文字创意快速转化为带有人声的完整歌曲草稿。用户只需输入一段描述、歌词或风格方向,可在几分钟内生成包含主歌、副歌、编曲和人...