meso- (chemistry)Claude Managed Agents - Anthropic 推出的 Agent 操作系统
Claude Managed Agents 是 Anthropic 官方推出的 Agent 操作系统,通过解耦 Brain(模型决策)、Hands(执行环境)与 Session(状态持久化)三大核心组...

meso- (chemistry)MMX-CLI - MiniMax 推出面向 AI Agent 的全模态命令行工具
MMX-CLI 是 MiniMax(稀宇科技)发布的面向 AI Agent 的全模态命令行工具。支持在 Claude Code、OpenClaw 等环境中原生调用 MiniMax 的编程、视频生成、语...
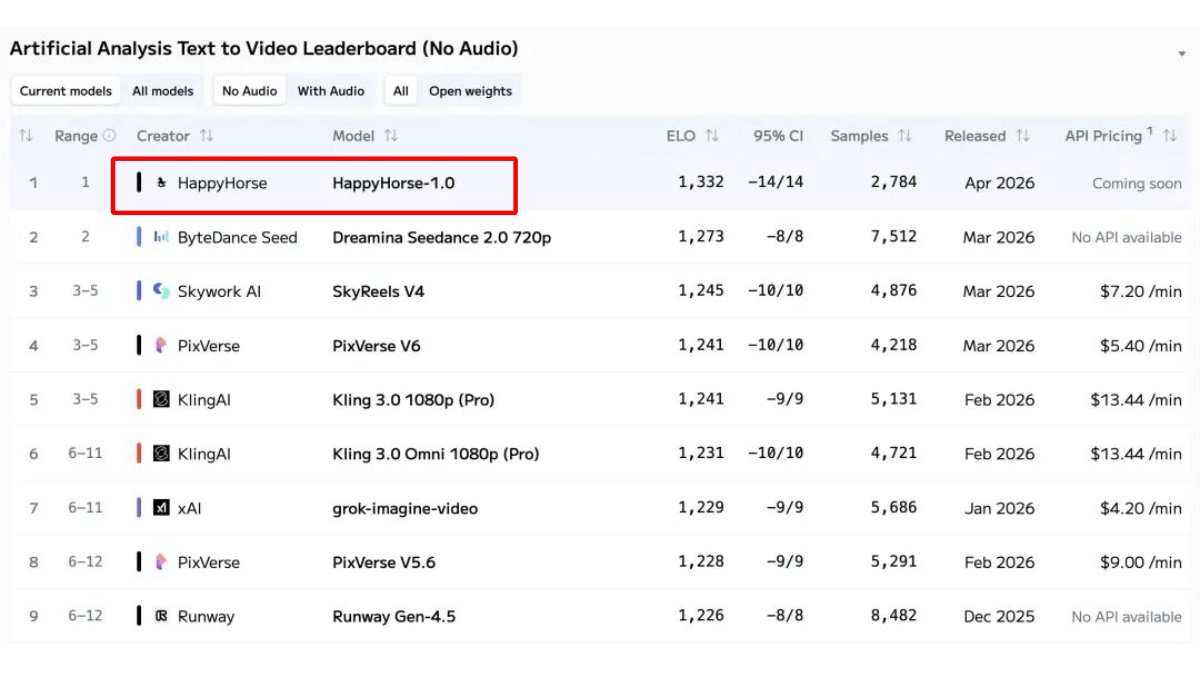
meso- (chemistry)HappyHorse-1.0 - 阿里ATH创新事业部开源的AI视频生成模型
HappyHorse-1.0(欢乐马)是阿里ATH创新事业部发布的开源AI视频生成模型,以150亿参数、40层单流Transformer架构实现原生音视频同步生成。模型在Artificial Anal...
meso- (chemistry)MAI-Transcribe-1 - 微软AI团队推出的自研多语言语音识别模型
MAI-Transcribe-1是微软AI团队推出的首款自研多语言语音识别模型,作为MAI模型家族的新成员,在FLEURS基准测试中实现了约3.9%的词错误率,显著超越OpenAI Whisper-l...
meso- (chemistry)OmniWeaving - 浙大、腾讯混元联合南洋理工开源的统一视频生成模型
OmniWeaving是浙江大学、腾讯混元与南洋理工大学联合发布的开源统一视频生成模型,模型采用MLLM(Qwen2.5-VL)+ MMDiT + VAE三层架构,通过激活多模态大模型的"思考模式"进...
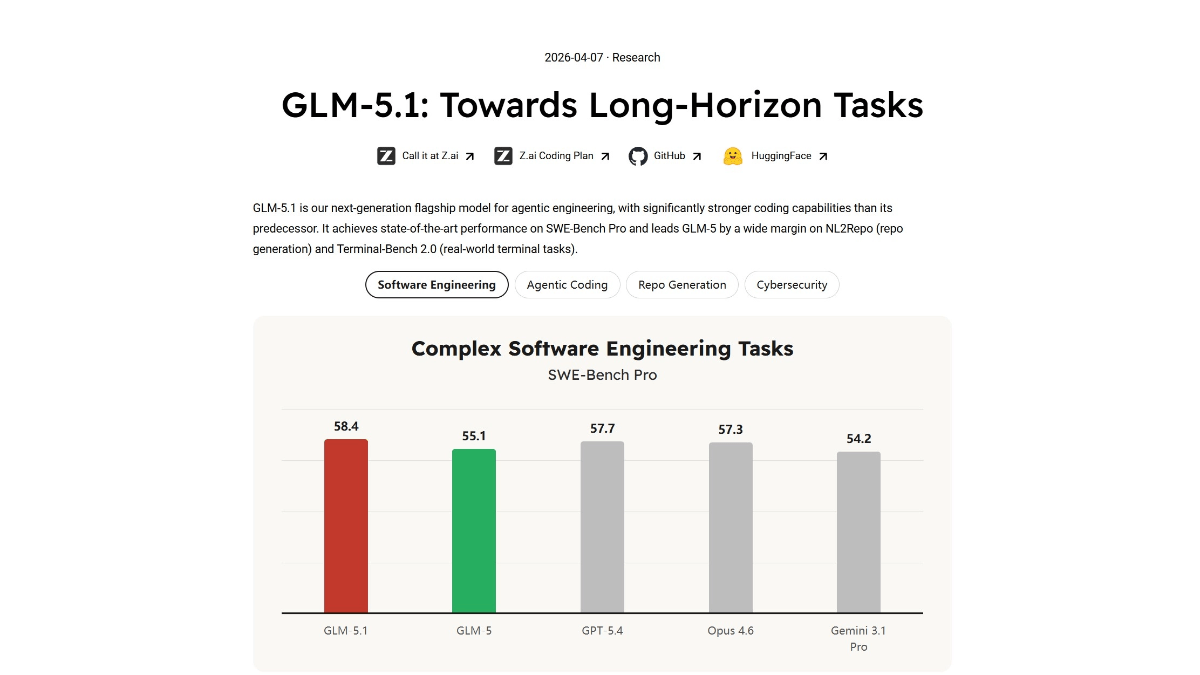
meso- (chemistry)GLM-5.1 - 智谱AI推出的744B参数开源旗舰模型
GLM-5.1是智谱AI推出的744B参数开源旗舰模型,采用MIT许可可自由商用,上下文窗口达20万token,专为长程智能体工程设计,支持单任务连续自主执行8小时、完成1700+步骤的复杂工作流。在...
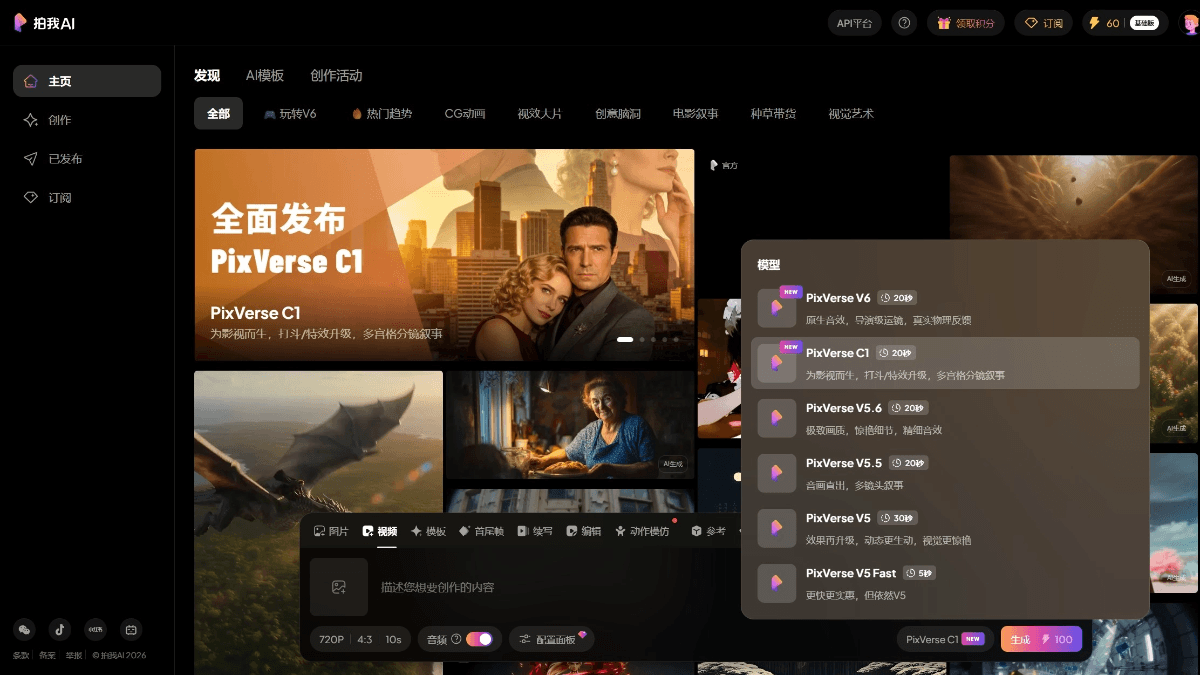
meso- (chemistry)PixVerse C1 - 爱诗科技推出全球首个面向影视行业的专业视频大模型
PixVerse C1是爱诗科技推出的全球首个面向影视行业的专业视频大模型,专为短剧、动漫与漫剧创作打造。模型支持15秒1080P高清视频生成,具备原生音画同步能力,出片即自带音效,告别后期配音。
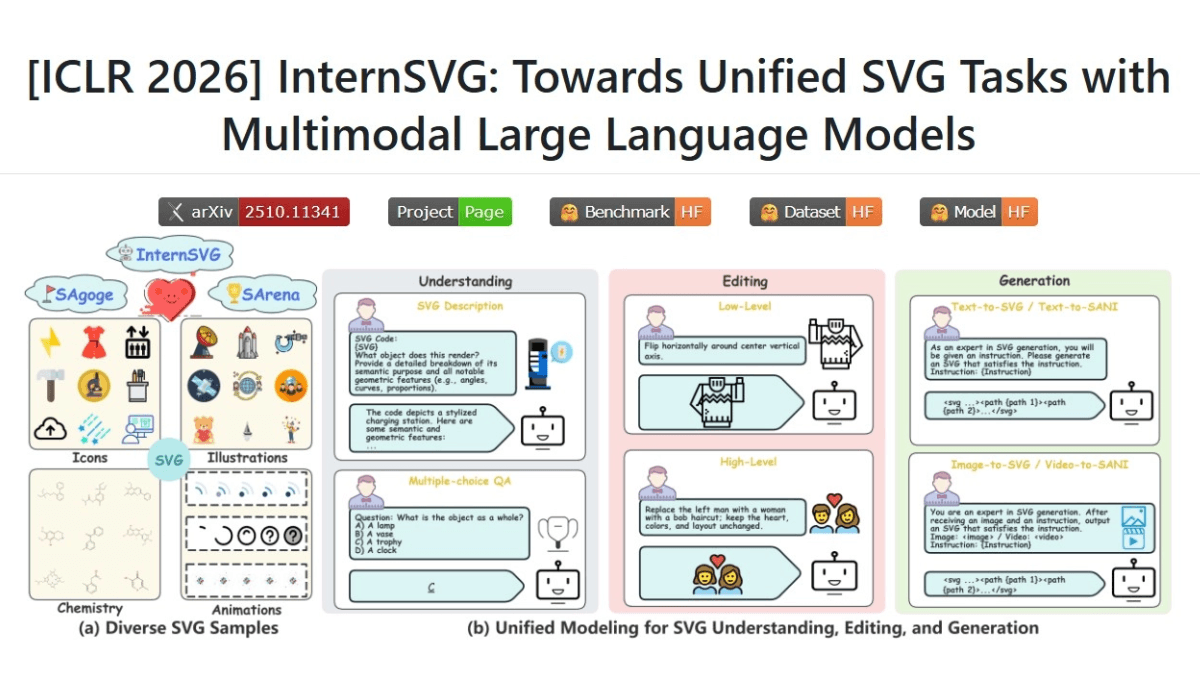
meso- (chemistry)InternSVG - 上海AI实验室联合多所高校推出的统一矢量图形智能系统
InternSVG 是上海AI实验室联合上海交通大学、南京大学等机构推出的统一矢量图形智能系统,系统基于多模态大语言模型(MLLM),首次实现了SVG理解、编辑、生成三大任务的统一建模
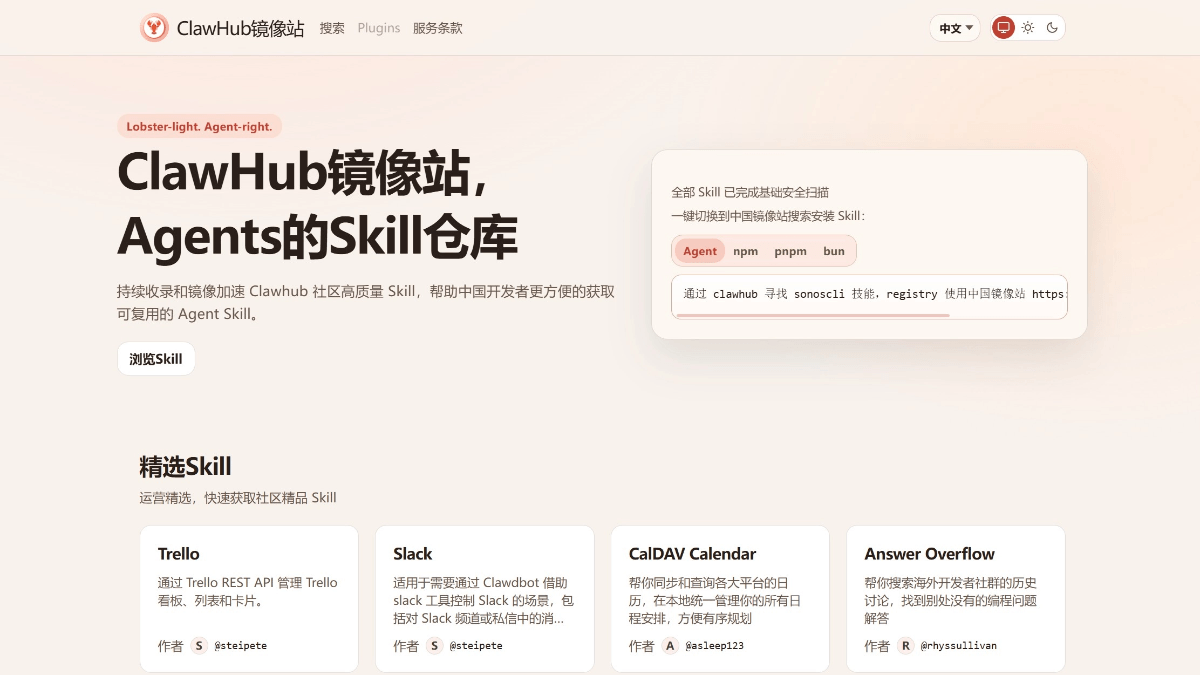
ClawHub中国镜像站 - OpenClaw官方推出的技能市场本地化站点
ClawHub中国镜像站是OpenClaw官方推出的技能市场本地化站点,是字节跳动BytePlus及火山引擎提供基础设施支持。镜像站专为解决国内开发者访问原站速度慢、API受限等痛点而设,提供完整中文...

Wan2.7-Video - 阿里通义实验室推出的新一代 AI 视频生成模型系列
Wan2.7-Video 是阿里通义实验室推出的新一代 AI 视频生成模型系列,由文生视频(Wan2.7-t2v)、图生视频(Wan2.7-i2v)、参考生视频(Wan2.7-r2v)和视频编辑(Wa...