
DeepSeek released the first open source version of its v3 model, now with the strongest code capabilities (in China)
DeepSeek-V3 is a powerful Mixture-of-Experts (MoE) language model with 671 billion total parameters and 3.7 billion parameters activated for each token. The model employs an innovative multi-head potential attention (Mu...
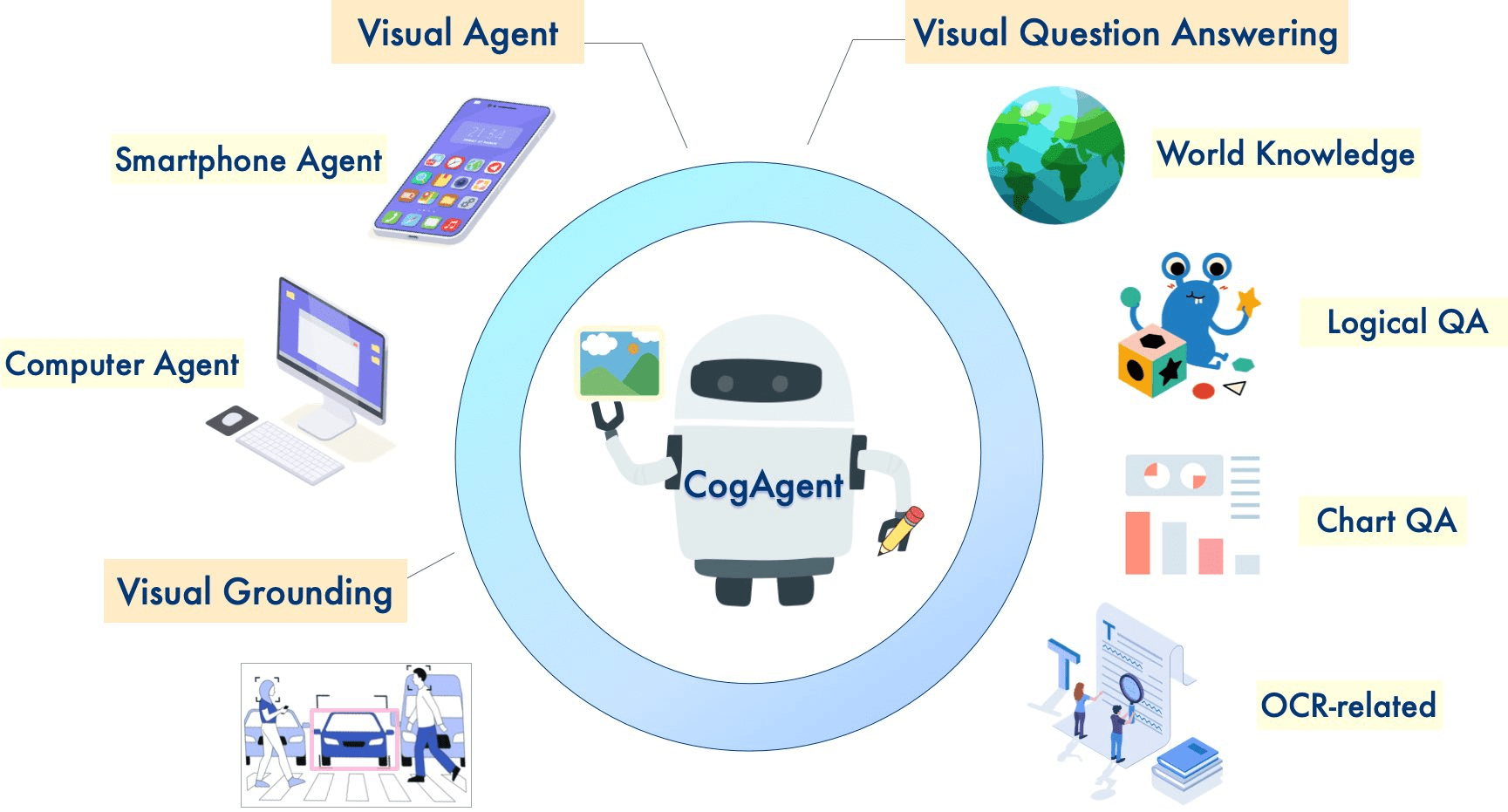
CogAgent: Smart Spectrum's open source intelligent visual language model for automating graphical interfaces
Comprehensive Introduction CogAgent is an open source visual language model developed by Tsinghua University Data Mining Research Group (THUDM), aiming to automate the operation of cross-platform graphical user interface (GUI). The model is based on CogVLM (GLM-4V-9B) and supports bilingual Chinese and English...
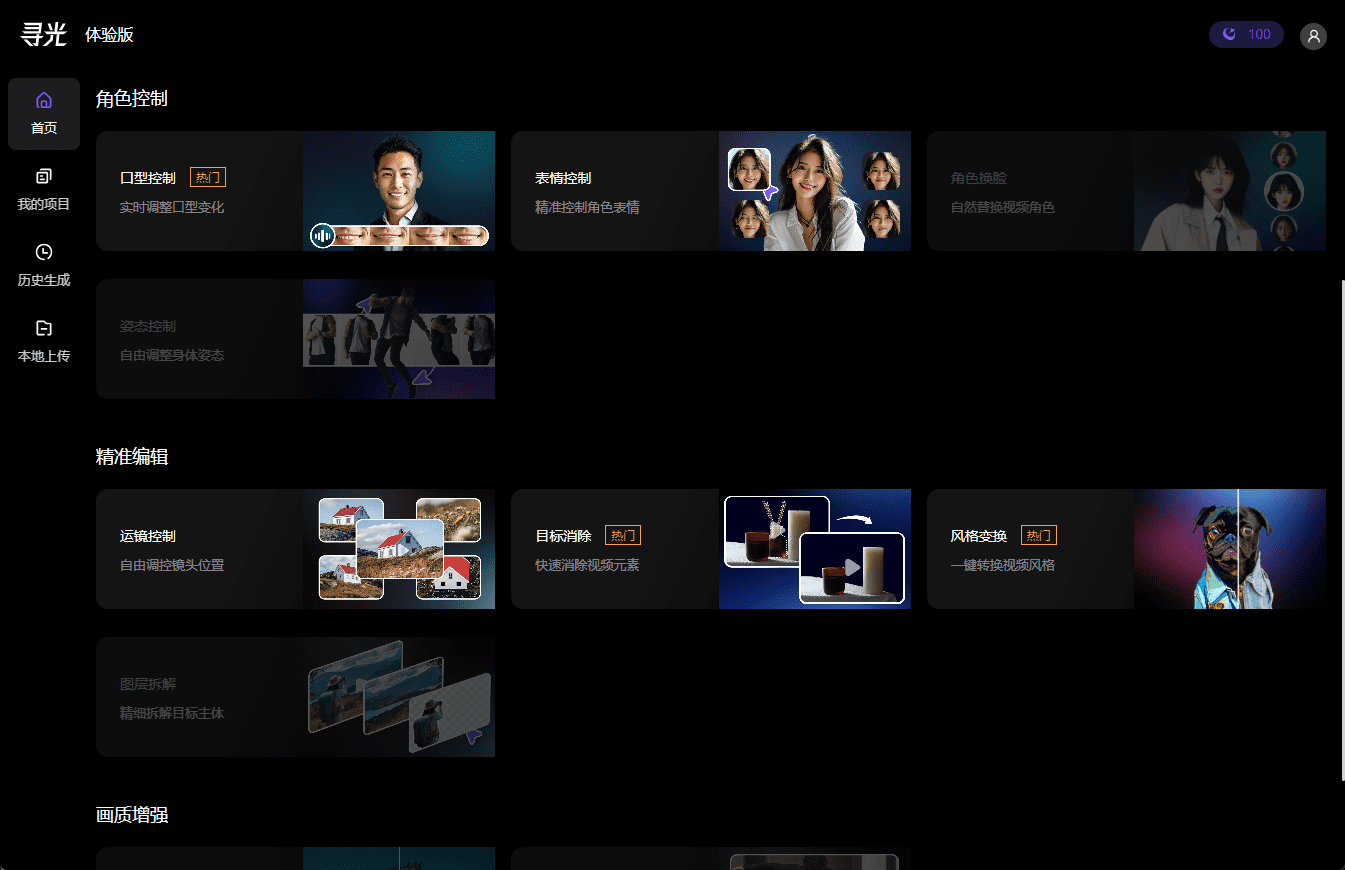
Dharma Institute's "Searchlight" Video Creation Platform Full Review
Earlier today, I received a notification that my application for internal testing of "Searchlight" was approved, so I'll post a brief review before I go to bed. The platform is positioned as the "visual technology capability application platform" of Dharma Institute, and there are fewer applications at present (compared to the launch), and we are looking forward to gradually opening up more visual applications. The search for light is divided into two addresses: https...
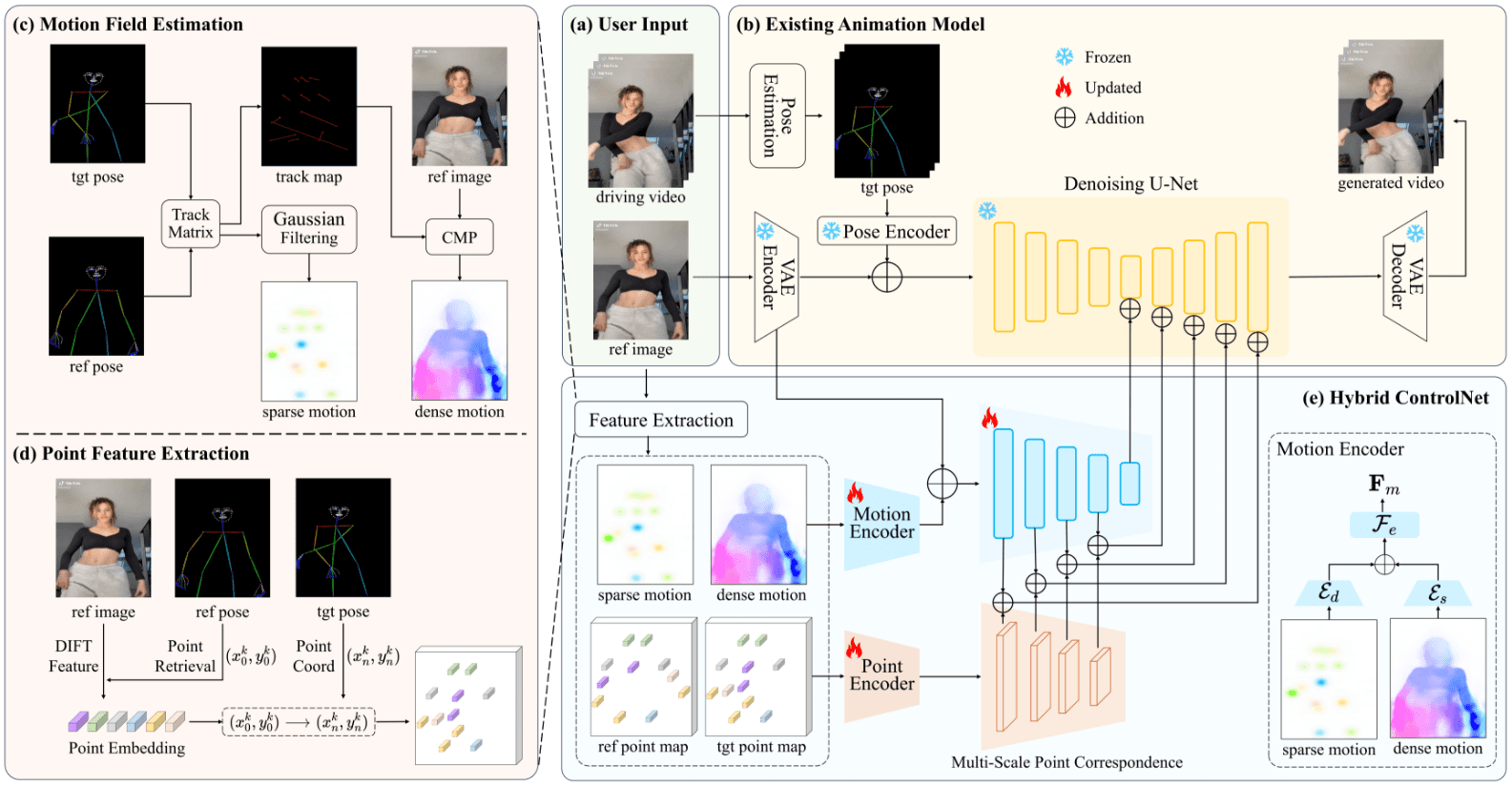
DisPose: generating videos with precise control of human posture, creating dancing ladies
General Introduction DisPose is an innovative open source artificial intelligence project focused on controlled character image animation generation. Developed by a team of researchers and open-sourced on GitHub, the project uses advanced deep learning techniques to achieve precise character animation control by decomposing skeletal pose information.D...

Smolagents: open source project for rapid development of AI intelligences and lightweight construction of intelligences
Comprehensive Introduction Smolagents is a lightweight intelligent agent library developed by HuggingFace that focuses on simplifying the development process of AI agent systems. The project is known for its clean design philosophy, with only about 1000 lines of core code, yet provides powerful feature integration capabilities. It is most ...

Combined cue word commands by visually extracting documents as Markdown formatted documents
This command comes from the Vision Parse project and extracts markdown documents in two steps. Image analysis prompt (img_analysis.prompt): Analyze this image and retur...

Napkin AI Chinese Beginner's Guide
How to start generating visual content with Napkin AI ? (Account creation, visual generation, export to pdf or image file...) Welcome to Napkin AI, a tool that makes it easy to convert your text into beautiful visuals. This guide will walk...

Vision Parse: Intelligent Conversion of PDF Documents to Markdown Format Using Visual Language Models
Comprehensive Introduction Vision Parse is a revolutionary document processing tools, it cleverly combines the most advanced visual language models (Vision Language Models) technology, to be able to intelligently convert PDF documents into high-quality Markdown format ...
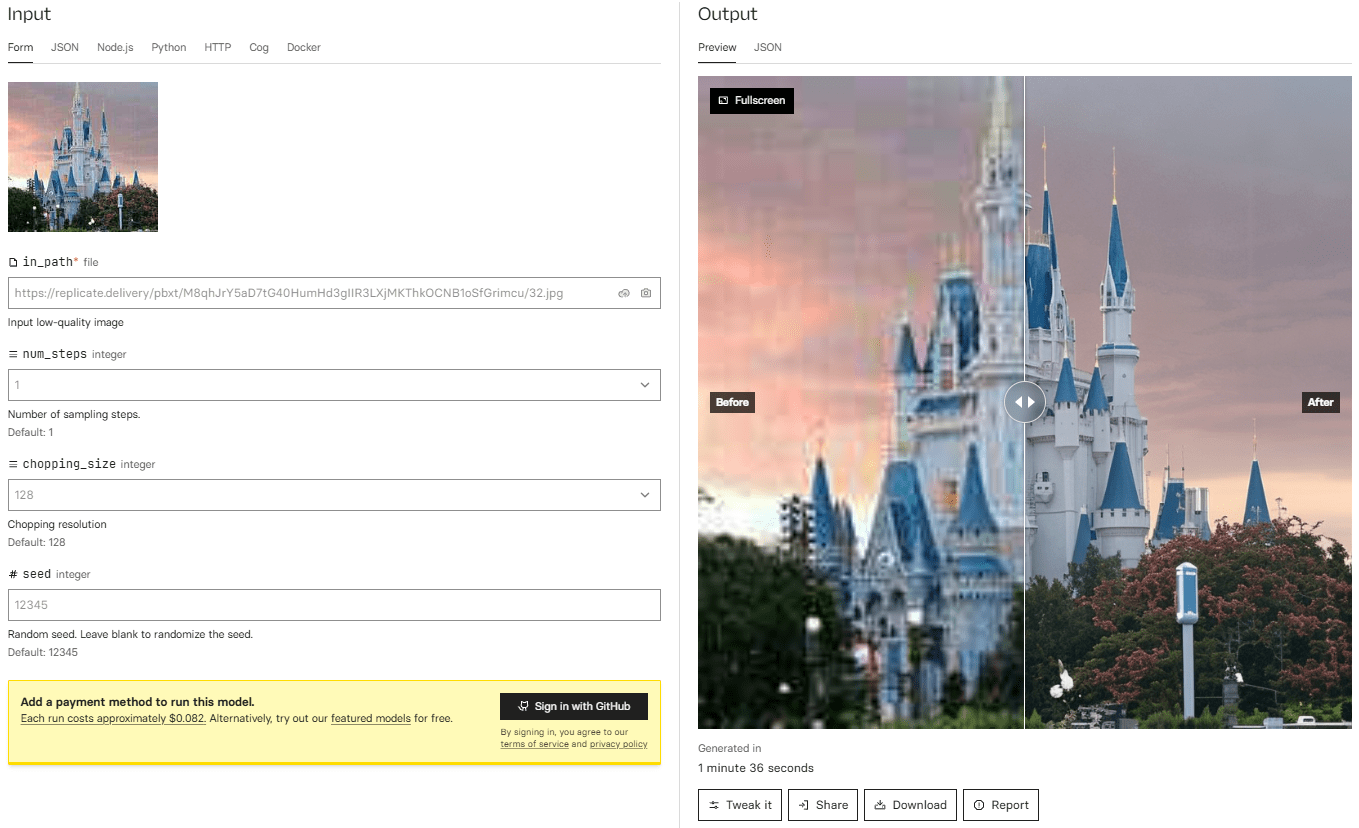
InvSR: Open source image super-resolution project to improve the quality of image resolution
General Introduction InvSR is an innovative open-source image super-resolution project based on diffusion inversion techniques capable of converting low-resolution images into high-quality, high-resolution images. The project utilizes the rich a priori knowledge of images embedded in pre-trained large-scale diffusion models to support, through a flexible sampling mechanism, the...
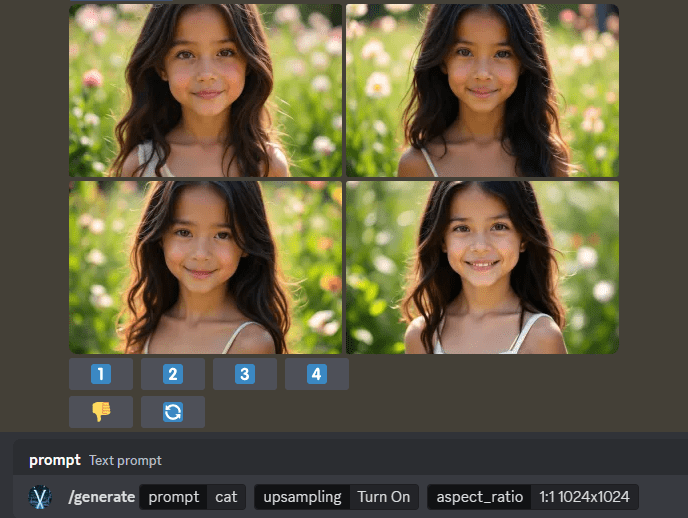
Infinity: bitwise autoregressive modeling for generating high-resolution images for unlimited high-resolution image generation
General Introduction Infinity is a groundbreaking high-resolution image generation framework developed by the FoundationVision team. The project breaks through the limitations of traditional image generation models through an innovative bit-level visual autoregressive modeling approach.The core features of Infinity...