
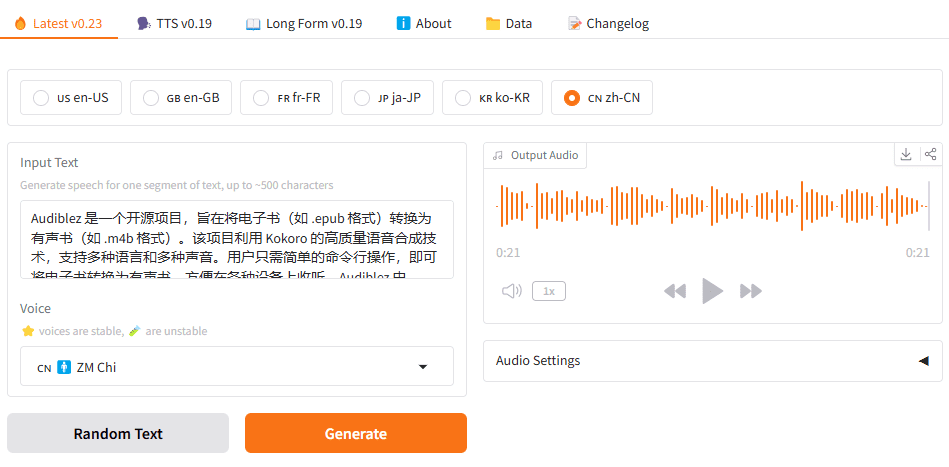
AnyText: Generate and edit multi-language image text, highly controllable to generate multiple lines of Chinese in the image

General Introduction
AnyText is a revolutionary multilingual visual text generation and editing tool developed based on the diffusion model. It generates natural, high-quality multilingual text in images and supports flexible text editing capabilities. Developed by a team of researchers and awarded Spotlight honors at ICLR 2024, AnyText's core strength lies in its unique two-module architecture: an auxiliary latent module encodes text glyph, position, and masked image information, and a text embedding module processes stroke data using an OCR model. The project also provides the AnyWord-3M dataset, the first multilingual text image dataset containing 3 million pairs with OCR annotations, which provides an important evaluation benchmark for the field of visual text generation.


Experience: https://modelscope.cn/studios/damo/studio_anytext/summary
Alternate address: https://huggingface.co/spaces/modelscope/AnyText
Function List
- Multi-language text generation: support for generating multi-language text in images
- Text Editor: You can edit and modify the text content in the existing image.
- Style control: support for changing the style of generated text via the base model or LoRA model
- FP16 Inference Acceleration: Supports fast inference, runs on GPUs with 8GB or more video memory
- Chinese and English translation: built-in Chinese and English translation model, support for direct input of Chinese prompt words
- Customized fonts: allows users to use their own font files
- Batch Processing: Supports batch generation and editing of image text
- Model merging: support for merging community model and LoRA model weights
Using Help
1. Environmental installation
- First make sure Git is installed on your system:
conda install -c anaconda git
- Clone the project code:
git clone https://github.com/tyxsspa/AnyText.git
cd AnyText
- Prepare the font file (Arial Unicode MS is recommended):
mv your/path/to/arialuni.ttf ./font/Arial_Unicode.ttf
- Create and activate the environment:
conda env create -f environment.yaml
conda activate anytext
2. Methods of use
2.1 Quick start
The easiest way to verify this is to run the following command:
python inference.py
2.2 Launching an interactive presentation
The demo interface is recommended for better configured GPUs (8GB or more video memory):
export CUDA_VISIBLE_DEVICES=0 && python demo.py
2.3 Advanced configuration
- Use FP32 precision and disable the translator:
export CUDA_VISIBLE_DEVICES=0 && python demo.py --use_fp32 --no_translator
- Use custom fonts:
export CUDA_VISIBLE_DEVICES=0 && python demo.py --font_path your/path/to/font/file.ttf
- Load specific checkpoints:
export CUDA_VISIBLE_DEVICES=0 && python demo.py --model_path your/path/to/your/own/anytext.ckpt
3. Stylistic adjustments
In the demo interface, the style of the generated text can be adjusted in two ways:
- Change base model: fill in the path of local base model in [Base Model Path].
- Load LoRA model: enter the LoRA model path and weight ratio in [LoRA Path and Ratio], for example:
/path/of/lora1.pth 0.3 /path/of/lora2.safetensors 0.6
4. Performance optimization
- Default FP16 inference is used, with both Chinese and English translation models loaded (taking up about 4GB of video memory)
- If FP16 is used and no translation model is used, a single 512x512 image requires only about 7.5GB of video memory.
- The first time it is run, the model files are downloaded to the
~/.cache/modelscope/hubcatalogs - This can be done by setting the environment variable
MODELSCOPE_CACHEModify the download directory
5. Cautions
- Ensure that the correct version of the dependency package is installed
- Use of custom fonts may affect generation
- The first run of the model requires the download of relevant files
- Recommended to run with a GPU with 8GB of video memory and above
AnyText generate images operation instructions
running example
AnyText has two modes of operation: text generation and text editing, each mode provides a wealth of examples, choose one and click [Run!
Please note that before running the example, make sure the hand-drawn location area is empty to prevent affecting the example results, in addition, different examples use different parameters (such as resolution, number of seeds, etc.), if you want to generate your own, please pay attention to the parameter changes, or refresh the page to revert to the default parameters.
Text Generation
In the Prompt to enter the description of the prompt word (support for Chinese and English), the need to generate each line of text wrapped in double quotes, and then sequentially hand-drawn to specify the location of each line of text to generate images. Text position drawing is very critical to the quality of the picture, please do not draw too random or too small, the number of positions should be the same as the number of lines of text, the size of each position should be matched with the length or width of the corresponding line of text as far as possible. If you can't draw by hand (Manual-draw), you can try to drag the box rectangle (Manual-rect) or random generation (Auto-rand).
When generating multiple lines, each position is sorted according to certain rules to correspond with the text lines, and the Sort Position option is used to determine whether the sorting is prioritized from top to bottom or from left to right. You can turn on the Show Debug option in the parameter settings to observe the text position and glyphs in the result image. You can also check the Revise Position option, which will use the outer rectangle of the rendered text as the corrected position, but occasionally found that the text generated this way is slightly less creative.
copy editor
Please upload a picture to be edited as a reference picture (Ref), then after adjusting the stroke size, paint the position to be edited on the reference picture, and enter the description prompt word and the text content to be modified in the Prompt to generate the picture.
The reference image can be of any resolution, but internal processing restricts the long side to no more than 768, and the width and height are scaled to an integer multiple of 64.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...