
AI full-stack tool open source! Take you with Ollama+Qwen2.5-Code runbolt.new, one click to generate a website!

AI programming tools have been very hot lately, from Cursor, V0, Bolt.new and most recently Windsurf.
In this post, we'll start by talking about the open source solution - Bolt.new - which has generated $4 million in revenue in just four weeks since the product went live.

Unhelpfully the siteDomestic access speed limitationsandFree Token quota is limitedThe
How to run it locally so that more people can use it and accelerate AI on the ground is Monkey's mission.
Share of the Day.Takes you through a large model deployed with local Ollama, driving bolt.newThe realization of AI programming Token Freedom.
1. Introduction to Bolt.new
Bolt.new It is a SaaS-based AI coding platform, with the underlying LLM-driven intelligences, combined with WebContainers technology, which enables coding and running within the browser, with the advantages of:
- Support front-end and back-end development at the same time.;
- Visualization of project folder structure.;
- Environment is self-hosted with automatic installation of dependencies (e.g. Vite, Next.js, etc.).;
- Running a Node.js server from deployment to production
BoltThe goal of .new is to make web application development more accessible to a wider range of people, so that even programming novices can realize ideas through simple natural language.
The project has been officially open-sourced: https://github.com/stackblitz/bolt.new
However, the official open source bolt.new supports limited models, and many of our domestic partners are unable to call the overseas LLM API.
There's a god in the community. bolt.new-any-llmThe local Ollama model, take a hands-on look below.
2. Qwen2.5-Code local deployment
Some time ago, Ali open-sourced the Qwen2.5-Coder series of models, of which the 32B model has achieved the best open-source results in more than ten benchmark evaluations.
It deserves to be the world's most powerful open source model, surpassing even GPT-4o in several key capabilities.
The Ollama model repository is also live for qwen2.5-coder:
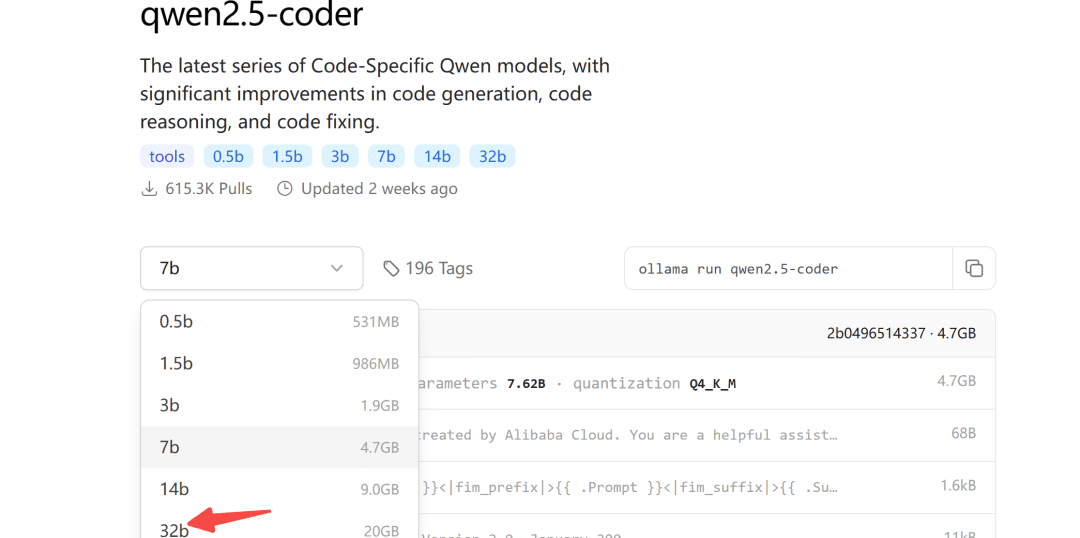
Ollama is a gadget-friendly tool for deploying large models.
2.1 Model Download
Regarding the size of the model to be downloaded, you can choose it according to your own video memory, at least 24G of video memory should be ensured for the 32B model.
Below we demonstrate this with the 7b model:
ollama pull qwen2.5-coder
2.2 Model modifications
Since Ollama's default maximum output is 4096 tokens, it is clearly insufficient for code generation tasks.
To do this, the model parameters need to be modified to increase the number of context Token.
First, create a new Modelfile file and fill it in:
FROM qwen2.5-coder
PARAMETER num_ctx 32768
Then, the model transformation begins:
ollama create -f Modelfile qwen2.5-coder-extra-ctx
After a successful conversion, view the model list again:

2.3 Model runs
Finally, check on the server side to see if the model can be called successfully:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx",
"messages": [
{ "role": "user", "content": '你好'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
text = response.json()['message']['content']
print(text)
else:
print(f'{response.status_code},失败')
If there's nothing wrong, you can call it in bolt.new.
3. Bolt.new running locally
3.1 Local deployment
step1: Download bolt.new-any-llm which supports local models:
git clone https://github.com/coleam00/bolt.new-any-llm
step2: Make a copy of the environment variables:
cp .env.example .env
step3: Modify the environment variable toOLLAMA_API_BASE_URLReplace it with your own:
# You only need this environment variable set if you want to use oLLAMA models
# EXAMPLE http://localhost:11434
OLLAMA_API_BASE_URL=http://localhost:3002
step4: Install dependencies (with node installed locally)
sudo npm install -g pnpm # pnpm需要全局安装
pnpm install
step5: one-click operation
pnpm run dev
Seeing the following output indicates a successful startup:
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
3.2 Demonstration of effects
Open in browserhttp://localhost:5173/The Ollama type model is selected:
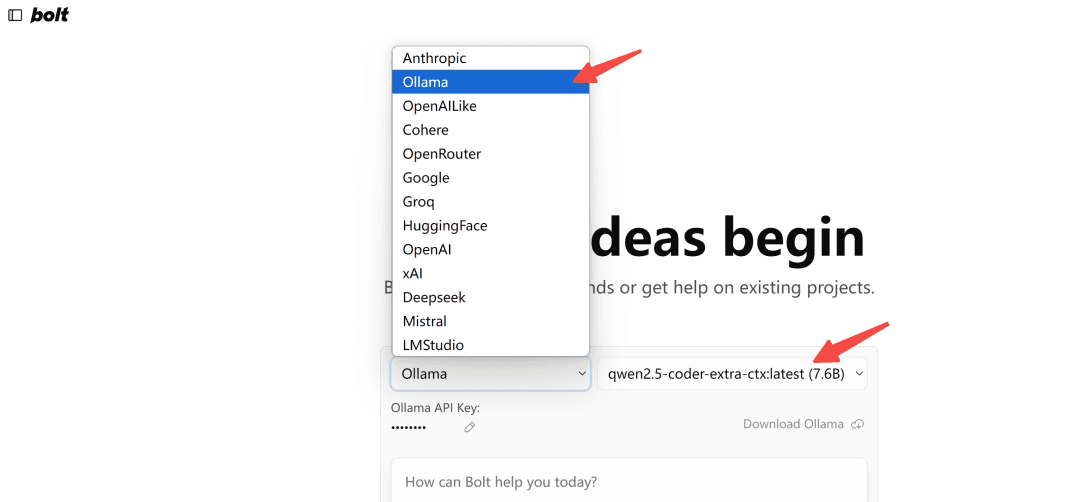
Note: The first time it loads, if it doesn't pull up the model in Ollama, refresh it a few times to see what it looks like.
Let's put it to the test.
写一个网页端贪吃蛇游戏
On the left.流程执行area, and to the right is the代码编辑area, below which is the终端Area. Writing code, installing dependencies, and terminal commands are all taken care of by AI!
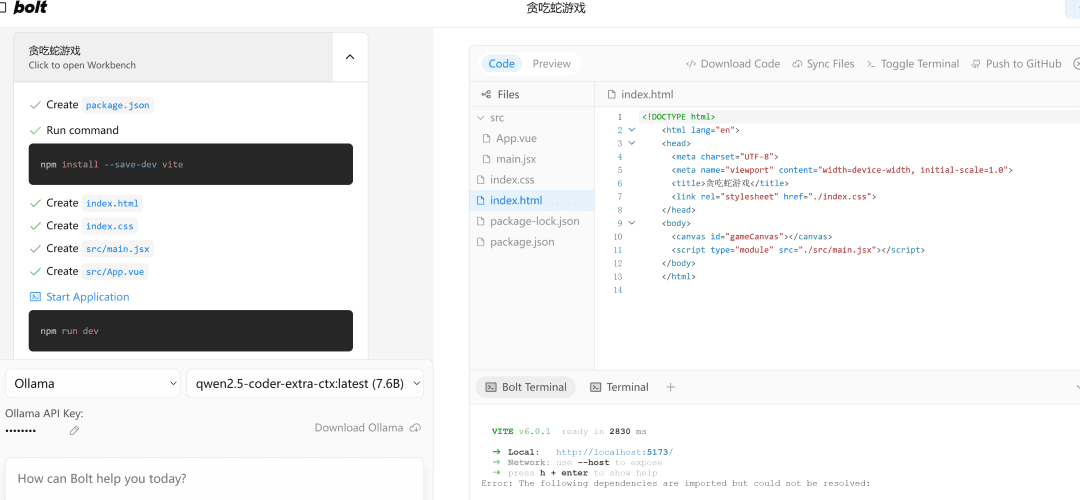
If it encounters an error, just throw it at it, execute it again, and if there's nothing wrong with it, the right-hand sidePreviewThe page will open successfully.
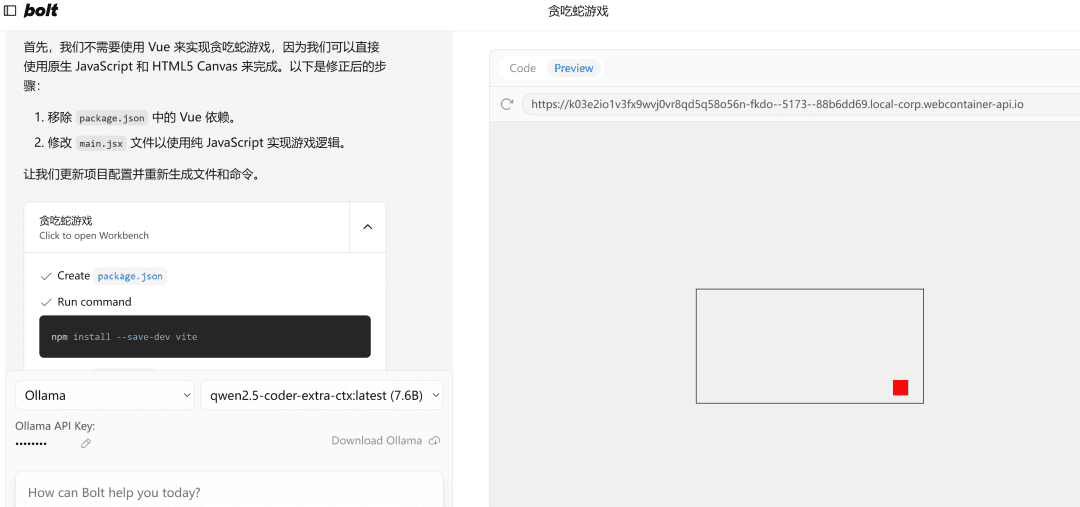
Note: Since the example uses a small 7b model, if you need to, you can try to use a 32b model, the effect will be significantly improved.
put at the end
This article takes you through a local deployment of the qwen2.5-code model and successfully drives the AI programming tool bolt.new.
Use it to develop the front-end project is still quite powerful, of course, to use it well, know some basic concepts of front and back end, will be twice as effective.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...