
AI Engineering Academy: 2.16 GraphRAG (Graph Structure Based Retrieval Augmentation Generation Method)

introductory
GraphRAG (Graph Structure Based Retrieval Augmented Generation) is an advanced retrieval and generation method. It combines the advantages of graph data structures and the capabilities of Large Language Modeling (LLM) to overcome traditional RAG Some limitations of the system.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/11_Graph_RAG
locomotive
While traditional RAG systems perform well when retrieving against queries, they struggle in the following scenarios:
- Understand the complex relationships between different pieces of information.
- Handle queries that require extensive contextual or subject matter understanding.
- Efficiently process and retrieve information from large, diverse data sets.
GraphRAG provides a more context-aware response by using graph structures to represent and navigate information.
Methodological details
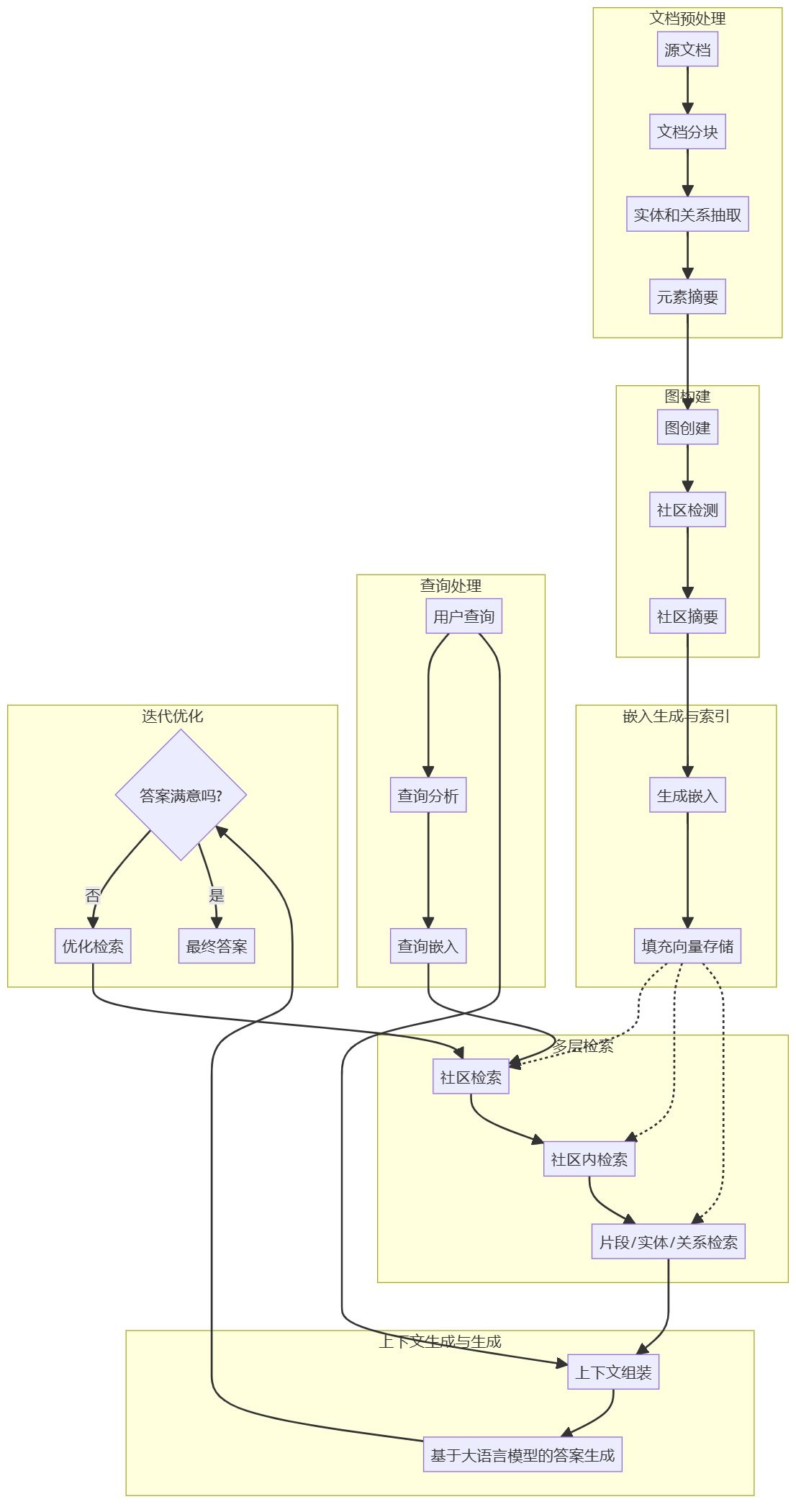
Document preprocessing and vector store creation
- document ingestion: Processes the source document and breaks it into smaller chunks.
- Entity and Relationship Extraction: Analyze each document block to extract entities and the relationships between them.
- Element Summarization: Summarize the extracted entities and relationships into descriptive text blocks.
- Graph Structure Construction: Create a graph structure with entities as nodes and relationships as edges.
- Community testing: Grouping of graphs using algorithms such as Hierarchical Leiden.
- Community summarization: A summary is generated for each community to extract its core content.
- Embedding Vector Generation: Generate embedding vectors for document blocks, entities, relationships and community summaries.
- vector storage: Store these embedding vectors in a vector database for efficient retrieval.
Retrieval Enhancement Generation Workflow
- Analyze user queries to identify key entities and topics.
- multilevel search::
- Retrieve the community associated with the query.
- Within these communities, specific document blocks, entities and relationships are further retrieved.
- Integrate retrieved information into a consistent context.
- Use the LLM to generate the final response.
- If needed, perform iterative retrieval and generation to optimize the final result.
Core Features of GraphRAG
- Hierarchical information representation: Supports information retrieval at different levels of granularity.
- Relational contextual understanding: Effective use of correlations between information.
- scalability: A community organization-based approach capable of efficiently processing large data sets.
- Flexible query support: From fact-specific queries to broad subject queries can be effectively supported.
- Interpretable Search: The graph structure visualizes the information retrieval path.
Advantages of this method
- Improved contextual understanding: GraphRAG can provide more contextually relevant answers.
- Enhance subject matter cognitive skills: community grouping facilitates comprehension of queries related to a wide range of topics.
- Reducing the probability of hallucinations: structured retrieval mechanisms reduce LLM response bias.
- Scalability: GraphRAG is more suitable for large and diverse datasets than traditional methods.
- Flexibility: for multiple types of queries, from fact-core to subject mining.
reach a verdict
GraphRAG provides a smarter, more efficient and context-aware solution for retrieval-enhanced generation by introducing a graph-based retrieval approach. This approach expands the possibilities for building intelligent AI systems.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...