
AI Engineering Academy: 2.15 ColBERT RAG (BERT-based post-contextual interaction model)

ColBERT (Contextualized Post-Cultural Interaction based on BERT) is different from the traditional dense embedding model. The following is a brief description of how ColBERT works:
- Token Layer Embedding: Unlike creating individual vectors directly for an entire document or query, ColBERT creates a single vector for each Token Creates the embedding vector.
- post-interaction: When computing the similarity between a query and a document, each query Token is compared to each document Token, instead of directly comparing the overall vector.
- MaxSim Operation: For each query Token, ColBERT finds its maximum similarity to any Token in the document and sums it to get the final similarity score.
Notes: https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/10_ColBERT_RAG
The next step is to show in graphical detail how ColBERT is used in the RAG work in the flow, emphasizing its Token level processing and post-interaction mechanisms.
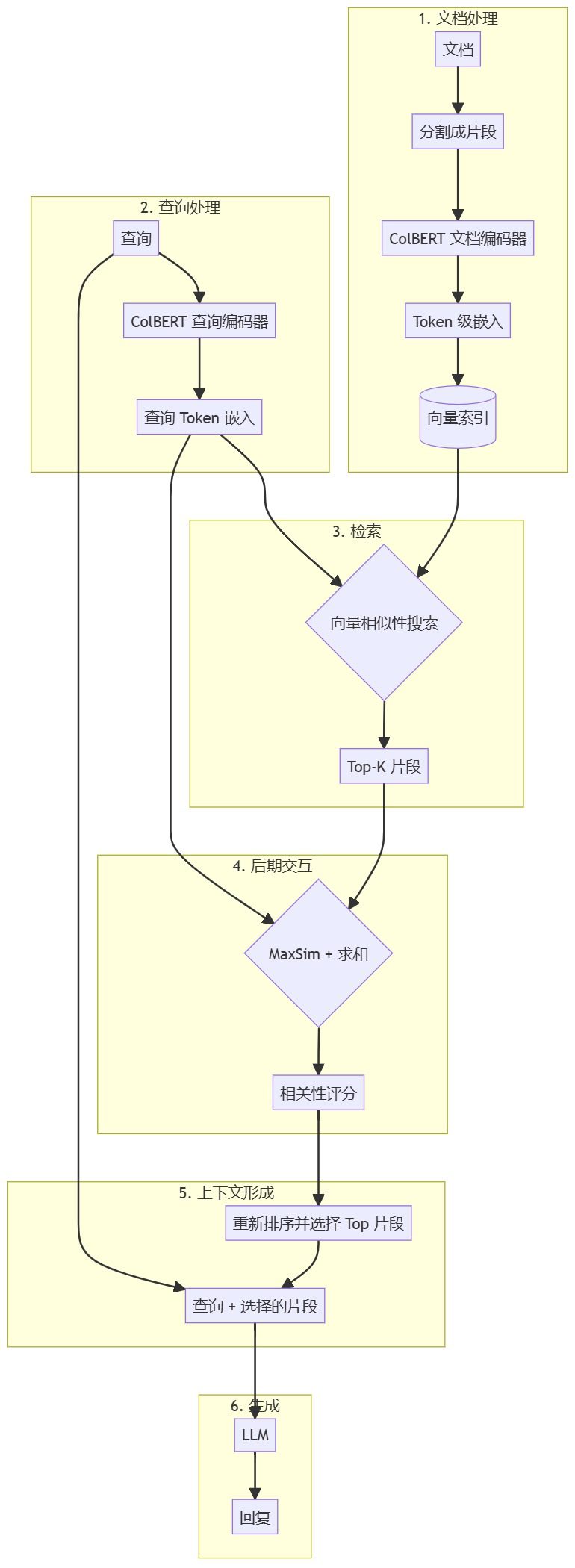
This diagram shows the overall architecture of the ColBERT-based RAG pipeline, emphasizing the Token-level processing and post-interaction in the ColBERT approach.
Now, let's create a more detailed diagram highlighting ColBERT's Token-level embedding and post-interaction mechanisms:

This chart illustrates:
- How documents and queries are processed as Token-level embeddings through BERT and linear layers.
- How each Query Token is compared to each Document Token in the post-interaction mechanism.
- MaxSim operation and its subsequent summation step to generate the final correlation score.
These diagrams show more accurately how ColBERT works in the RAG pipeline, highlighting its token-level approach and late interaction mechanisms. This approach allows ColBERT to retain finer-grained information from queries and documents, resulting in more granular matches and potentially superior retrieval performance compared to traditional dense embedding models.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...