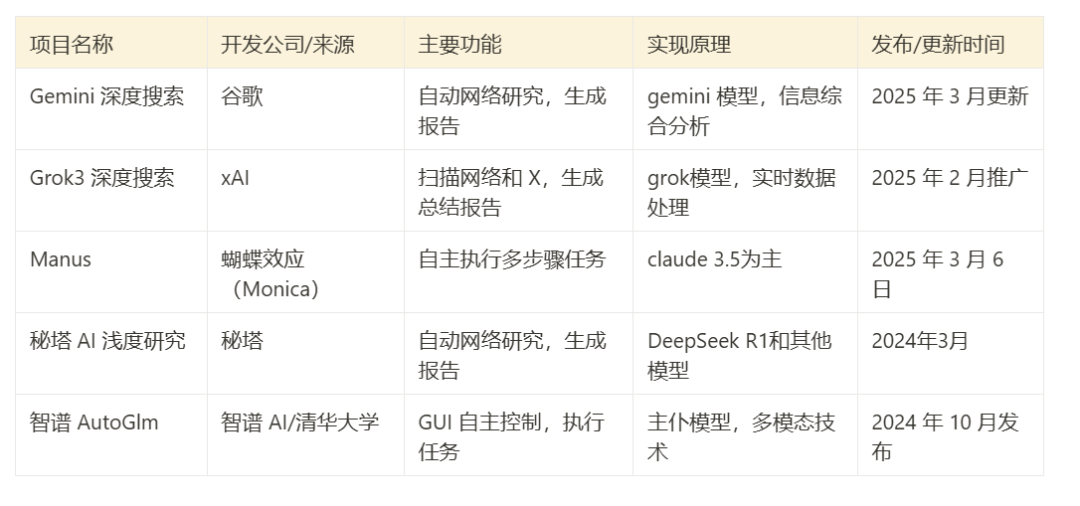
AI Research Assistant Competition: In-depth Review and Selection Guide of Five Mainstream Tools

The rise of AI research assistants: who can really help you with your homework?
Research in the information age often means trudging through massive amounts of data. In the past, researchers needed to manually search, sift, and organize information before feeding key content to people like ChatGPT Such large language models are analyzed. But with the launch of OpenAI's Deep Research feature, things are starting to change. These new AI tools promise to automate the entire research process: the user simply asks a question, and the AI autonomously searches the web, analyzes the data, and generates a report with citations. This is often driven by advanced big-language models, such as OpenAI's o3, which not only utilize pre-trained knowledge, but also proactively acquire the latest information and perform multi-step reasoning.
OpenAI's attempts quickly sparked the industry to follow.2023 Since March, several companies have launched their own automated research tools or AI agents (Agents), which are often referred to as "AI search assistants" or "deep research" tools. The core concept of these tools is similar: to utilize powerful AI modeling capabilities, combined with web search, to autonomously perform research tasks and deliver results.

This article looks at a few of these highly regarded products on the market, with the aim of exploring their performance differences, capability boundaries, and the best scenarios for each through a real-world test. The tools involved in this comparison include:
- Gemini Deep Search: Based on Google's Gemini Series of models that emphasize the ability to synthesize and analyze information.
- Grok 3 Deep Search: Utilizing xAI's Grok 3 model, designed to perform tasks independently, may be more focused on real-time information.
- Manus: a system that supports a wide range of AI models (e.g. Anthropic (used form a nominal expression) Claude and Ali's Qwen) platforms that are known for performing multi-step tasks.
- Mita AI Shallow Research: Combine its R1 model with a logical framework disassembly and use its own model to perform web search and integration.
- Zhipu AutoGLM: Based on Zhipu AI's large language model, it simulates user operations through a graphical user interface (GUI) to autonomously control digital devices for information collection and processing.
In order to understand the actual performance of these tools, we presented the same relatively complex research task to all five products.
Comparative testing: generating AI model studies
Mission Requirements:
Deliver an AI modeling research paper of approximately 5,000 words based on the following outline:
- Overview of contemporary large language models (e.g., GPT family, Claude, LLaMA, DeepSeek, etc.)
- Comparison of each model's characteristics and applicable scenarios
- Analysis of model capability boundaries and limitations
- Open vs. Closed Source Model Selection Strategies
- Model API Basics Tutorial
- A Concise Explanation of the Principles of Large Modeling Techniques
Implementation:
- Gemini Deep Search: Takes 8 minutes to search over 300 web pages.
- Grok 3 Deep Search: Took 6 minutes to search over 160 web pages.
- Manus: Took 21 minutes and reported 8 subtasks performed.
- Mita AI Shallow Research: 7 minutes to search over 300 web pages.
- Zhipu AutoGLM: Took 16 minutes to search 71 web pages.
Notes: The waiting time and search volume are only reference data for this test, and the actual performance may vary depending on task complexity, network conditions and server load.
Summary of responses from each tool:

(Images show some of the screenshots or summaries of the reports generated by each tool)
Independent evaluation: sharp review by Claude 3.7
In order to gain a relatively objective third-party perspective, we submitted the five generated reports to Anthropic's Claude 3.7 model for evaluation. Below is a summary of Claude 3.7's evaluation of each report:
Zhipu AutoGLM
The report tries to mimic the format of an academic paper by citing 71 references, but this is rather empty. The language is overly academic, as if the report is trying to cover up the lack of substance with fancy rhetoric. The analysis of the model's strengths and weaknesses is like a restatement of the product description, lacking in depth insight.
Manus
The report goes to the other extreme, oversimplifying complex technical issues in the name of "for policymakers" and turning in-depth analysis into superficial marketing copy. Like a children's book on quantum physics, it is neither in-depth nor accurate.
Gemini Deep Search
The report adopts an academic writing style, but extensive quotation marks interfere with the flow of reading. It is lengthy and takes up too much space explaining simple concepts without adding substantive information. Claiming to be aimed at non-technical people, the report is still full of unexplained jargon and fails to meet its objectives.
Grok 3 Deep Search
The availability of both concise and detailed versions is a feature, but it also exposes problems of consistency in content. The concise version is oversimplified, and some of the projections in the detailed version (e.g., for 2025) are somewhat speculative as they lack a sufficient basis for argumentation and the necessary assumptions to justify them.
Mita AI Shallow Research
The extensive use of tables to structure information improves the efficiency of information acquisition, but the over-reliance on tables and delimiters leads to a mechanized presentation of content that lacks narrative coherence and depth. The technical explanations are not sufficiently linked to practical application scenarios, and the analysis of business costs lacks differentiated considerations for enterprises of different sizes, making the recommendations seem "one-size-fits-all".
General observations on Claude 3.7:
These five reports all try to use different "packaging" to cover up the shortcomings in content. Whether they are academic, commercial or technical, they seem to have failed to touch the core - in-depth understanding of the nature of technology and in-depth thinking on practical applications. For example, the report's DeepSeek The excessive attention may reflect the industry's generalized pursuit of new technologies, while the downplaying of key issues such as data privacy and ethical compliance exposes the limitations of analytical perspectives. A good technology research report should provide insights and pragmatic analysis rather than playing with words. By this standard, all five reports have room for improvement.
Overall performance and scoring
Based on the evaluation of Claude 3.7 and a direct review of the report content, it is possible to make a comprehensive assessment of the performance of the tools in this test:
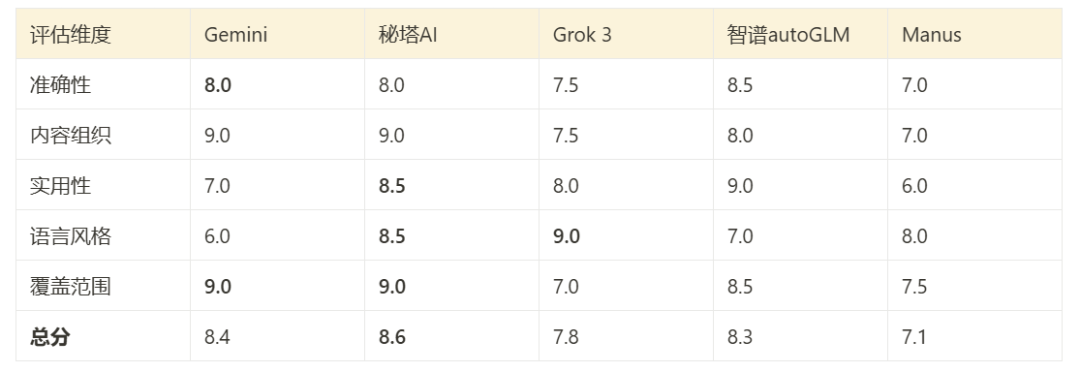
(Picture shows a composite scoring chart based on test results)
- Gemini Deep Search: Better content organization, wide coverage and multilingual support are its strengths.
- Mita AI Shallow Research: The performance is comprehensive and balanced, with a good combination between technical depth and readability.
- Grok 3 Deep Search: Flexible language style (dual version) and strong pragmatic orientation.
- Zhipu AutoGLM: Technical content is highly accurate, but readability is limited for non-specialists.
- Manus: The report is concise and easy to understand, but sacrifices depth of analysis.
How to choose: suggestions for use in different scenarios
Based on this test and the characteristics of each tool, here are some suggestions for selection:
Overview of search features:
- Gemini Deep Search: Search is broad and good at integrating global multilingual resources, but may not be as good as localized products at understanding in-depth Chinese content.
- Grok 3 Deep Search: Highly real-time, especially in business information and news, but with relatively weak depth of technical content.
- Zhipu AutoGLM: The references cited are of high quality, with a deep understanding of technical concepts, but the search is relatively focused.
- Mita AI Shallow Research: Strong integration of information in English and Chinese, more comprehensive coverage of areas of specialization, and accurate extraction of structured information.
- Manus:: (This test focused on report generation and its search features were not fully demonstrated, but the platform is designed to support the integration of information from multiple sources and complex workflows).
Preliminary ranking of search and research skills (based on this test):
- Mita AI Shallow Research: Outstanding performance in deep search in specialized areas, bilingual processing in English and Chinese.
- Gemini Deep Search: The most versatile and extensive coverage of global resources.
- Zhipu AutoGLM: Advantages in handling Chinese technical literature and deep understanding.
- Grok 3 Deep Search: Leading the way in access to real-time business information and news.
- Manus: Strengths may lie in the flexibility of task execution and multi-model invocations rather than pure search ranking.
Scenario-based recommendations:
- academic research: Priority was given to Zhipu AutoGLM (high quality of references), followed by Mita AI (specialized field coverage).
- Business Analysis: Priority is given to Grok 3 (real-time, business information), followed by Gemini (global vision).
- technology development: Priority is given to Mita AI (document understanding, structured extraction), followed by Zhipu AutoGLM (technical depth).
- Daily information access/general research: Priority is given to Gemini (wide coverage), followed by Grok 3 (timeliness).
- In-depth Chinese Content Research: Prioritize Zhipu AutoGLM or Mita AI, which have superior understanding of native language and context.
Important Tip:
- cross-validation: For critical information or important decisions, comparative validation using at least two different tools is strongly recommended to ensure the accuracy and completeness of the information.
- Task Matching: There is no one-size-fits-all tool. Which product to choose depends greatly on the specific research task, the type of information needed (real-time vs. in-depth, technical vs. commercial), and the requirements for the format and depth of the report.
- Testing Limitations: This comparison is based on a single task only. Like Manus The advantages of a tool that emphasizes task flow and multi-format delivery capabilities like this may not be fully realized until other types of tasks are performed. In addition, user interface, cost, and API integration capabilities are also factors to be considered in the actual selection.
These AI research assistant tools undoubtedly represent future trends in the way information is accessed and analyzed. While each currently has its own strengths and weaknesses, they are evolving at a rapid pace and deserve continued attention. Choosing the right tools and learning to use them effectively will greatly enhance research and decision-making.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...