The word "agent" is depressing, GPT-4 models are no longer worthwhile, and the great programmers dish on "The Big Model 2024".

Experts generally agree that 2024 is the year of AGI. This is the year that the big modeling industry changes forever:
OpenAI's GPT-4 is no longer out of reach; work on image and video generation models is becoming more and more realistic; breakthroughs have been made in multimodal large language models, inference models, and intelligences (agents); and humans are caring more and more about AI ......
So, for a seasoned industry insider, how has the big model industry changed over the course of the year?
A few days ago, renowned independent programmer, co-founder of social conference directory Lanyrd, and co-creator of the Django web framework Simon Willison in the report entitled Things we learned about LLMs in 2024 The article reviews in detail the Changes, Surprises and Shortcomings in the Large Modeling Industry in 2024The

Some of the points are as follows:
- In 2023, training a GPT-4 level model is a big deal. However, in 2024, this is not even a particularly noteworthy achievement.
- Over the past year, we have made incredible training and inference performance gains.
- There are two factors driving down prices: increased competition and increased efficiency.
- Those who complain about the slow progress of LLM tend to ignore the great advances in multimodal modeling.
- prompt-driven app generation has become a commodity.
- Gone are the days of free access to SOTA models.
- Intelligentsia, still not really born.
- Writing good automated evaluations for LLM-driven systems is the skill most needed to build useful apps on top of these models.
- o1 Leading new approaches to extended modeling: solving harder problems by spending more computation on inference.
- The U.S. regulations on Chinese GPU exports seem to have inspired some very effective training optimizations.
- Over the past few years, the energy consumption and environmental impact of running prompt has been significantly reduced.
- Unsolicited and uncensored content generated by artificial intelligence is "slop".
- The key to getting the most out of LLM is to learn how to use unreliable but powerful technology.
- LLM has real value, but realizing that value is not intuitive and requires guidance.
Without altering the general thrust of the original text, the overall content has been condensed as follows:
A lot is happening in the field of Large Language Modeling (LLM) in 2024. Here's a recap of what we've discovered about the field over the past 12 months, along with my attempts to identify key themes and key moments. Including 19 Aspects:
1. The moat of GPT-4 was "breached".
I wrote in my December 2023 review, "We don't know how to build GPT-4 yet.--At the time, GPT-4 had been out for almost a year, but other AI labs hadn't made a better model yet.What does OpenAI know that the rest of us don't?
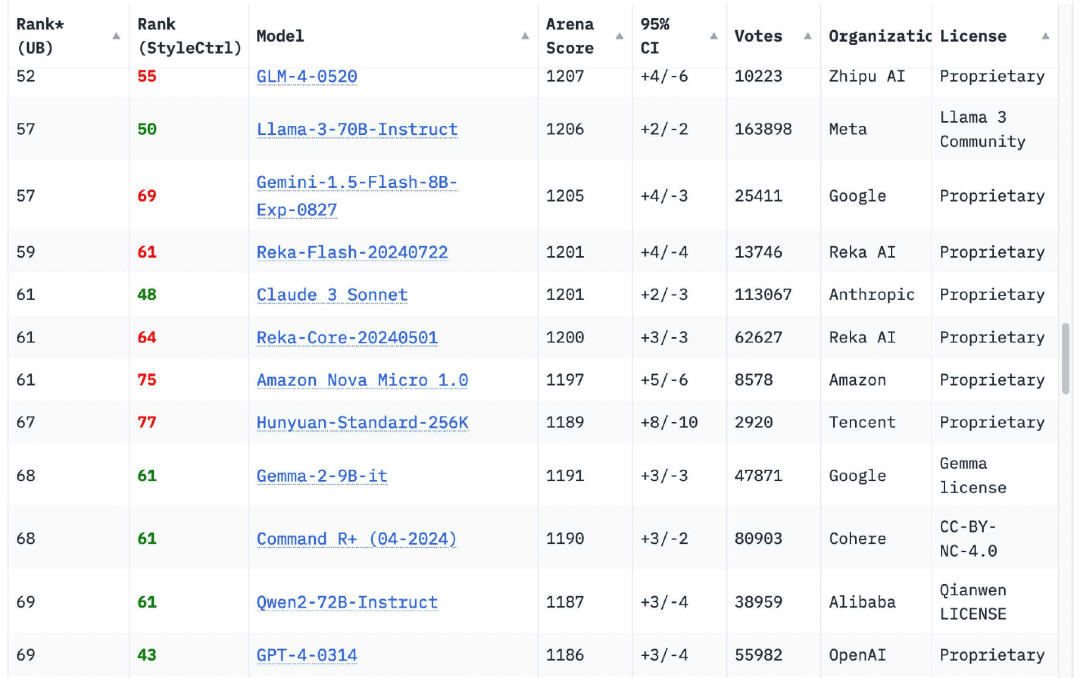
To my relief, this has completely changed in the last 12 months. The Chatbot Arena Leaderboard now hasModels from 18 organizationsRanked higher than the original version of GPT-4 (GPT-4-0314) released in March 2023, this number reaches 70
The earliest challenger was released by Google in February 2024 Gemini 1.5 Pro. In addition to offering GPT-4-level output, it brings several new features to the field, among themMost notable is the 1 million (later 2 million) token input context length, and the ability to input videoThe
Gemini 1.5 Pro triggers one of the key themes of 2024: increasing context length.In 2023, most models will only be able to accept 4096 or 8192 tokensLibyan Arab Jamahiriya Claude The exception is 2.1, which accepts 200,000 tokens. today, every model provider has a model that accepts 100,000+ tokens. token model, Google's Gemini series can accept up to 2 million tokens.
Longer inputs greatly increase the range of problems that can be solved using LLM: you can now type in an entire book and ask questions about its contents, but more importantly, you can type in a large amount of sample code to help the model solve the coding problem correctly. For me, LLM use cases involving long inputs are much more interesting than short prompts that rely purely on information about the model's weights. Many of my tools are built using this model.
Moving on to the models that 'beat' the GPT-4: Anthropic's Claude 3 line was launched in March, and the Claude 3 Opus quickly became my favorite model. in June, they followed up with the Claude 3.5 Sonnet - and six months later, it's still my favorite! Six months later, it's still my favorite.
Of course, there are others. If you browse the Chatbot Arena Leaderboard today, you'll see that theGPT-4-0314 has fallen to about 70th place... The 18 organizations with high model scores are Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, Zero One Thing, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Smart Spectrum, xAI, AI21 Labs, Princeton University and Tencent.
Training a GPT-4 level model in 2023 is a big deal. However, theIn 2024, that's not even a particularly noteworthy accomplishment, but I personally still celebrate every time a new organization is added to this list.
2. Laptop, ready to run GPT-4 level models
My personal laptop is a 2023 64GB M2 MacBook Pro. it's a powerful machine, but it's also nearly two years old - and more importantly, it's the same laptop I've been using since March 2023, when I first ran LLM on my own computer.
In March 2023, this laptop will still only be able to run one GPT-3 level modelThe GPT-4 model is now capable of running multiple GPT-4 level models!
This still surprises me. I thought it would take one or more datacenter-class servers with $40,000+ GPUs to achieve the functionality and output quality of the GPT-4.
These models take up 64GB of my memory, so I don't run them very often - they don't leave much room for anything else.
The fact that they work is a testament to the incredible training and inference performance gains we've made over the past year. As it turns out, we've reaped a lot of visible fruit in terms of model efficiency. I hope there will be more in the future.
Meta's Llama 3.2 series of models deserve special mention. They may not be GPT-4 rated, but at 1B and 3B sizes, they show results that exceed expectations.
3. LLM prices have fallen significantly due to competition and efficiency gains
Over the past twelve months, the cost of using LLM has dropped dramatically.
December 2023, OpenAI charges $30/million input token for GPT-4(mTok) costsIn addition, a fee of $10/mTok was charged for the then newly introduced GPT-4 Turbo and $1/mTok for the GPT-3.5 Turbo.
Today, OpenAI's most expensive o1 model can be purchased for $30/mTok!The GPT-4o costs $2.50 (12 times cheaper than the GPT-4), and the GPT-4o mini costs $0.15/mTok-nearly 7 times cheaper than the GPT-3.5 and more powerful.
Other model providers charge even less, with Anthropic's Claude 3 Haiku at $0.25/mTok. Google's Gemini 1.5 Flash at $0.075/mTok and Gemini 1.5 Flash 8B at $0.0375/mTok are 27 times cheaper than the GPT-3.5 Turbo in 2023. Turbo in 2023.
There are two factors driving down prices: increased competition and efficiency gains. Efficiency improvements are important to all who are concerned about the environmental impact of LLM. These price reductions are directly related to the energy consumed to run the prompt.
There is still much to worry about regarding the environmental impact of AI data center construction, but concerns about the energy costs of individual prompts are no longer credible.
Let's do an interesting calculation: how much would it cost to generate short descriptions for each of the 68,000 photos in my personal photo library using Google's cheapest Gemini 1.5 Flash 8B?
Each photo requires 260 input tokens and about 100 output tokens.
260 * 68000 = 17680000 Input token
17680000 * 0.0375 dollars/million = 0.66 dollars
100 * 68000 = 6800,000 Output token
6800000 * 0.15$/million = 1.02$.
Total cost to process 68,000 images is $1.68. It was so cheap that I even did the math three times to make sure I had it right.
How good are these descriptions? I got the information from this command:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
This is a photo of a butterfly from the California Academy of Sciences:

There is a red shallow dish in the picture that could be a hummingbird or butterfly feeder. The dish has a slice of orange fruit slices.
There are two butterflies in the feeder, one is a dark brown/black butterfly with white/cream markings. The other was a larger brown butterfly with light brown, beige and black markings, including prominent eye spots. This larger brown butterfly appears to be eating fruit from a plate.
260 input tokens, 92 output tokens, at a cost of about 0.0024 cents (less than 400th of a cent).
Increased efficiency and lower prices are my favorite trends for 2024.I want the utility of LLM at a very low energy cost, and that's what we're achieving.
4. Multimodal vision has become common, audio and video are starting to 'emerge'
The butterfly example I gave above also illustrates another key trend for 2024: the rise of the Multimodal Large Language Model (MLLM).
The GPT-4 Vision, released a year ago at OpenAI's DevDay in November 2023, is one of the most notable examples. Google, on the other hand, released multimodal Gemini 1.0 on December 7, 2023.
In 2024, almost all model providers have released multimodal models.We saw it in March. Anthropic s Claude 3 series, saw the Gemini 1.5 Pro (image, audio, and video) in April, and in September saw the Mistral 's Pixtral 12B, and Meta's Llama 3.2 11B and 90B visual models. We obtained audio inputs and outputs from OpenAI in October, SmolVLM from Hugging Face in November, and image and video models from Amazon Nova in December.
I think.Those who complain about the slow progress of LLMs tend to ignore the great advances in these multimodal models. The ability to run prompts against images (as well as audio and video) is a fascinating new way to apply these models.
5. Voice and real-time video modes to bring sci-fi into reality
Of particular note, audio and real-time video models are beginning to emerge.
together with ChatGPT The dialog feature debuts in September 2023, but this is largely an illusion: OpenAI uses its excellent Whisper Speech-to-text model and a new text-to-speech model (named tts-1) to enable conversations with ChatGPT, but the actual model can only see text.
OpenAI's May 13th release of GPT-4o includes a demonstration of a new speech model, the truly multimodal GPT-4o ("o" stands for "omni") model that takes audio input and outputs incredibly realistic speech without the need for a separate TTS or STT model.
When ChatGPT Advanced Voice Mode was finally introduced, the results were amazing.I often use this mode when walking my dog and the tone has improved so much it's amazing!. I've also had a lot of fun using the OpenAI Audio API.
OpenAI isn't the only team with multimodal audio models. Google's Gemini also accepts audio input and can also speak in a ChatGPT-like manner. Amazon also announced a voice model for Amazon Nova ahead of schedule, but that model will be available in the first quarter of 2025.
Google NotebookLM Released in September, it took audio output to a new level, with two "podcast hosts" who could have realistic conversations about anything you typed, and later added custom commands.
The most recent new change, also from December, is real-time video.ChatGPT Voice Mode now offers the option to share camera footage with models and talk about what you're seeing in real time. Google's Gemini has also launched a preview version with the same features.
6. prompt-driven app generation, which has become a commodity
GPT-4 can already accomplish this in 2023, but its value is not apparent until 2024.
LLM is known to have an amazing talent for writing code. If you can write a prompt correctly, they can build you a complete interactive app using HTML, CSS, and JavaScript-often in a single prompt.
Anthropic took this idea to the next level with the release of Claude ArtifactsArtifacts is a groundbreaking new feature. With Artifacts, Claude can write an on-demand interactive app for you and then let you use it directly in the Claude interface.
This is an app for extracting URLs, generated entirely by Claude:
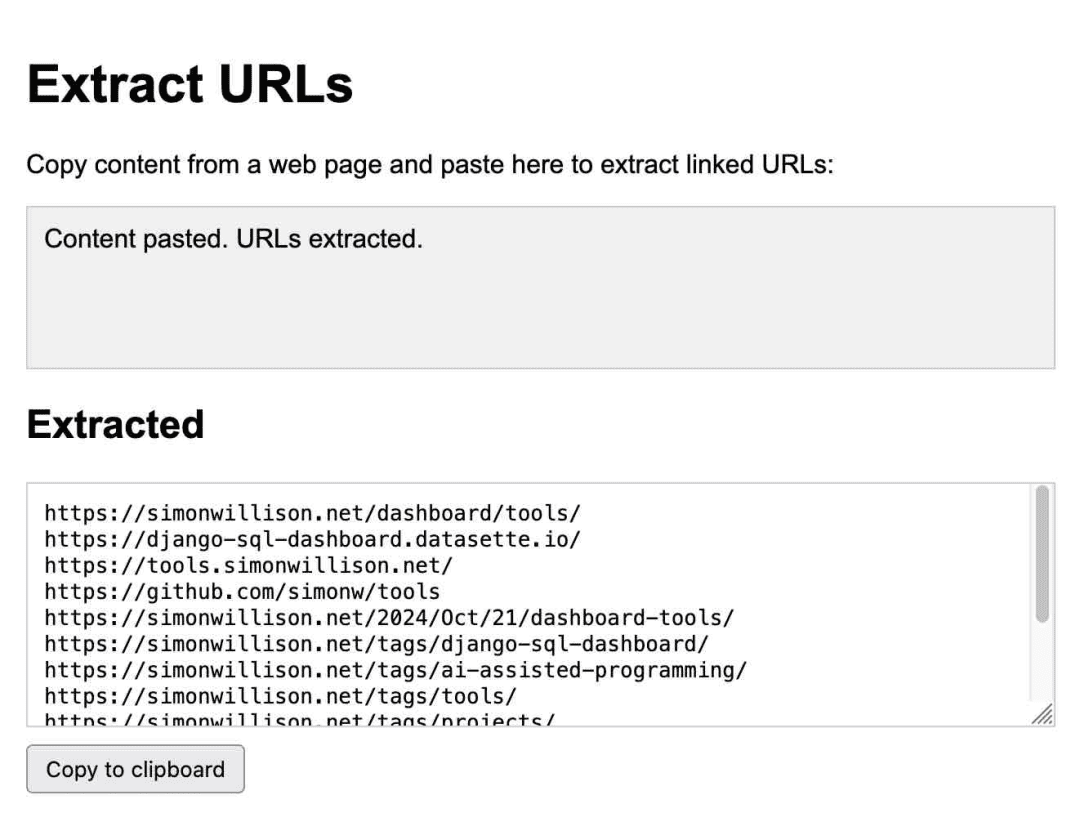
I use it on a regular basis. I noticed in October how much I relied on it, theI created 14 gadgets in seven days using ArtifactsThe

Since then, a whole bunch of other teams have built similar systems, and in October, GitHub released their version, GitHub Spark. in November, Mistral Chat added it as a feature called Canvas.
Steve Krause from Val Town responded to Cerebras A version was built to show how LLM with 2000 tokens per second can iterate the app and see changes in less than a second.
Then in December, the Chatbot Arena team launched a brand new leaderboard for this feature, where users build the same interactive app twice using two different models and vote on the answers. It would be hard to make a more convincing argument that this feature is now a commodity that can effectively compete with all the leading models.
I've been mulling over this release for my Datasette project, with the goal of letting users use prompt to build and iterate on custom gadgets and visualize data based on their own data. I've also found a similar pattern for writing one-off Python programs via uv.
This kind of prompt-driven custom interface is so powerful and easy to build (once you figure out the intricate details of browser sandboxing) that I expect it to be in a variety of products as a feature by 2025.
7. In just a few months, powerful models were popularized
In just a few short months in 2024, powerful models will be available for free in most countries around the world.
OpenAI made GPT-4o free to all users in May, and Claude 3.5 Sonnet was made free with the June release. This is a significant change, as for the past year free users have mostly only been able to use models at the GPT-3.5 level, which in the past would have led to a lack of clarity for new users about the actual capabilities of the LLM.
With the launch of ChatGPT Pro by OpenAI, the era seems to be over, most likely permanently!This $200/month subscription is the only way to access its most powerful model, the o1 Pro. This $200/month subscription service is the only way to access its most powerful model, the o1 Pro.
The key behind the o1 series (and the future models that will no doubt inspire it) is to spend more computational time to get better results. As such, I think the days of free access to SOTA models are gone.
8. Intelligent bodies, still not really born
I personally believe thatThe word "agent" is very frustrating.. It lacks a single, clear and widely understood meaning ...... But those who use the term never seem to recognize this.
If you tell me that you are building an "agent", then you have conveyed almost nothing to me. Without reading your mind, I have no way of knowing which of the dozens of possible definitions you are talking about.
There are two main types of people I seeOne group thinks of an agent as obviously something that acts on your behalf - a traveling agent - and the other group thinks of an agent as an LLM that has access to tools that can be run in a loop as part of the solution to a problem. The term "autonomy" also gets thrown around a lot, but again without a clear definition. (A few months ago, I tweeted a collection of 211 definitions of agent, and had gemini-exp-1206 try to summarize them).
Whatever the term means.Agent, there's still a sense of perpetual "coming soon.". Terminology aside.I'm still skeptical about their usefulnessThis is a challenge based on gullibility: LLMs will believe anything you tell them. Any system that tries to make meaningful decisions on your behalf runs into the same obstacle: how useful is a travel agent, or a digital assistant, or even a research tool if it can't tell the difference between what's true and what's false?
Just a few days ago, a Google search was found to provide a completely false description of the nonexistent movie Encanto 2.
Timely injection is a natural consequence of this gullibility. I see very little progress being made in 2024 to address this issue, which we have been discussing since September 2022
Prompt injection attacks are a natural result of this "gullibility". I see little progress in the industry in 2024 to address this issue, which we have been discussing since September 2022.
I'm beginning to think that the most popular agent concept will rely on AGI.Making the model resistant to "gullibility" is a tall order indeed!The
9. Evaluation, very important
Anthropic's Amanda Askell (for Claude's). Character most of the work behind it) had said:
There's a boring but vital secret behind a good system prompt, and that's test-driven development. You don't write a system prompt and then figure out how to test it. You write tests, and then you find a system prompt that passes those tests.
In the course of 2024, it has become abundantly clear that theWrite excellent automated evaluations for LLM-driven systems, is the skill most needed to build useful apps on top of these models. If you have a strong evaluation suite, you can adopt new models faster than your competitors, iterate better, and build more reliable and useful product features.
According to Malte Ubl, Vercel's CTO:
When v0 (a web development agent) was first introduced, we were paranoid about protecting prompt with all sorts of complex pre-processing and post-processing.
We've completely shifted to letting it run free. No evaluation, modeling, or especially UX prompts is like a broken ASML machine without an instruction manual.
I'm still trying to find a better model for my own work. Everyone knows that evaluations are important, but forThere is still a lack of good guidance on how best to achieve assessmentThe
10. Apple Intelligence sucks, but MLX is great!
As a Mac user, I feel much better about my platform of choice now.
In 2023, I feel like I don't have a Linux/Windows machine with an NVIDIA GPU, which is a huge disadvantage for me to try out new models.
In theory, a 64GB Mac should be a good machine to run models on because the CPU and GPU can share the same amount of memory. In practice, many of the models are published as model weights and libraries, with NVIDIA's CUDA favored over other platforms.
llama.cpp The ecosystem helped a lot with this, but the real breakthrough was Apple's MLX library, which is fantastic.
Apple's mlx-lm Python support runs a variety of mlx-compatible models on my Mac with excellent performance. the mlx community on Hugging Face provides over 1000 models that have been converted to the necessary formats. prince Canuma's mlx-vlm project is excellent and moving quickly, and also brings visual LLMs to Apple Prince Canuma's mlx-vlm project is excellent and progressing quickly, and has also brought visual LLM to Apple Silicon.
While MLX was a game changer, Apple's own Apple Intelligence features were mostly disappointing. I wrote an article about their initial release back in June, and at the time I was optimistic that Apple had focused on protecting user privacy and minimizing users being misled about LLM apps.
Now that these features are available, they are still relatively ineffective. As a heavy user of LLM, I know what these models are capable of, and Apple's LLM features are just a pale imitation of cutting-edge LLM features. Instead, we get notification summaries that skew news headlines, and I don't even think the Writing Assistant tool is useful at all. Still, Genmoji is pretty fun.
11. Inference-scaling, the rise of "reasoning" models
The most interesting development in the last quarter of 2024 is the emergence of a new LLM morphology, exemplified by OpenAI's o1 models - o1-preview and o1-mini were released on September 12th. One way to think about these models is as an extension of the chain of thought prompt technique.
The trick is mainly thatIf you get a model to think hard (talk out loud) about the problem it's solving, you'll usually get a result that the model wouldn't otherwise getThe
o1 embeds this process further within the model. The details are a bit fuzzy: the o1 model spends "reasoning tokens" to think about the problem, which the user can't see directly (although the ChatGPT UI will show a summary), and then outputs the final result.
The biggest innovation here is that it opens up a new way of extending the model: the model can now solve harder problems by spending more computational effort on inference, theInstead of improving model performance purely by increasing the amount of computation at training timeThe
o1's successor, o3, was released on December 20 and achieved impressive results in the ARC-AGI benchmarks, despite the fact that there may have been more than $1 million in computational time costs involved!
o3 is expected to be released in January. I doubt there are many people with real problems that would benefit from this level of compute spending, I certainly don't! But it seems to be a real next step for the LLM architecture to solve harder problems.
OpenAI isn't the only player here. on December 19th, Google released their first entrant in this space, gemini-2.0-flash-thinking-exp.
Alibaba's Qwen team released the QwQ model on November 28th under the Apache 2.0 license. Then, on December 24, they released a visual inference model called QvQ.
DeepSeek The DeepSeek-R1-Lite-Preview model was made available for trial on November 20 via the chat interface.
Editor's note: Wisdom Spectrum was also released on the last day of 2024Deep Reasoning Model GLM-ZeroThe
Anthropic and Meta haven't made any progress yet, but I'd be very surprised if they don't have their own inference extension model.
12. Is the best LLM, by far, trained in China??
Not exactly, but almost! It does make a great headline that catches the eye.
DeepSeek v3 is a massive 685B parametric model - one of the largest publicly licensed models available, and much larger than the largest in Meta's Llama family, Llama 3.1 405B.
Benchmarks show it to be on par with Claude 3.5 Sonnet, and the Vibe benchmarks currently rank it at #7, behind the Gemini 2.0 and OpenAI 4o/o1 models. This is the highest ranked publicly licensed model to date.
What's really impressive is thatDeepSeek v3Training costsThe model was trained on 2788000 H800 GPU hours at an estimated cost of $5576000. The model was trained in 2788000 H800 GPU hours at an estimated cost of $5576000.Llama 3.1 405B trained in 30840000 GPU hours, 11 times as many as DeepSeek v3, but the model's baseline performance was somewhat worse.
The U.S. regulations on Chinese GPU exports seem to have inspired some very effective training optimizations.
13. Environmental impacts of operating prompts are improved.
Whether it's a hosted model or one that I run locally, one of the welcome results of the increased efficiency is that the energy consumption and environmental impact of running prompt has been greatly reduced over the past few years.
OpenAI's own prompt charges are 100 times lower than GPT-3's at the time.I have it on good authority that neither Google Gemini nor Amazon Nova (the two cheapest model providers) are running prompt at a loss.
This means that, as individual users, we don't have to feel guilty at all about the energy consumed by the vast majority of prompts. Compared to driving down the street, or even watching a video on YouTube, the impact may be negligible.
The same goes for training. deepSeek v3 costs less than $6 million to train, which is a very good sign that training costs can and should continue to fall.
14. New data centers, are they still necessary?
And the bigger problem is that there will be significant competitive pressure to build the infrastructure these models will need in the future.
Companies like Google, Meta, Microsoft and Amazon are spending billions of dollars on new data centers, which is having a huge impact on the grid and the environment. There's even talk of building new nuclear power plants, but that will take decades.
Is this infrastructure necessary?The $6 million in training costs for DeepSeek v3 and the continued reduction in LLM prices may be enough to make that case. But would you like to be the big tech executive who argued against this infrastructure, only to be proven wrong a few years later?
An interesting contrast is the development of railroads around the world in the 19th century. The construction of these railroads required huge investments, had a huge impact on the environment, and many of the lines built proved to be unnecessary.
The resulting bubbles led to several financial collapses, and they left us with a lot of useful infrastructure and a lot of bankruptcies and environmental damage.
15.2024, the year of "slop"
2024 is the year the word "slop" becomes a term of art. @deepfates wrote on twitter:
Just as "spam" became the proper noun for unwanted email, "slop" will appear in the dictionary as the proper noun for unwanted content generated by AI.
I wrote a post in May that expanded on this definition a bit:
"Slop" refers to unsolicited and uncensored content generated by artificial intelligence.
I like the word "slop" because it succinctly summarizes one way we shouldn't use generative AI!
16. Synthesize training data, very effective
Surprisingly, the notion of "pattern collapse"-that is, that AI models break down when trained on recursively generated data-seems to be deeply ingrained in the public consciousness. .
The idea is seductive: as AI-generated "slop" floods the Internet, the models themselves will degrade, feeding on their own output and leading to their inevitable demise!
Obviously, this did not happen. Instead, we're seeing AI labs increasingly train on synthetic content - by creating artificial data that helps steer their models in the right direction.
One of the best descriptions I've seen comes from the Phi-4 technical report, which includes the following:
Synthetic data is becoming more common as an important part of pre-training, and the Phi family of models has been emphasizing the importance of synthetic data. Rather than being a cheap alternative to real data, synthetic data has several direct advantages over real data.
Structured Progressive Learning. In real datasets, the relationships between tokens are often complex and indirect. Many inference steps may be required to associate the current token with the next token, making it difficult for the model to effectively learn from the next token prediction. In contrast, each token generated by a language model is predicted by the previous token, making it easier for the model to follow the resulting inference pattern.
Another common technique is to use larger models to help create training data for smaller, less expensive models, and more and more labs are using this technique.
DeepSeek v3 uses DeepSeek-R1 Created "inference" data.Meta's Llama 3.3 70B fine-tuning uses over 25 million synthetically generated examples.
Careful design of the training data used for LLM seems to be the key to creating these models. Long gone are the days of grabbing all the data from the web and feeding it indiscriminately into training runs.
17. Use LLM properly, it's not easy!
I've always emphasized that LLMs are powerful user tools - they're chainsaws disguised as choppers. They look easy to use - how hard can it be to enter information into a chatbot? But in reality.To make the most of them and avoid their many pitfalls, you need to have a deep understanding and extensive experience with themThe
This problem becomes even worse in 2024.
We've built computer systems that can be talked to in human language that can answer your questions, and usually get them right! ...... Depends on what the question is, how it is asked, and whether it can be accurately reflected in an unrecorded secret training set.
Today, the number of available systems is proliferating. Different systems have different tools that can be used to solve your problem, such as Python, JavaScript, web search, image generation, and even database queries ...... So you better understand what these tools are, what they can do, and how to tell if LLM is using them.
Did you know that ChatGPT now has two completely different ways of running Python?
If you want to build a Claude Artifact that talks to an external API, it's a good idea to learn about CSP and CORS HTTP headers.
The capabilities of these models may have improved, but most of the limitations remain. OpenAI's o1 may finally be able to (mostly) compute the "r" in strawberry, but its capabilities are still limited by its nature as an LLM, and by its runtime harnesses. o1 can't do web searches or use a code interpreter, but GPT-4o can - both are in the same ChatGPT UI. GPT-4o can - both are in the same ChatGPT UI.
What have we done about it? Nothing. Most users are "newbies". The default LLM chat UI is like throwing brand new computer users into a Linux terminal and expecting them to take care of everything themselves.
At the same time, it's becoming increasingly common for end users to develop inaccurate mental models of how these devices work and function. I've seen plenty of examples of this, where people have tried to win arguments with screenshots of ChatGPT - an inherently ludicrous proposition, given the inherent unreliability of these models, coupled with the fact that you can get them to say just about anything if you give them the right prompt.
There is a flip side: many "old hands" have given up on LLM altogether because they don't see how anyone can benefit from a tool with so many flaws. The key to getting the most out of LLM is to learn how to use this unreliable but powerful technology. This is clearly not an obvious skill!
While there is so much useful educational content out there, we need to do a better job than outsourcing it all to AI shills who tweet furiously.
18. Poor cognition, still present
Now.Most people have heard of ChatGPT, but how many have heard of Claude?
Between those who are actively concerned about these issues and 99% those who are not, there is aThe great knowledge gapThe
Last month we saw the popularity of real-time interfaces where you can point your phone camera at something and talk about it in a voice ...... There's also the option to make it pretend to be Santa Claus. Most self-certified people (sic "nerd") haven't tried it yet.
Considering the continuing (and potential) impact of this technology on society, I think the currentThis divide is unhealthy. I would like to see more efforts to improve the situation.
19.LLM, better criticism needed
A lot of people really hate stuff about LLM. On some of the sites I frequent, even the suggestion that "LLM is very useful" is enough to start a war.
I understand. There are a lot of reasons why people don't like this technology - environmental impact, lack of reliability of training data, un-positive applications, potential impact on people's jobs.
LLM definitely deserves criticism.We need to discuss these issues, find ways to mitigate them, and help people learn how to use these tools responsibly so that their positive applications outweigh their negative impacts.
I love people who are skeptical about this technology. For more than two years now, the hype has grown and a lot of misinformation has flooded the airwaves. A lot of bad decisions have been made based on this hype.Daring to criticize is a virtue.
If we want people with decision-making power to make good decisions about how to apply these tools, we first need to recognize that there are indeed good applications, and then help explain how to put them into practice while avoiding many of the non-practical pitfalls.
I think.Telling people that the entire field is an environmentally disastrous plagiarism machine that continually makes stuff up, no matter how much truth that represents, is a disservice to these people.. There is real value here, but realizing that value is not intuitive and requires guidance.
Those of us who understand this stuff have a responsibility to help others figure it out.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...