NVIDIA veröffentlicht Vincennes Graphenmodell SANA: 4K-Images im Handumdrehen für lokale Implementierungen
Vor kurzem hat NVIDIA (NVIDIA) in Zusammenarbeit mit dem Massachusetts Institute of Technology und der Tsinghua University ein Open-Source-Bildgenerierungsmodell namens SANA auf den Markt gebracht, das nicht nur in der Lage ist, Bilder mit einer Auflösung von bis zu 4096 × 4096 effizient zu generieren, sondern auch eine sehr hohe Generierungsgeschwindigkeit aufweist.
Die Leistung von SANA
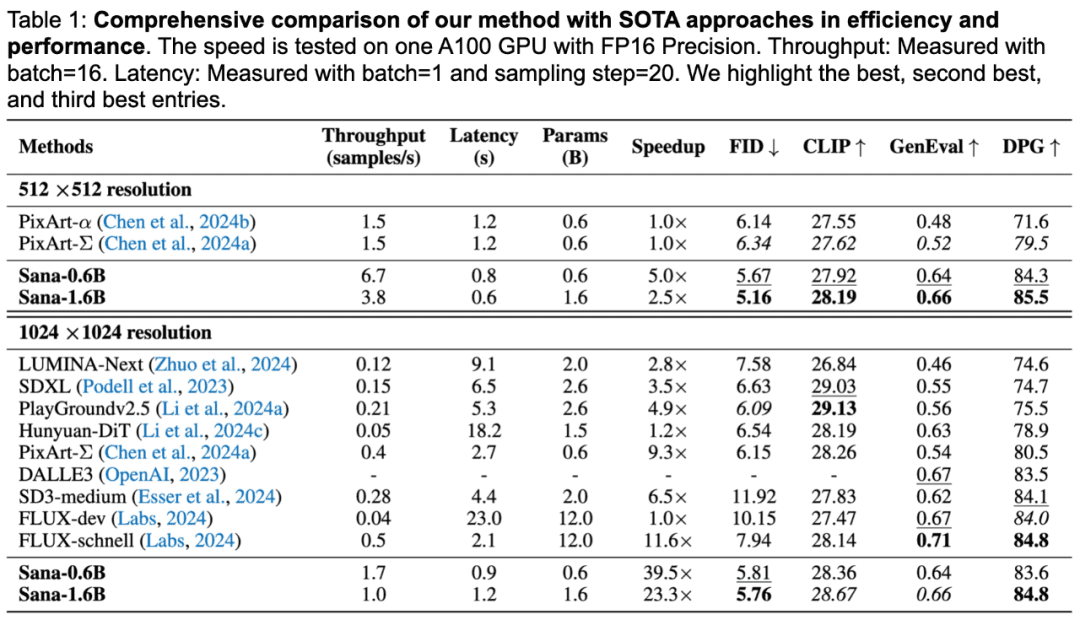
SANA wird durch das Wort "schnell" charakterisiert: SANA-0.6B benötigt weniger als eine Sekunde, um Bilder mit einer Auflösung von 1024×1024 zu erzeugen, also 25-mal schneller als Flux-Dev, während die Erzeugung von Bildern mit einer Auflösung von 4096×4096 106-mal schneller als Flux-Dev ist.

In Bezug auf die Generierungsqualität liegt SANA im DPG-Bench-Testbenchmark gleichauf mit Flux und in der GenEval-Metrik nur knapp unter dem Flux-Modell.
SANAs Kerndesign
Der Erfolg von SANA beruht auf seinen vier Kernkonzepten:
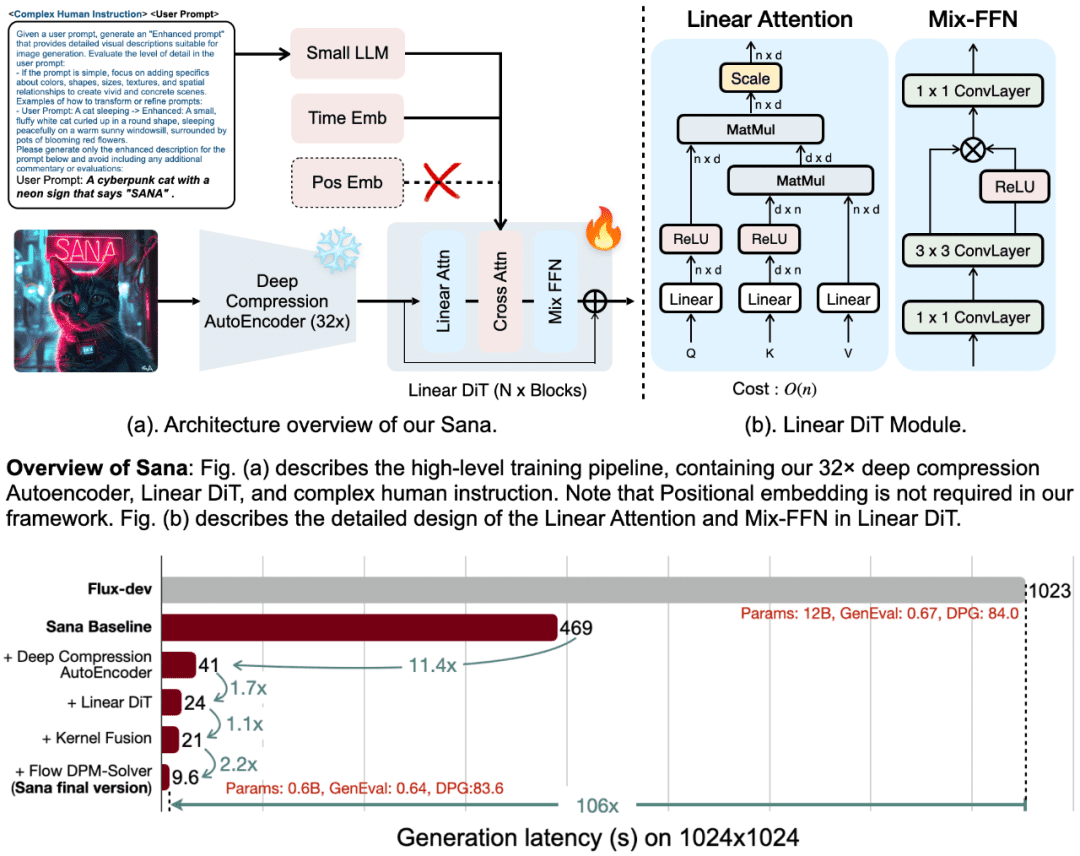
1. der Tiefenkompressions-Autoencoder (DC-AE)
Während herkömmliche Autoencoder (AEs) Bilder in der Regel um den Faktor 8 komprimieren, führt SANA einen Autoencoder mit tiefer Kompression ein, der den Kompressionsfaktor auf 32 erhöht. Dieses Design reduziert die Anzahl potenzieller Marker drastisch und ermöglicht es SANA, effizient ultrahochauflösende Bilder (z. B. 4K-Auflösung) zu generieren und gleichzeitig die Rechenkosten für Training und Generierung deutlich zu senken.
2. lineare DIT (Diffusion Image Transformer)
SANA verwendet einen neuen linearen Aufmerksamkeitsmechanismus anstelle des traditionellen quadratischen Aufmerksamkeitsmechanismus, wodurch die Komplexität von O(N²) auf O(N) reduziert wird. Diese Verbesserung erhöht nicht nur die Effizienz der hochauflösenden Bilderzeugung, sondern macht auch eine Positionskodierung überflüssig und ist damit das erste DIT-Modell, das keine Positionseinbettung benötigt.
3. kleine LLMs, die nur Decoder sind, als Text-Encoder
SANA verwendet kleine Decoder-Sprachmodelle wie Gemma 2 als Text-Encoder, die die traditionellen CLIP- oder T5-Modelle ersetzen. Gemma verfügt über hervorragende Fähigkeiten zum Textverständnis und zur Einhaltung von Anweisungen, was in Verbindung mit einem ausgeklügelten manuellen Anweisungsdesign die Bild-Text-Anpassung erheblich verbessert.
4. effiziente Ausbildungs- und Argumentationsstrategien
SANA schlägt eine automatische Etikettierungs- und Trainingsstrategie vor, die verschiedene Untertitel mit mehreren visuellen Sprachmodellen (VLMs) generiert und qualitativ hochwertige Untertitel auf der Grundlage von CLIPScore auswählt, wodurch die Konvergenz der Modelle beschleunigt und die Ausrichtung von Text und Bild verbessert wird. Darüber hinaus führt SANA den Flow-DPM-Solver ein, der die Inferenzschritte drastisch reduziert und die Effizienz der Generierung weiter verbessert.
Kostengünstige Bereitstellung und Open Source
Ein weiteres Highlight von SANA ist seine kostengünstige Einsetzbarkeit. SANA-0.6B kann auf einem 16-GB-Laptop-Grafikprozessor laufen und Bilder mit einer Auflösung von 1024×1024 in weniger als einer Sekunde erzeugen, und 22 GB Videospeicher können Bilder mit einer Auflösung von 4096×4096 begradigen, eine Eigenschaft, die SANA nicht nur für High-End-Computergeräte geeignet macht, sondern auch auf den Laptops normaler Nutzer effizient laufen lässt Laptops. Darüber hinaus kündigte NVIDIA an, den Code und das Modell von SANA zu veröffentlichen, um die Popularität und Anwendung der Text-zu-Bild-Erzeugungstechnologie weiter zu fördern.
ausnutzen
NVIDIA hat acht 3090 Webschnittstellen erstellt, die kostenlos ausprobiert werden können. Es ist erwähnenswert, dass das SANA-Modell direkt mit chinesischen Eingabewörtern verwendet werden kann.
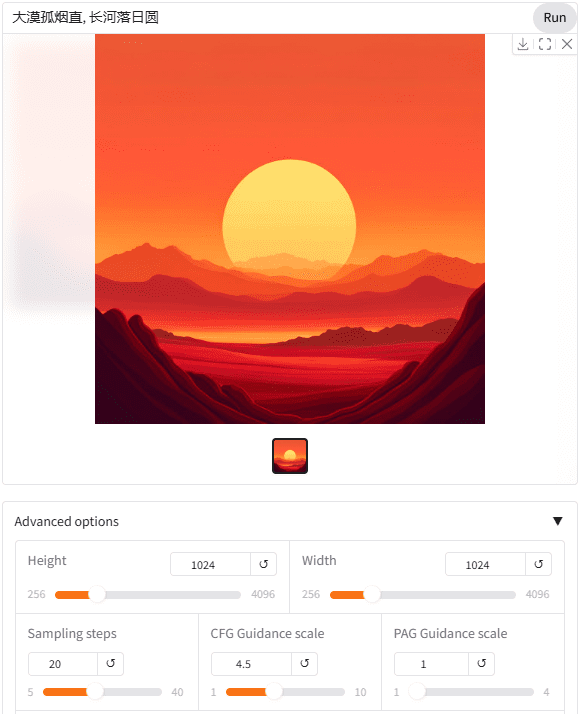
Sogar die Verwendung von Stichwörtern mit Iconsymbolen ist möglich, was von der Verwendung des visuellen Sprachmodells Gemma2 2B als Textkodierer profitieren sollte.

Mit dem ComfyUI_ExtraModels Plugin ist es sehr einfach, SANA-Modelle auch auf nativem Comfyui zu verwenden. Plugin-Installation ist sehr einfach, müssen nicht ihre eigenen Abhängigkeiten zu konfigurieren, laufen nach der Installation automatisch die erforderlichen Modell-Dateien herunterladen.
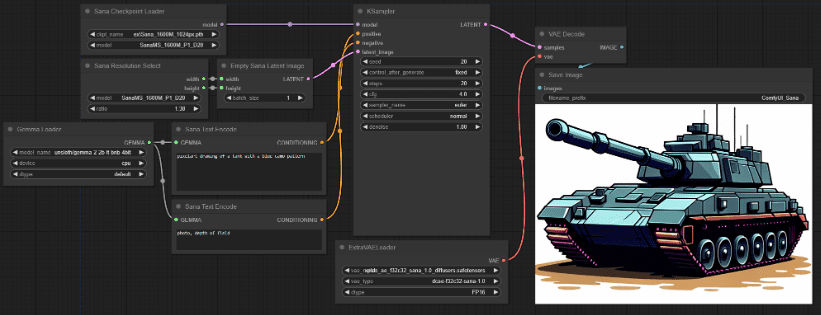
Mit dem Deep Compression Autoencoder, dem linearen DIT, dem kleinen LLM nur für den Decoder und den effizienten Trainings- und Inferenzstrategien ist SANA nicht nur in der Lage, ultrahochauflösende Bilder effizient zu erzeugen, sondern verfügt auch über starke Text-Bild-Abgleichsfunktionen und kostengünstige Einsatzvorteile. Für diejenigen, die schnell Bilder produzieren müssen, ist SANA immer noch gut, das heißt, in Bezug auf die Ökologie kann nicht mit Flux verglichen werden.

Projektseite:
github.com/NVlabs/Sana
Web-Nutzung:
nv-sana.mit.edu
Comfyui-Plugin:
github.com/Efficient-Large-Model/ComfyUI_ExtraModels
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...