VideoChat: sprachinteraktive digitale Person in Echtzeit mit benutzerdefinierten Bild- und Tonklonen, die End-to-End-Sprachlösungen und kaskadierende Lösungen unterstützen
Allgemeine Einführung
VideoChat ist ein digitales Echtzeit-Sprachinteraktionsprojekt, das auf Open-Source-Technologie basiert und End-to-End-Sprachschemata (GLM-4-Voice - THG) und Kaskadenschemata (ASR-LLM-TTS-THG) unterstützt. Das Projekt ermöglicht es den Benutzern, das Bild und die Klangfarbe des digitalen Menschen anzupassen, und unterstützt das Klonen von Klangfarben und Lippensynchronisation, Video-Streaming-Ausgabe und eine Latenzzeit für das erste Paket von nur 3 Sekunden. Die Benutzer können die Funktionalität durch Online-Demos erleben oder sie mit Hilfe der ausführlichen technischen Dokumentation lokal einsetzen und verwenden.
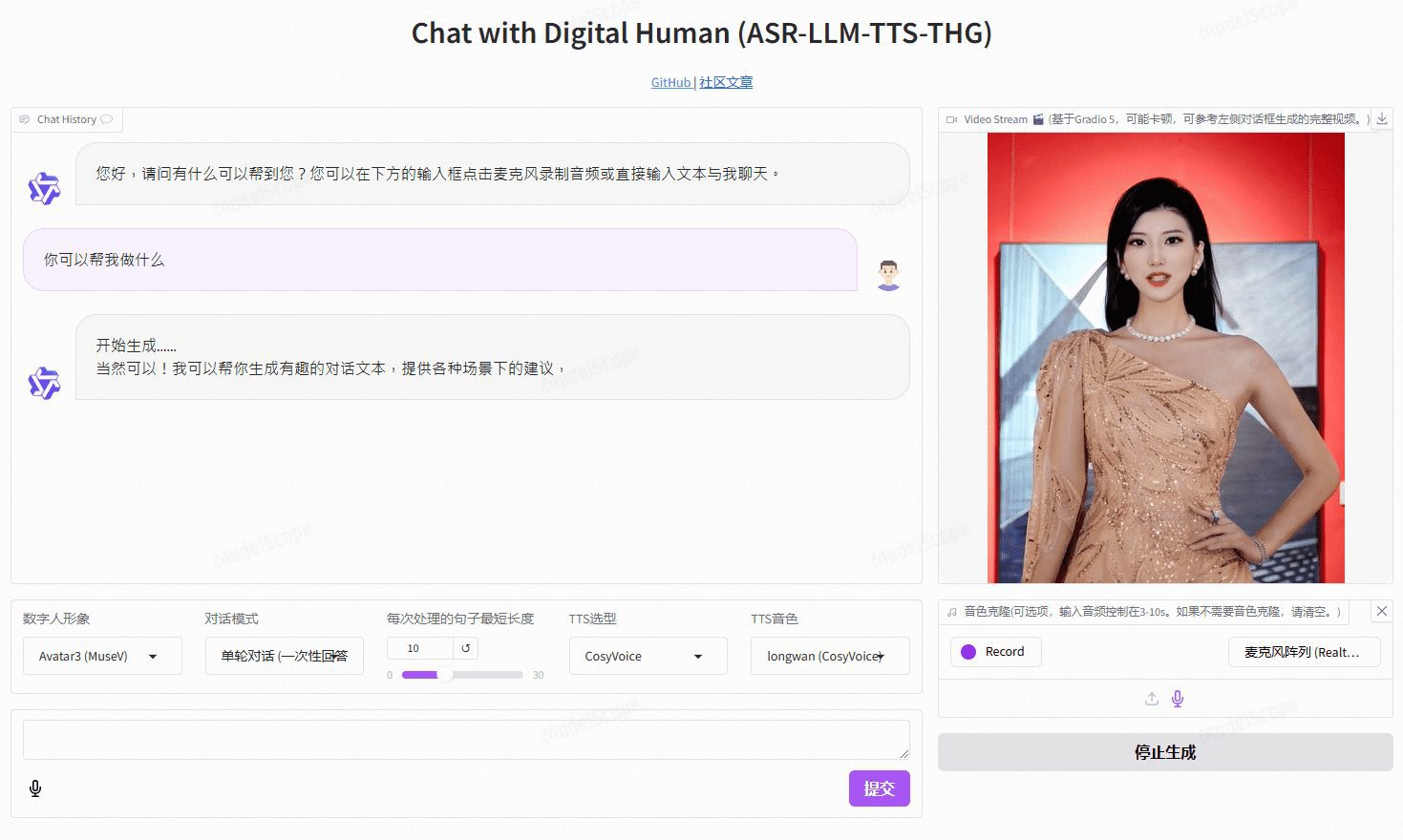
Demo-Adresse: https://www.modelscope.cn/studios/AI-ModelScope/video_chat
Funktionsliste
- Sprachinteraktion in Echtzeit: Unterstützung für End-to-End-Sprachlösungen und kaskadierende Lösungen
- Individuelles Bild und Ton: Die Benutzer können das Aussehen und den Ton der digitalen Person ihren Bedürfnissen entsprechend anpassen
- Klonen der Stimme: unterstützt das Klonen der Stimme des Benutzers, um ein personalisiertes Spracherlebnis zu ermöglichen
- Niedrige Latenzzeit: Die Latenzzeit für das erste Paket beträgt nur 3 Sekunden, um eine reibungslose Interaktion zu gewährleisten.
- Open-Source-Projekt: Basierend auf Open-Source-Technologie können Benutzer die Funktion frei ändern und erweitern
Hilfe verwenden
Einbauverfahren
- Umgebung Konfiguration
- Betriebssystem: Ubuntu 22.04
- Python-Version: 3.10
- CUDA Version: 12.2
- Fackel Version: 2.1.2
- Klonprojekt
git lfs install git clone https://github.com/Henry-23/VideoChat.git cd video_chat - Erstellen einer virtuellen Umgebung und Installieren von Abhängigkeiten
conda create -n metahuman python=3.10 conda activate metahuman pip install -r requirements.txt pip install --upgrade gradio - Download der Datei mit den Gewichten
- Es wird empfohlen, CreateSpace zum Herunterladen zu verwenden, ich habe git lfs eingerichtet, um die Gewichtsdateien zu verfolgen
git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git - Neue Dienste
python app.py
Verwendungsprozess
- Konfigurieren des API-KEY::
- Wenn die Leistung des lokalen Rechners begrenzt ist, können Sie die Qwen-API und die CosyVoice-API verwenden, die von Aliyuns großer Modell-Serviceplattform Hundred Refine auf dem
app.pyKonfigurieren Sie den API-KEY in der
- Wenn die Leistung des lokalen Rechners begrenzt ist, können Sie die Qwen-API und die CosyVoice-API verwenden, die von Aliyuns großer Modell-Serviceplattform Hundred Refine auf dem
- lokale Inferenz::
- Wenn Sie den API-KEY nicht verwenden, können Sie ihn in der
src/llm.pyim Gesang antwortensrc/tts.pyKonfigurieren Sie die lokale Inferenzmethode in, um nicht benötigten API-Aufrufcode zu entfernen.
- Wenn Sie den API-KEY nicht verwenden, können Sie ihn in der
- Neue Dienste::
- in Bewegung sein
python app.pyStarten Sie den Dienst.
- in Bewegung sein
- Anpassung der digitalen Persona::
- existieren
/data/video/Katalog, um eine Videoaufnahme des digitalen Menschenbildes hinzuzufügen. - Änderungen
/src/thg.pyin der avatar_list der Klasse Muse_Talk, wobei der Bildname und bbox_shift hinzugefügt werden. - existieren
app.pyNachdem Sie den Namen der digitalen Persona zum avatar_name in Gradio hinzugefügt haben, starten Sie den Dienst neu und warten Sie, bis die Initialisierung abgeschlossen ist.
- existieren
Detaillierte Vorgehensweise
- Individuelles Bild und Ton: in
/data/video/Verzeichnis, um ein aufgezeichnetes Video des digitalen Menschenbildes in diesrc/thg.pyÄnderungMuse_TalkKlasseavatar_listfügen Sie den Bildnamen undbbox_shiftParameter. - Sprachklonen: in
app.pyMittlere KonfigurationCosyVoice APIoder mitEdge_TTSLokale Argumentation durchführen. - End-to-End-Sprachlösungen: Verwendung
GLM-4-VoiceModelle für eine effiziente Spracherzeugung und -erkennung.
- Rufen Sie die Adresse des lokal eingerichteten Dienstes auf und gehen Sie zur Gradio-Schnittstelle.
- Wählen Sie ein benutzerdefiniertes digitales Persona-Video aus oder laden Sie es hoch.
- Konfigurieren Sie die Funktion zum Klonen von Stimmen, um die Stimmenprobe eines Benutzers hochzuladen.
- Starten Sie Sprachinteraktionen in Echtzeit und erleben Sie Dialogfunktionen mit geringer Latenz.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...