UIGEN-T1-Qwen-7b: Spezialisierte Modelle für die Generierung von HTML- und CSS-UI-Komponenten
Allgemeine Einführung
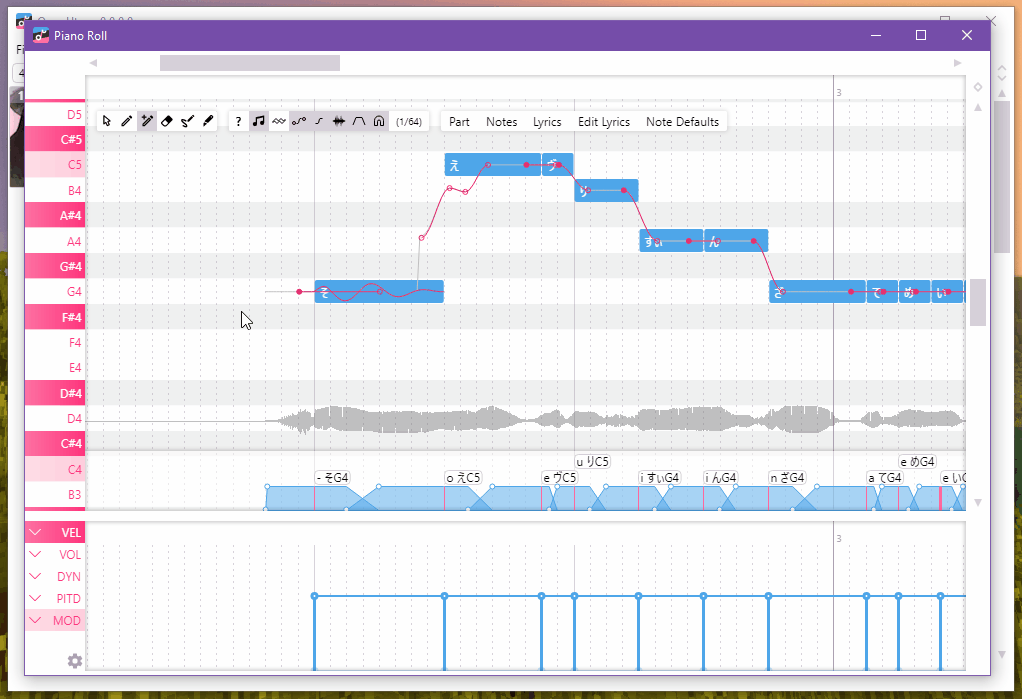
UIGEN-T1 ist ein 7-Milliarden-Parameter Transformator Modell, das auf der Grundlage von Qwen2.5-Coder-7B-Instruct feinabgestimmt und für die schlussfolgernde UI-Generierung entwickelt wurde. Es verwendet einen ausgeklügelten Chain-of-Thought-Ansatz, um leistungsstarke HTML- und CSS-basierte UI-Komponenten zu generieren. Derzeit ist es auf einfache Anwendungen wie Dashboards, Landing Pages und Registrierungsformulare beschränkt. Das Modell generiert HTML- und CSS-Layouts, indem es Designprinzipien zu Grunde legt. Es verfügt zwar über einen leistungsstarken Chain-Thinking-Prozess, ist aber derzeit auf textbasierte UI-Elemente und einfachere Front-End-Anwendungen beschränkt. Das Modell eignet sich hervorragend für Dashboards, Landingpages und Registrierungsformulare, bietet jedoch keine fortgeschrittene Interaktivität (z. B. Funktionen, bei denen viel JavaScript zum Einsatz kommt).


Funktionsliste
- UI-GenerationFähigkeit, HTML- und CSS-Code für die Erstellung von Benutzeroberflächen zu erzeugen.
- KettendenkenGenerieren von UI-Layouts durch Überlegungen zu Designprinzipien unter Verwendung eines Chain-Thinking-Ansatzes.
- Anwendbare SzenarienBesonders geeignet für einfache Anwendungen wie Dashboards, Landing Pages und Registrierungsformulare.
- CodegenerierungDer generierte Code ist gut strukturiert und effektiv.
Hilfe verwenden
UIGEN-T1 ist in der Lage, HTML- und CSS-Code für Benutzeroberflächen (UI) auf der Grundlage von Stichworten zu generieren. Im Folgenden werden die grundlegenden Schritte und Überlegungen zur Verwendung des Modells beschrieben:
1. die Umwelt vorbereiten
Stellen Sie sicher, dass Ihre Umgebung die folgenden Anforderungen erfüllt:
- SoftwareEs werden mindestens 12 GB VRAM empfohlen.
- Hardware::
- Transformers-Bibliothek (Umarmendes Gesicht)
- PyTorch
2. die Installation von Abhängigkeiten
pip install transformers
pip install torch
3. grundlegender Argumentationscode
Verwenden Sie den folgenden Code für grundlegende Überlegungen:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "smirki/UIGEN-T1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")
prompt = """<|im_start|>user
Make a dark-themed dashboard for an oil rig.<|im_end|>
<|im_start|>assistant
<|im_start|>think
"""
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=12012, do_sample=True, temperature=0.7) #max tokens has to be greater than 12k
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
4. die Auslegung des Kodex
- Modellbeladung::
model_name = "smirki/UIGEN-T1": Gibt den Modellnamen an.tokenizer = AutoTokenizer.from_pretrained(model_name): Laden Sie den vortrainierten Disambiguator.model = AutoModelForCausalLM.from_pretrained(model_name).to("cuda")Laden Sie das Modell und verschieben Sie es auf das CUDA-Gerät (falls vorhanden).
- Vorbereitung des Stichworts::
promptAufforderungswörter, die Benutzeranweisungen enthalten. Erstellen Sie z. B. ein dunkles Themen-Dashboard für eine Bohrinsel.
- modellhafte Argumentation::
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")Cue word: Konvertiert das Cue word in einen PyTorch-Tensor und verschiebt es auf ein CUDA-Gerät.outputs = model.generate(**inputs, max_new_tokens=12012, do_sample=True, temperature=0.7)Ausgabe generieren.max_new_tokensLegt die maximale Anzahl der generierten Token fest, die größer als 12012 sein muss.do_sampleSampling: Ermöglicht Sampling, um die Vielfalt der generierten Inhalte zu erhöhen.temperature: steuert die Vielfalt der generierten Inhalte; niedrigere Werte machen die Ausgabe deterministischer.
- Ausgabe Dekodierung::
print(tokenizer.decode(outputs, skip_special_tokens=True))Dekodieren des generierten Tokens in Text und Drucken des Ergebnisses.
5. techniken der Verwendung
- Stichwort Technik::
- Für eine bessere Argumentation kann es erforderlich sein, am Ende der Eingabeaufforderung "Antwort" hinzuzufügen.
- Beispiel:
Make a dark-themed dashboard for an oil rig. answer
- Manuelles Post-Processing::
- Der generierte UI-Code muss möglicherweise manuell nachbearbeitet werden, um ihn zu verfeinern.
- Feintuning::
- Das Modell kann für bestimmte Front-End-Frameworks (z. B. React, Vue usw.) weiter verfeinert werden.
6. beschränkungen
- Nicht geeignet für komplexe Front-End-AnwendungenDieses Modell gilt nicht für komplexe Front-End-Anwendungen, die eine Vielzahl von JavaScript-Interaktionen beinhalten.
- Begrenzte DesignvielfaltDas Modell begünstigt einfache Front-End-Layouts und kann keine kreativen oder fortgeschrittenen UI-Layouts erzeugen.
- Artefakte: Einige Ausgaben können Formatierungsartefakte enthalten.
7. anwendbare Szenarien
- InstrumententafelnSchnelles Erstellen von Bildschirmen zur Datenpräsentation.
- ZielseiteErstellen einfacher einseitiger Anwendungen.
- AnmeldeformularGenerieren Sie den Bildschirm für die Benutzerregistrierung.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...