TPO-LLM-WebUI: Ein KI-Framework, in das Sie Fragen eingeben können, um ein Modell in Echtzeit zu trainieren und die Ergebnisse auszugeben.
Allgemeine Einführung
TPO-LLM-WebUI ist ein innovatives Projekt, das von Airmomo auf GitHub zur Verfügung gestellt wird und die Echtzeit-Optimierung von Large Language Models (LLMs) über eine intuitive Webschnittstelle ermöglicht. Es nutzt das TPO-Framework (Test-Time Prompt Optimization) und verabschiedet sich damit vollständig vom mühsamen Prozess der traditionellen Feinabstimmung und optimiert direkt die Modellausgabe ohne Training. Nachdem der Benutzer eine Frage eingegeben hat, verwendet das System Belohnungsmodelle und iteratives Feedback, um dem Modell zu ermöglichen, sich während des Denkprozesses dynamisch weiterzuentwickeln, wodurch es immer intelligenter wird und die Qualität der Ausgabe um bis zu 50% verbessert.


Funktionsliste
- Entwicklung in EchtzeitOptimierung des Outputs durch die Inferenzphase: Je mehr er verwendet wird, desto mehr entspricht er den Bedürfnissen des Benutzers.
- Keine Feinabstimmung erforderlichKeine Aktualisierung der Modellgewichte und direkte Verbesserung der Generierungsqualität.
- Multimodell-kompatibelUnterstützung für das Laden verschiedener Basis- und Belohnungsmodelle.
- Dynamischer Abgleich der PräferenzenAnpassung der Leistung auf der Grundlage von Belohnungsrückmeldungen, um sich den menschlichen Erwartungen anzunähern.
- Visualisierung von ArgumentenDemonstration des Iterationsprozesses der Optimierung zum besseren Verständnis und zur Fehlersuche.
- Leicht und effizient: Computing ist kostengünstig und einfach zu implementieren.
- Quelloffen und flexibelBereitstellung von Quellcode und Unterstützung der benutzerdefinierten Entwicklung.
Hilfe verwenden
Einbauverfahren
Für den Einsatz von TPO-LLM-WebUI sind einige grundlegende Umgebungseinstellungen erforderlich. Nachfolgend finden Sie die detaillierten Schritte, um den Benutzern einen schnellen Einstieg zu ermöglichen.
1. die Umwelt vorbereiten
Stellen Sie sicher, dass die folgenden Werkzeuge installiert sind:
- Python 3.10Kernbetriebsumgebung.
- GitProjektcode: Wird verwendet, um den Projektcode zu erhalten.
- GPU (empfohlen)NVIDIA-GPUs beschleunigen die Inferenz.
Erstellen Sie eine virtuelle Umgebung:
Verwenden Sie Condi:
conda create -n tpo python=3.10
conda activate tpo
oder Pythons eigene Werkzeuge:
python -m venv tpo
source tpo/bin/activate # Linux/Mac
tpo\Scripts\activate # Windows
Laden Sie die Abhängigkeiten herunter und installieren Sie sie:
git clone https://github.com/Airmomo/tpo-llm-webui.git
cd tpo-llm-webui
pip install -r requirements.txt
Installieren Sie TextGrad:
TPO stützt sich auf TextGrad, das eine zusätzliche Installation erfordert:
cd textgrad-main
pip install -e .
cd ..
2. das Konfigurationsmodell
Sie müssen das Basismodell und das Bonusmodell manuell herunterladen:
- GrundmodellAls
deepseek-ai/DeepSeek-R1-Distill-Qwen-32B(Gesicht umarmen) - AnreizmodellierungAls
sfairXC/FsfairX-LLaMA3-RM-v0.1(Gesicht umarmen)
Legen Sie das Modell in das angegebene Verzeichnis (z. B./model/HuggingFace/), und inconfig.yamlLegen Sie den Pfad im Feld
3. starten Sie den vLLM-Dienst
ausnutzen vLLM Hosting-Basismodell. Nehmen Sie als Beispiel 2 GPUs:
vllm serve /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--dtype auto
--api-key token-abc123
--tensor-parallel-size 2
--max-model-len 59968
--port 8000
Nachdem der Dienst ausgeführt wurde, hören Sie die http://127.0.0.1:8000.
4. die WebUI ausführen
Starten Sie das Webinterface in einem neuen Terminal:
python gradio_app.py
Browser-Zugang http://127.0.0.1:7860Im Folgenden finden Sie eine Liste der bekanntesten und beliebtesten Produkte auf dem Markt.
Hauptfunktionen
Funktion 1: Modellinitialisierung
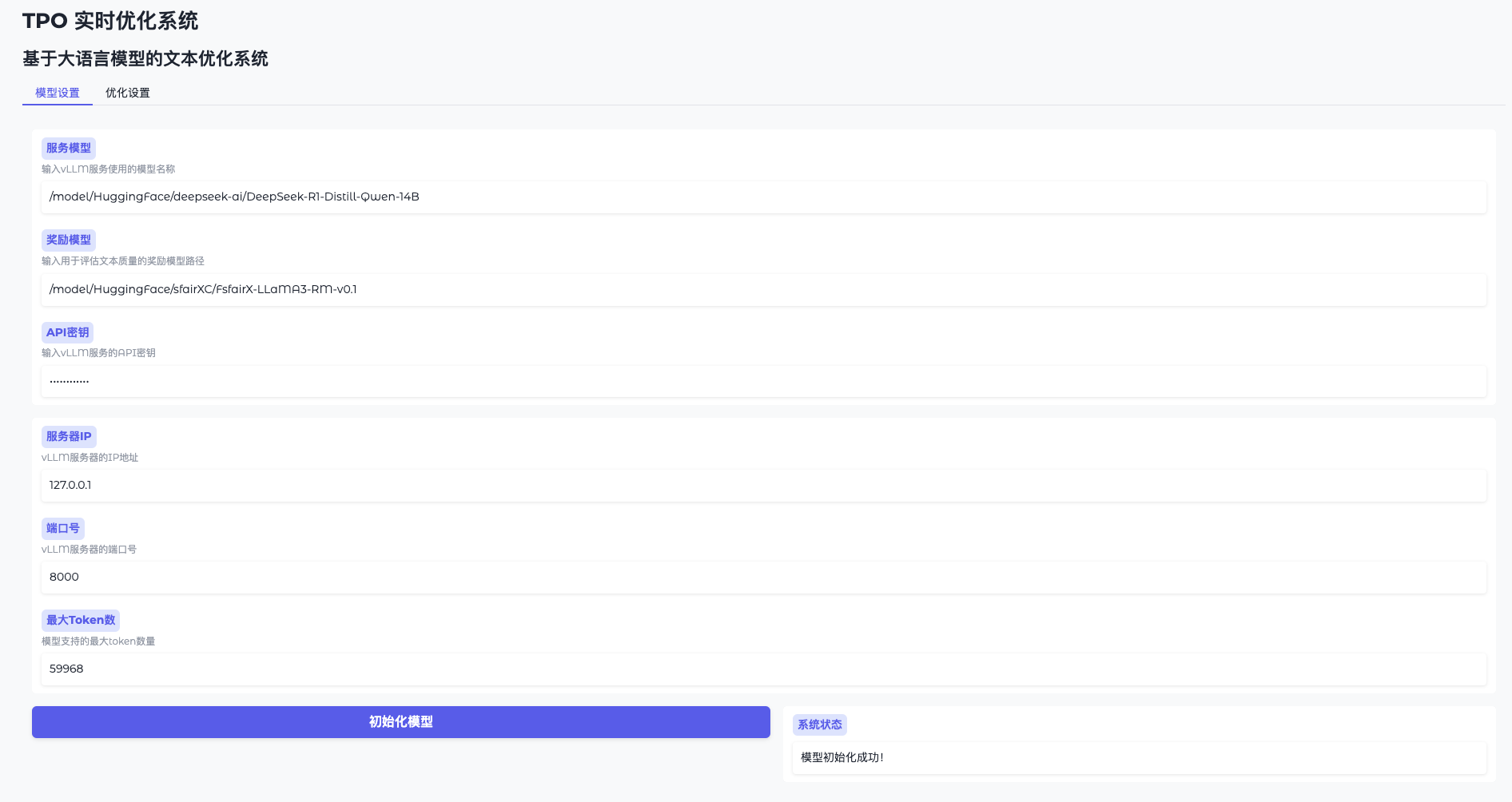
- Modell-Einstellungen öffnen
Gehen Sie zur WebUI und klicken Sie auf "Modelleinstellungen". - Verbinden mit vLLM
Geben Sie die Adresse ein (z. B.http://127.0.0.1:8000) und den Schlüssel (token-abc123). - Laden des Belohnungsmodells
Geben Sie den Pfad an (z. B./model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1Klicken Sie auf "Initialisieren" und warten Sie 1-2 Minuten. - Bestätigung der Bereitschaft
Die Schnittstelle meldet "Modell bereit" und Sie können fortfahren.
Funktion 2: Optimierung der Leistung in Echtzeit
- Seite zur Optimierung umschalten
Gehen Sie zu "Einstellungen optimieren". - Probleme bei der Eingabe
Geben Sie Inhalte wie "Dieses technische Dokument ausbessern" ein. - Operative Optimierung
Klicken Sie auf "Optimierung starten" und das System generiert mehrere Kandidatenergebnisse und verbessert diese iterativ. - Überprüfen Sie den evolutionären Prozess
Auf der Ergebnisseite werden die ursprüngliche und die optimierte Ausgabe angezeigt, wobei die Qualität schrittweise zunimmt.
Funktion 3: Optimierung des Skriptmodus
Wenn Sie nicht die WebUI verwenden, können Sie ein Skript ausführen:
python run.py
--data_path data/sample.json
--ip 0.0.0.1
--port 8000
--server_model /model/HuggingFace/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
--reward_model /model/HuggingFace/sfairXC/FsfairX-LLaMA3-RM-v0.1
--tpo_mode tpo
--max_iterations 2
--sample_size 5
Die Optimierungsergebnisse werden gespeichert in logs/ Mappe.
Detaillierte Beschreibung der besonderen Merkmale
Verabschieden Sie sich von der Feinabstimmung und entwickeln Sie sich in Echtzeit weiter
- Verfahren::
- Geben Sie die Frage ein, und das System generiert die erste Antwort.
- Belohnen Sie die Modellbewertung und das Feedback, um die nächste Iteration zu steuern.
- Nach mehreren Iterationen wird die Ausgabe "intelligenter" und die Qualität verbessert sich erheblich.
- SchneidkanteSparen Sie Zeit und Rechenaufwand, indem Sie jederzeit ohne Training optimieren können.
Je mehr Sie es benutzen, desto intelligenter wird es.
- Verfahren::
- Verwenden Sie dasselbe Modell mehrmals mit unterschiedlichen Eingaben für verschiedene Probleme.
- Das System sammelt Erfahrungen auf der Grundlage der einzelnen Rückmeldungen, und die Ausgabe ist besser auf die Bedürfnisse zugeschnitten.
- SchneidkanteDynamisches Lernen der Benutzerpräferenzen für langfristig bessere Ergebnisse.
caveat
- Hardware-VoraussetzungEmpfohlene 16 GB Videospeicher oder mehr, mehrere GPUs müssen sicherstellen, dass Ressourcen frei und verfügbar sind.
export CUDA_VISIBLE_DEVICES=2,3Benennung. - Lösung von ProblemenWenn der Videospeicher überläuft, senken Sie die
sample_sizeoder die Belegung der GPU überprüfen. - Unterstützung der Gemeinschaft: Siehe die GitHub README oder Issues für Hilfe.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...