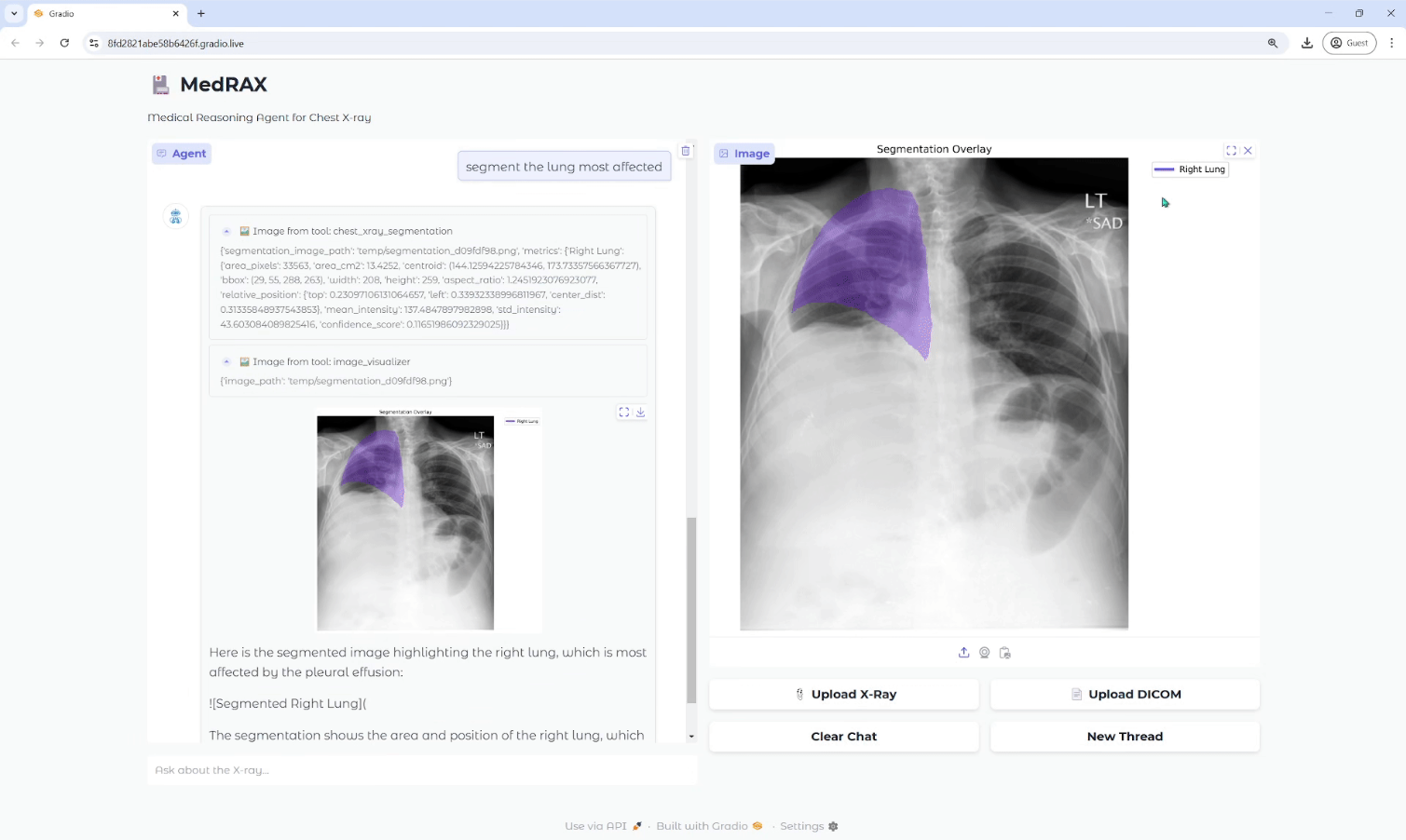
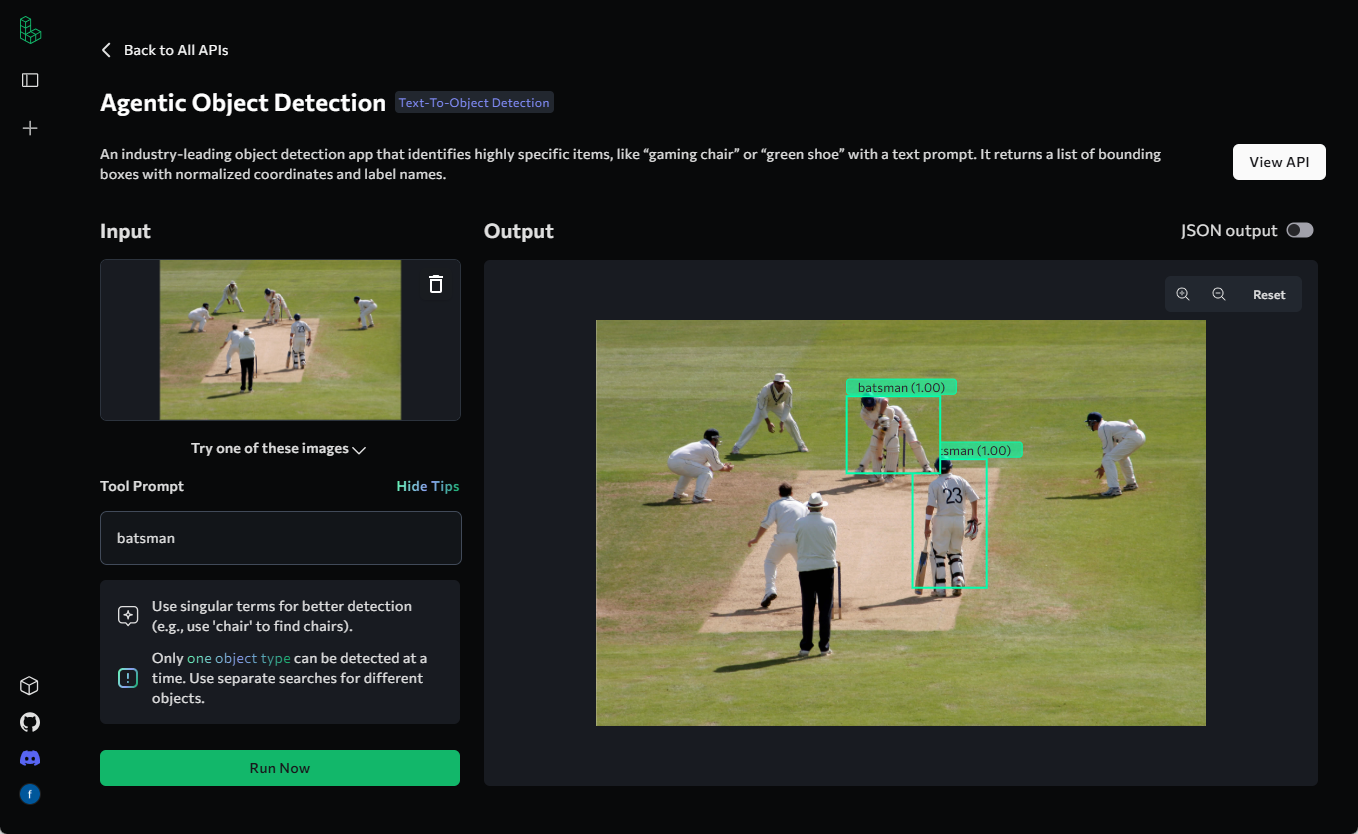
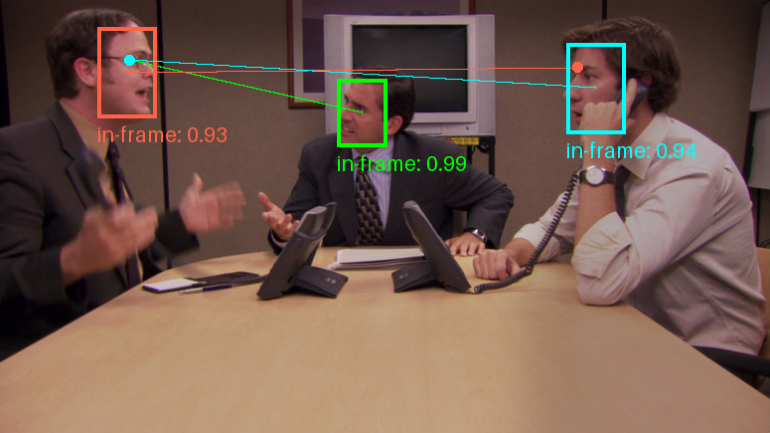
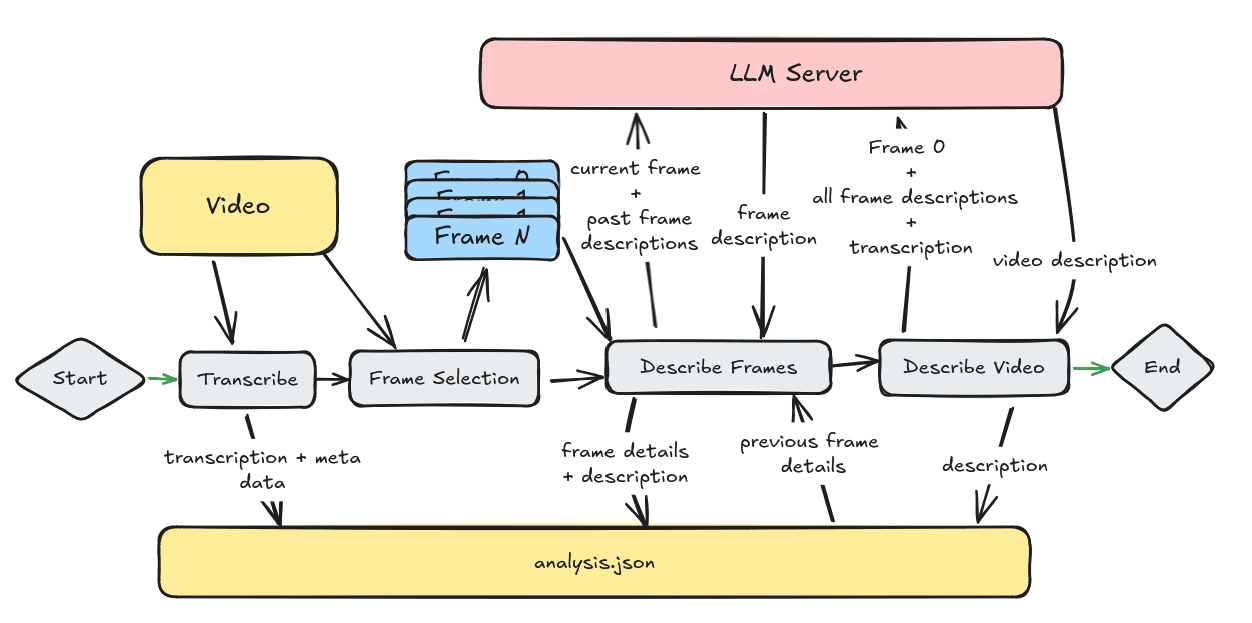
Trackers: Open-Source-Werkzeugbibliothek für die Verfolgung von Videoobjekten
Allgemeine Einführung Trackers ist eine Open-Source-Python-Werkzeugbibliothek, die sich auf die Verfolgung von mehreren Objekten in Videos konzentriert. Sie integriert mehrere führende Verfolgungsalgorithmen wie SORT und DeepSORT und ermöglicht es dem Benutzer, verschiedene Modelle zur Objekterkennung zu kombinieren (wie YOLO...