
Sesame veröffentlicht Conversational Speech Model CSM: KI-Sprachinteraktion wird natürlicher
Ein aktueller Blogbeitrag von Brendan Iribe, Ankit Kumar und dem Sesame-Team beschreibt die neueste Forschung des Unternehmens auf dem Gebiet der Spracherzeugung, das Conversational Speech Model (CSM). CSM). Das Modell wurde entwickelt, um den Mangel an Emotionen und Natürlichkeit in aktuellen Sprachassistenten-Interaktionen zu beheben und KI-Sprachinteraktionen näher an die menschliche Ebene heranzuführen.
Durchquerung des "Tals des Schreckens" auf der Suche nach "Sprachpräsenz".
Das Sesame-Team ist davon überzeugt, dass die Stimme das intimste Kommunikationsmedium für Menschen ist und eine Fülle von Informationen enthält, die weit über die wörtliche Bedeutung hinausgehen. Den bestehenden Sprachassistenten fehlt es jedoch oft an emotionalem Ausdruck und sie haben einen flachen Ton, was es schwierig macht, eine tiefe Verbindung mit den Nutzern aufzubauen. Wenn solche Sprachassistenten über einen längeren Zeitraum verwendet werden, fühlen sich die Nutzer nicht nur enttäuscht, sondern auch müde.
Um dieses Problem zu lösen, hat Sesame das Konzept der "Sprachpräsenz" entwickelt, was bedeutet, dass sich Sprachinteraktionen real, verstanden und geschätzt anfühlen, und das CSM-Modell ist ein wichtiger Schritt in Richtung dieses Ziels. Das Sesame-Team betont, dass es nicht nur ein Werkzeug, sondern einen Dialogpartner schafft, der eine vertrauensvolle Beziehung mit dem Nutzer aufbaut.
Das Erreichen von "Sprachpräsenz" ist keine leichte Aufgabe und erfordert eine Kombination der folgenden Schlüsselelemente:
- Emotionale Intelligenz: Erkennen von und Reagieren auf Stimmungsschwankungen des Nutzers.
- Dynamik des Dialogs: Erfassen des natürlichen Rhythmus eines Dialogs, einschließlich Sprechtempo, Pausen, Unterbrechungen und Betonung.
- Situationsbewusstheit: Anpassung von Tonfall und Ausdruck an verschiedene Dialogsituationen.
- Konsistente Persönlichkeit: Behalten Sie die Konsistenz und Zuverlässigkeit der Persönlichkeit des KI-Assistenten bei.
CSM-Modell: einstufig, multimodal, effizienter
Um diese Ziele zu erreichen, hat das Sesame-Team ein neues Konversations-Sprachmodell, CSM, vorgeschlagen, das einen durchgängigen multimodalen Lernrahmen verwendet, um eine natürlichere und kohärentere Sprache unter Verwendung von Informationen aus dem Gesprächsverlauf zu erzeugen.
Im Gegensatz zu herkömmlichen Text-to-Speech-Modellen (TTS) arbeitet das CSM-Modell direkt mit RVQ-Tokens (residuale Vektorquantisierung). Dieses Design vermeidet den Informationsengpass, der durch semantische Token in traditionellen TTS-Modellen verursacht werden kann, und erfasst so besser die Nuancen in der Sprache.
CSM Auch die Architektur des Modells ist recht beeindruckend. Es setzt zwei autoregressive Transformatoren ein:
- Multimodales Grundgerüst: Verarbeitung von verschachtelten Text- und Audioinformationen zur Vorhersage der Schicht Null des RVQ-Codebuchs.
- Audio-Decoder: Unter Verwendung eines anderen linearen Headers für jedes Codebuch werden die verbleibenden N-1 Schichten vorhergesagt, um die Sprache zu rekonstruieren.
Durch dieses Design kann der Decoder viel kleiner sein als der Trunk, was zu einer Spracherzeugung mit geringer Latenz führt, während das Modell durchgängig erhalten bleibt.

CSM-Modell-Inferenzprozess
Um das Problem des Speicherengpasses während des Trainingsprozesses zu lösen, schlug das Sesame-Team ein Verfahren zur Aufteilung der Rechenleistung vor. Mit diesem Schema wird der Audio-Decoder nur auf einer zufälligen Teilmenge von Audio-Frames trainiert, was den Speicherverbrauch erheblich reduziert, ohne die Modellleistung zu beeinträchtigen.

Aufteilung des Ausbildungsprozesses
Experimentelle Ergebnisse: nahe am menschlichen Niveau, aber immer noch eine Lücke
Das Sesame-Team trainierte das CSM-Modell auf einem Datensatz, der etwa 1 Million Stunden englischer Audiodaten enthält, und bewertete die Leistung des Modells gründlich anhand einer Reihe von Metriken.
Die Evaluierungsergebnisse zeigen, dass das CSM-Modell in den traditionellen Metriken Word Error Rate (WER) und Speaker Similarity (SIM) dem menschlichen Niveau nahe kommt.
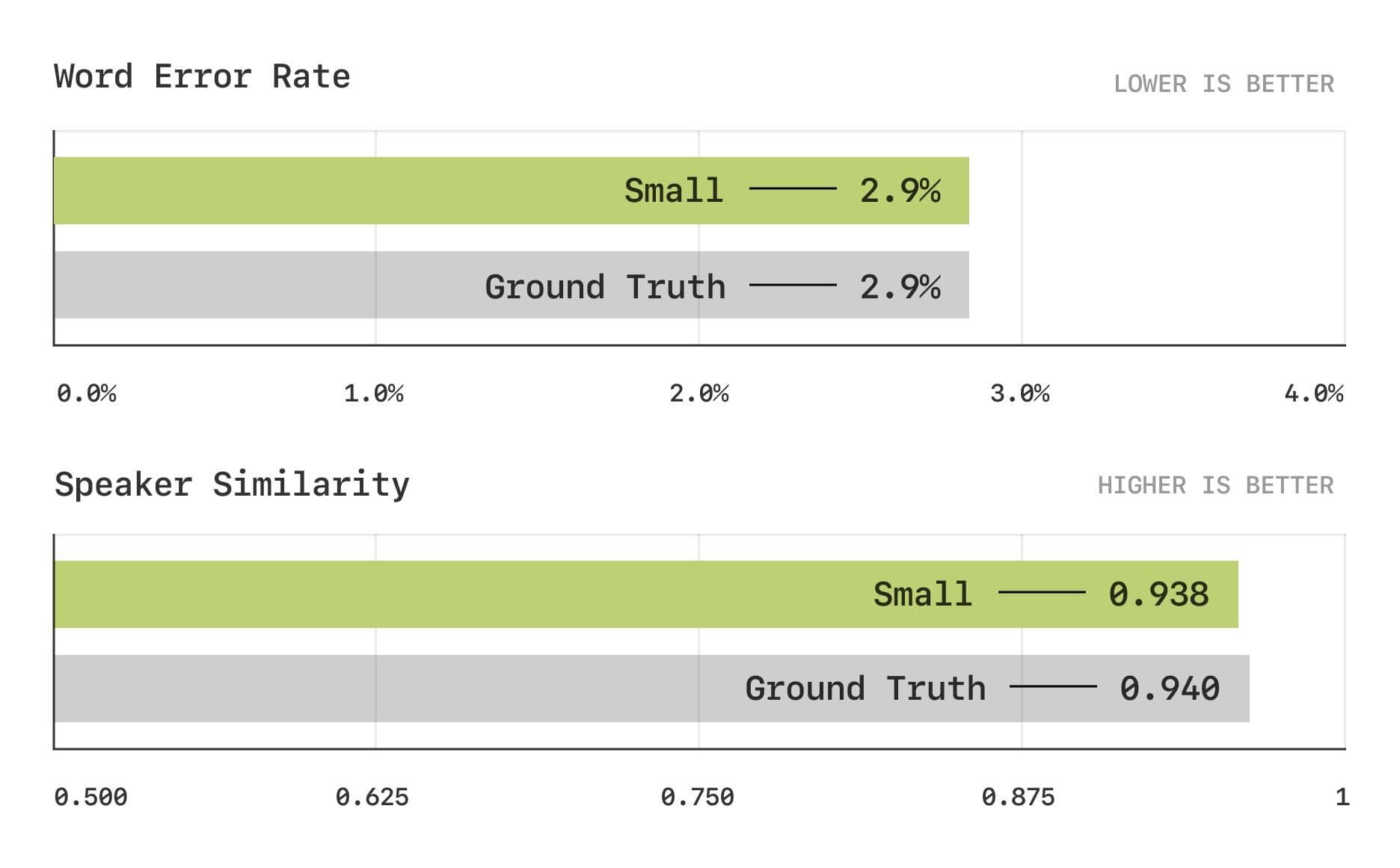
Wortfehlerrate und Sprecherähnlichkeitstests
Um die Fähigkeiten des Modells in den Bereichen Aussprache und Kontextverständnis eingehender zu evaluieren, hat das Sesame-Team außerdem eine Reihe neuer, auf Sprachtranskription basierender Benchmark-Tests eingeführt, darunter Tests zur Disambiguierung von Homophonen und zur Konsistenz der Aussprache. Die Ergebnisse zeigen, dass das CSM-Modell auch in diesen Bereichen gut abschneidet und dass sich die Leistung mit zunehmender Modellgröße verbessert.
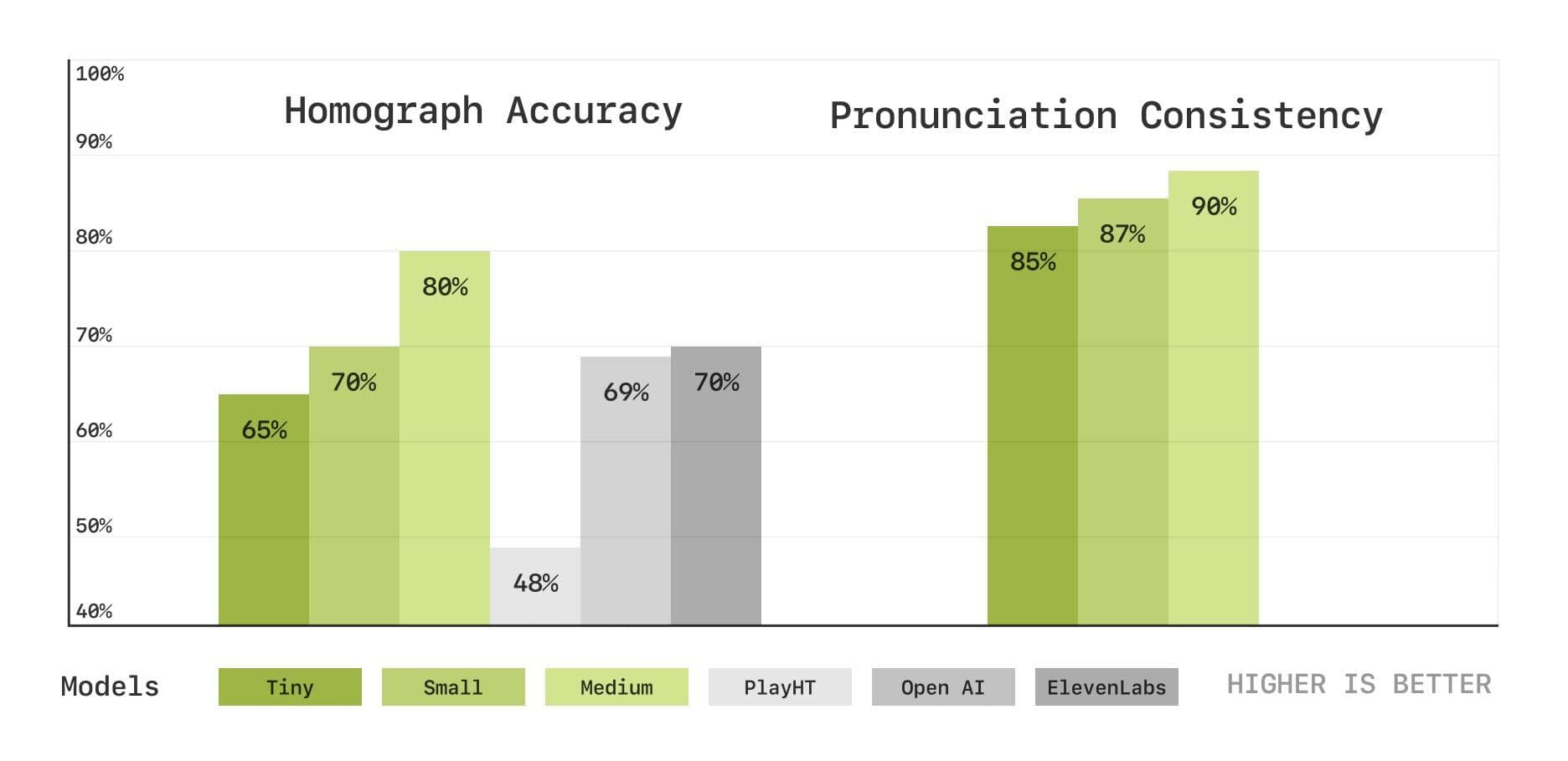
Tests zur Disambiguierung von Homophonen und zur Konsistenz der Aussprache
Das Sesame-Team führte zwei CMOS-Studien (Comparative Mean Opinion Score) mit dem Expresso-Datensatz durch, die zeigen, dass die Präferenzen der Hörer zwischen dem CSM-Modell und echter menschlicher Sprache vergleichbar sind. Die Ergebnisse zeigten, dass die Hörer ohne Kontext vergleichbare Präferenzen für CSM-generierte Sprache und echte menschliche Sprache hatten. Wenn jedoch Kontextinformationen zur Verfügung gestellt wurden, bevorzugten die Hörer deutlich die echte menschliche Sprache. Dies deutet darauf hin, dass das CSM-Modell bei der Erfassung subtiler rhythmischer Veränderungen im Dialog noch verbesserungswürdig ist.
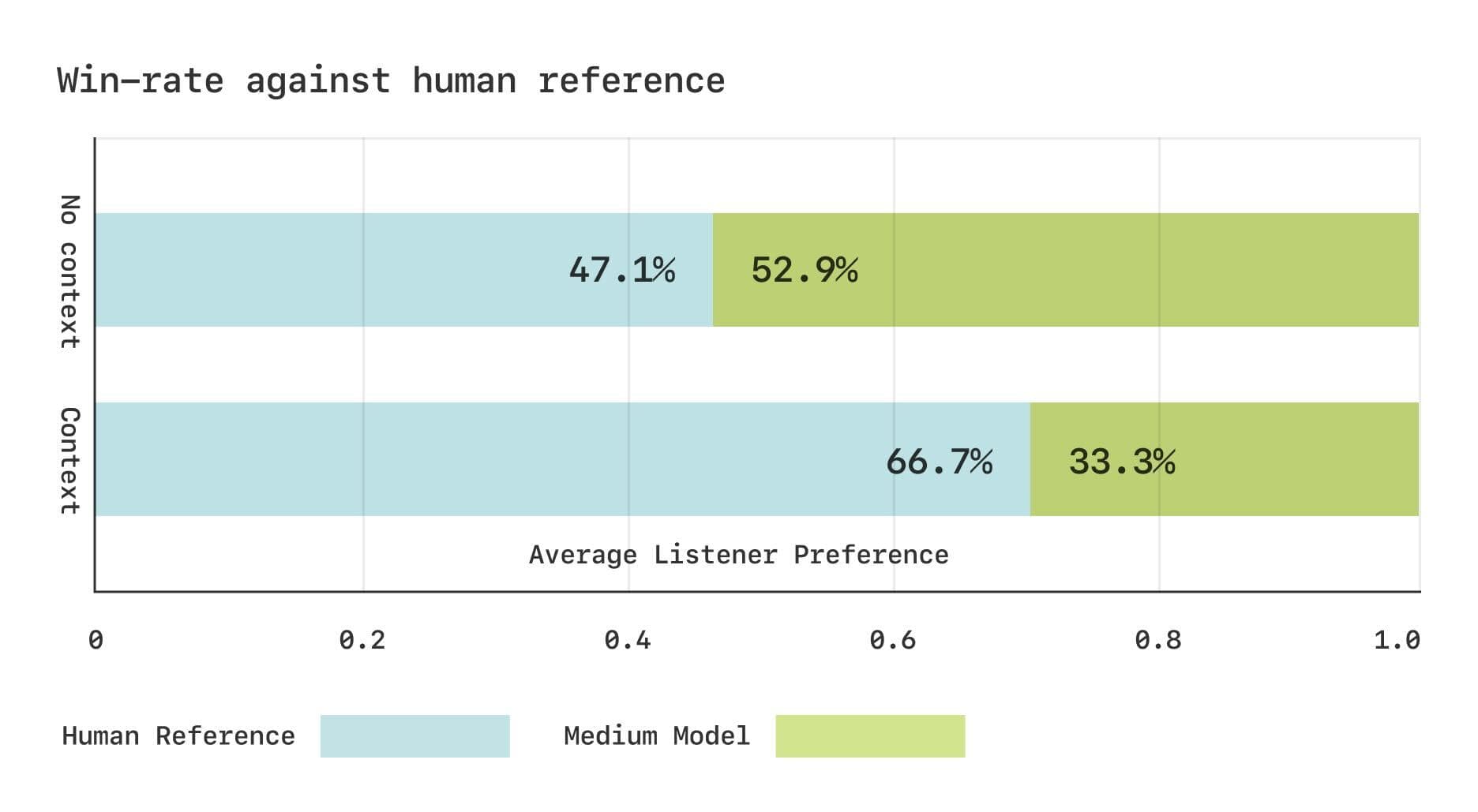
Subjektive Bewertungsergebnisse für den Expresso-Datensatz
Open Source Sharing, Zukunftsperspektiven
Im Geiste von Open Source plant das Sesame-Team, Schlüsselkomponenten des CSM-Modells für die gemeinsame Entwicklung der Gemeinschaft zu öffnen.
https://github.com/SesameAILabs/csm
Obwohl das CSM-Modell bedeutende Fortschritte gemacht hat, hat es immer noch einige Einschränkungen, wie z. B. die Unterstützung von hauptsächlich Englisch, wobei die mehrsprachigen Fähigkeiten noch verbessert werden müssen. Das Sesame-Team sagte, dass es in Zukunft die Modellgröße weiter vergrößern, die Kapazität des Datensatzes erhöhen, die Sprachunterstützung erweitern und die Verwendung von vortrainierten Sprachmodellen erforschen wird, um die Leistung des CSM-Modells weiter zu verbessern. Das Sesame-Team ist zuversichtlich, was die zukünftige Richtung seiner Forschung betrifft. Das Sesame-Team ist zuversichtlich, dass die Zukunft des KI-Dialogs in Vollduplex-Modellen liegt, d.h. in Modellen, die die Dialogdynamik implizit aus den Daten lernen können.
Insgesamt ist das von Sesame veröffentlichte CSM-Modell ein wichtiger Schritt nach vorn im Bereich der Spracherzeugung und liefert neue Ideen für die Entwicklung natürlicherer und emotionaler KI-Sprachinteraktionen. Obwohl es noch Raum für Verbesserungen gibt, sind der Open-Source-Geist des Sesame-Teams und seine Pläne für die Zukunft einen Blick wert.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...