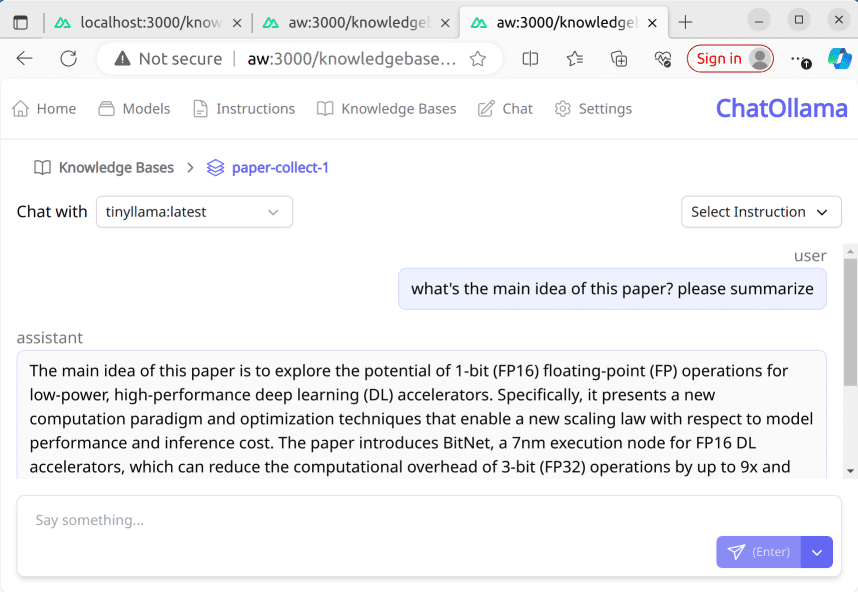
Textextraktions-API (text-extract-api): visuelle Extraktion von Textinformationen, anonymisiertes PDF-Extraktionswerkzeug
Allgemeine Einführung
Die Textextraktions-API (text-extract-api) ist ein leistungsstarkes Tool zum Extrahieren und Parsen von Inhalten aus einer Vielzahl von Dokumentenformaten (z. B. PDF, Word, PPTX usw.). Die API nutzt modernste OCR-Technologie (Optical Character Recognition) und Ollama-unterstützte Modelle, um jedes Dokument oder Bild in ein strukturiertes JSON- oder Markdown-Format zu konvertieren. Zu den wichtigsten Funktionen gehören die hochpräzise Textextraktion, die Entfernung personenbezogener Daten (PII), die Unterstützung mehrerer Speicherstrategien und die verteilte Aufgabenverarbeitung. Die API für die Textextraktion wurde mit FastAPI entwickelt und verwendet Celery für die asynchrone Aufgabenverarbeitung und Redis für die Zwischenspeicherung von OCR-Ergebnissen, um eine effiziente und zuverlässige Dokumentenverarbeitung zu gewährleisten.
pdf-extract-api ist eine Dokumentenextraktions- und -parsing-API, die die Anonymisierung von Dokumenten mit modernster OCR-Technologie und von Ollama unterstützten Modellen unterstützt. Sie kann jedes Dokument oder Bild in strukturiertes JSON oder Markdown konvertieren und unterstützt die hochpräzise Extraktion von Tabellendaten, Zahlen und mathematischen Formeln. Die auf FastAPI basierende API verwendet Celery für die asynchrone Verarbeitung von Aufgaben und Redis für die Zwischenspeicherung von OCR-Ergebnissen, um eine effiziente und zuverlässige Verarbeitung von Dokumenten zu gewährleisten.
:视觉提取文本信息,匿名化的PDF提取工具-1")

Funktionsliste
- Hochpräzise OCR: Verwenden Sie PyTorch, Marker, Llama3.2-vision und andere OCR-Strategien für eine hochpräzise Textextraktion.
- Dokumentenkonvertierung: Unterstützung für PDF-, Word-, PPTX- und andere Dokumente im Markdown- oder JSON-Format.
- PII entfernen: Identifiziert und entfernt automatisch persönlich identifizierbare Informationen aus Dokumenten.
- Verteilte Verarbeitung: Verwenden Sie Celery für die verteilte Aufgabenverarbeitung, um die Verarbeitungseffizienz zu verbessern.
- Caching-Mechanismus: Verwenden Sie Redis zum Zwischenspeichern von OCR-Ergebnissen, um die wiederholte Verarbeitungszeit zu reduzieren.
- Multi-Storage-Strategie: Unterstützung von lokalem Dateisystem, Google Drive und anderen Speichermethoden.
- CLI-Tools: Bereitstellung von Befehlszeilentools, die es den Benutzern erleichtern, Aufgaben zu senden und die Ergebnisse zu verarbeiten.
Hilfe verwenden
Einbauverfahren
- Ollama herunterladen und installieren.
- Laden Sie Docker herunter und installieren Sie es.
- Klonen Sie das text-extract-api-Repository:
git clone https://github.com/CatchTheTornado/text-extract-api.git
- Wechseln Sie in das Projektverzeichnis und starten Sie den Docker-Container:
cd text-extract-api
docker-compose up
Verwendung
Konvertierung von Dokumenten
- Laden Sie die zu konvertierenden Dokumente in das angegebene Verzeichnis hoch.
- Verwenden Sie das CLI-Tool, um Konvertierungsaufgaben zu senden:
python client/cli.py ocr_upload --file examples/example.pdf --prompt_file examples/example-to-json-prompt.txt
- Das Konvertierungsergebnis wird im JSON- oder Markdown-Format im angegebenen Verzeichnis gespeichert.
Entfernung von PII
- Laden Sie ein Dokument hoch, das PII enthält.
- Verwenden Sie das CLI-Tool, um Aufgaben zum Entfernen von PII zu senden:
python client/cli.py ocr_upload --file examples/example-pii.pdf --prompt_file examples/example-remove-pii.txt
- Aus den bearbeiteten Dokumenten werden alle personenbezogenen Daten entfernt.
Detaillierte Funktionsabläufe
- Hochpräzise OCRDurch die Konfiguration verschiedener OCR-Strategien (z.B. Marker, Llama3.2-vision, etc.) wird eine hochpräzise Textextraktion für verschiedene Dokumente erreicht. Der Benutzer kann je nach Dokumententyp die am besten geeignete OCR-Strategie auswählen.
- Konvertierung von DokumentenUnterstützung für PDF, Word, PPTX und andere Formate: Das Dokument wird in das Markdown- oder JSON-Format umgewandelt, um die spätere Datenverarbeitung und -analyse zu erleichtern.
- Entfernung von PIIIdentifiziert und entfernt automatisch personenbezogene Informationen aus Dokumenten, um den Datenschutz und die Datensicherheit zu gewährleisten.
- verteilte VerarbeitungDistributed task processing using Celery to support large-scale document processing tasks and improve processing efficiency.
- Caching-MechanismusRedis zum Zwischenspeichern von OCR-Ergebnissen verwenden, um die wiederholte Verarbeitungszeit zu reduzieren und die Reaktionszeit des Systems zu verbessern.
- Multi-Storage-PolitikEs werden verschiedene Speichermethoden unterstützt, wie z. B. das lokale Dateisystem, Google Drive usw. Die Benutzer können je nach ihren Bedürfnissen die geeignete Speicherstrategie wählen.
- CLI-ToolsBefehlszeilentools: Es werden Befehlszeilentools zur Verfügung gestellt, damit die Benutzer mit einfachen Befehlen Aufgaben senden und Ergebnisse verarbeiten können.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...