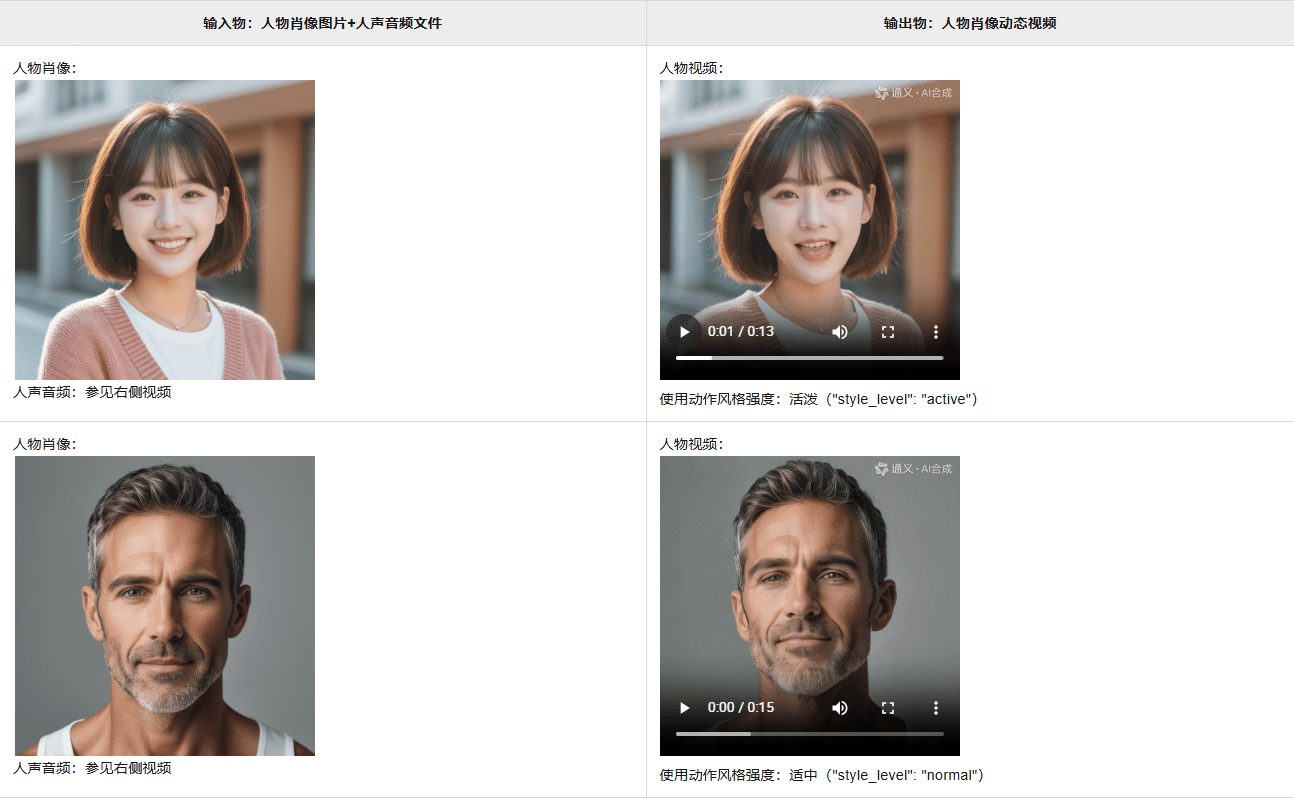
OpenAvatarChat: ein modular aufgebautes Werkzeug für den digitalen menschlichen Dialog

Allgemeine Einführung
OpenAvatarChat ist ein Open-Source-Projekt, das vom HumanAIGC-Engineering-Team entwickelt und auf GitHub gehostet wird. Es ist ein modulares Werkzeug für den digitalen menschlichen Dialog, das es den Benutzern ermöglicht, die volle Funktionalität auf einem einzigen PC auszuführen. Das Projekt kombiniert Echtzeit-Video, Spracherkennung und digitale Menschentechnologie mit flexiblem modularem Design und Interaktion mit geringer Latenz als Kernfunktionen. Die Audiokomponente verwendet SenseVoice, qwen-plus und CosyVoice Der Videoteil basiert auf dem LiteAvatar-Algorithmus. Der Code ist völlig offen für Entwickler zu studieren und zu verbessern.

Funktionsliste
- Modularer digitaler menschlicher Dialog: unterstützt Echtzeit-Interaktion mit Sprache und Video, Module können frei kombiniert werden.
- Audio- und Videoübertragung in Echtzeit: Audio- und Videokommunikation mit niedriger Latenz über gradio-webrtc.
- Spracherkennung und -erzeugung: Integration von SenseVoice und CosyVoice zur Verarbeitung von Spracheingabe und -ausgabe.
- Digitale Menschenanimation: Erzeugen Sie mit LiteAvatar flüssige digitale menschliche Mimik und Bewegungen.
- Open-Source-Unterstützung: Der vollständige Code wird zur Verfügung gestellt, und die Benutzer können ihn nach ihren Bedürfnissen verändern oder optimieren.
Hilfe verwenden
OpenAvatarChat ist ein Open-Source-Projekt, bei dem die Benutzer den Code selbst herunterladen und die Umgebung selbst konfigurieren müssen. Im Folgenden finden Sie eine ausführliche Anleitung zur Installation und Nutzung, damit Sie schnell loslegen können.
Einbauverfahren
- Überprüfung der Systemanforderungen
Bevor Sie beginnen, vergewissern Sie sich, dass Ihr Gerät die folgenden Bedingungen erfüllt:- Python 3.10 oder höher.
- CUDA-fähiger Grafikprozessor mit mindestens 10 GB Grafikspeicher (20 GB oder mehr für nicht quantisierte Modelle).
- Die CPU-Leistung ist stark (getestet bei 30FPS mit i9-13980HX).
Sie können die Python-Version mit dem folgenden Befehl überprüfen:
python --version
- Installation von Git LFS
Das Projekt verwendet Git LFS, um große Dateien zu verwalten, also installieren Sie es zuerst:
sudo apt install git-lfs
git lfs install
- Code herunterladen
Klonen Sie das Projekt lokal, indem Sie den folgenden Befehl in das Terminal eingeben:
git clone https://github.com/HumanAIGC-Engineering/OpenAvatarChat.git
cd OpenAvatarChat
- Aktualisierung von Untermodulen
Das Projekt stützt sich auf mehrere Untermodule, die durch Ausführen des folgenden Befehls aktualisiert werden:
git submodule update --init --recursive
- Modelle herunterladen
Das multimodale Sprachmodell MiniCPM-o-2.6 muss manuell heruntergeladen werden. Sie können es herunterladen von Umarmungsgesicht vielleicht Modelscope Holen. Legen Sie das Modell in diemodels/oder führen Sie ein Skript aus, um es automatisch herunterzuladen:
scripts/download_MiniCPM-o_2.6.sh
Wenn der Videospeicher nicht ausreicht, können Sie die quantisierte Version von int4 herunterladen:
scripts/download_MiniCPM-o_2.6-int4.sh
- Installation von Abhängigkeiten
Führen Sie es im Stammverzeichnis des Projekts aus:
pip install -r requirements.txt
- SSL-Zertifikat generieren
Wenn ein Fernzugriff erforderlich ist, erstellen Sie ein selbstsigniertes Zertifikat:
scripts/create_ssl_certs.sh
Zertifikate werden standardmäßig in der Datei ssl_certs/ Mappe.
- laufendes Programm
Es gibt zwei Arten von Start-ups:
- direkt laufen::
python src/demo.py - Containerbetrieb(Nvidia Docker erforderlich):
build_and_run.sh
Hauptfunktionen
- Start des digitalen menschlichen Dialogs
Nachdem Sie das Programm gestartet haben, öffnen Sie einen Browser und besuchen Siehttps://localhost:8282(Ports sind verfügbar auf derconfigs/sample.yaml(Ändern). Die Schnittstelle zeigt die digitale Person, klicken Sie auf "Start", das Programm ruft die Kamera und das Mikrofon auf und geht in den Dialogmodus. - Sprachinteraktion
Wenn Sie in das Mikrofon sprechen, erkennt das System die Stimme über SenseVoice, MiniCPM-o generiert die Antwort und CosyVoice wandelt sie in Sprachausgabe um. Der Digitalisierer synchronisiert den Ausdruck und die Mundform. Tests zeigen eine Antwortlatenz von etwa 2,2 Sekunden (basierend auf i9-13900KF und RTX 4090). - Anpassen der Konfiguration
Compilerconfigs/sample.yamlDokumentation. Beispiel: - Ändern Sie den Anschluss: Setzen Sie den
service.portAuf einen anderen Wert ändern. - Einstellen der Bildrate: einstellen
Tts2Face.fpsAuf 30 einstellen.
Speichern Sie und starten Sie das Programm neu, damit die Konfiguration wirksam wird.
Arbeitsablauf
- Starten Sie das Programm und warten Sie, bis die Schnittstelle fertig geladen ist.
- Überprüfen Sie, ob die Kamera und das Mikrofon ordnungsgemäß funktionieren.
- Starten Sie einen Dialog und das System verarbeitet automatisch die Sprach- und Videodaten.
- Um zu beenden, drücken Sie Strg+C, um das Terminal zu schließen oder die Schnittstelle zu verlassen.
Cloud-basierte Alternativen
Wenn die lokale Konfiguration nicht ausreicht, können Sie MiniCPM-o durch einen Cloud-LLM ersetzen:
- Änderungen
src/demo.pyUm die ASR-, LLM- und TTS-Prozessoren zu aktivieren, beachten Sie den Abschnitt MiniCPM. - existieren
configs/sample.yamlkonfigurieren.LLM_Bailiangeben Sie die API-Adresse und den Schlüssel ein, zum Beispiel:
LLM_Bailian:
model_name: "qwen-plus"
api_url: "https://dashscope.aliyuncs.com/compatible-mode/v1"
api_key: "yourapikey"
- Starten Sie das Programm neu, um es zu verwenden.
caveat
- Unzureichender GPU-Speicher kann zum Absturz der Anwendung führen. Es wird empfohlen, das int4-Modell oder die Cloud-API zu verwenden.
- Ein instabiles Netzwerk beeinträchtigt die Echtzeit-Übertragung, daher wird eine kabelgebundene Verbindung empfohlen.
- Konfigurationspfade unterstützen relative Pfade (basierend auf dem Stammverzeichnis des Projekts) oder absolute Pfade.
Anwendungsszenario
- Technische Studien
Entwickler können damit Techniken des digitalen menschlichen Dialogs studieren und die Umsetzung modularer Designs analysieren. - persönlicher Test
Die Nutzer können lokale Dienste aufbauen und sprachgesteuerte digitale menschliche Interaktion erleben. - Bildung und Ausbildung
Die Studierenden können die Grundsätze der Spracherkennung, der Sprachmodellierung und der digitalen menschlichen Animation durch Code erlernen.
QA
- Was ist, wenn ich nicht genügend Videospeicher habe?
Laden Sie das quantitative Modell von int4 herunter, oder verwenden Sie anstelle eines lokalen Modells die cloudbasierte LLM-API. - Unterstützt es Multiplayer-Dialoge?
Die aktuelle Version ist für Einzelspieler-Dialoge geeignet, Mehrspieler-Funktionen müssen selbst entwickelt werden. - Was ist mit der Verzögerung beim Laufen?
Prüfen Sie die CPU/GPU-Leistung, reduzieren Sie die Bildrate oder schalten Sie den Schnellmodus aus.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...