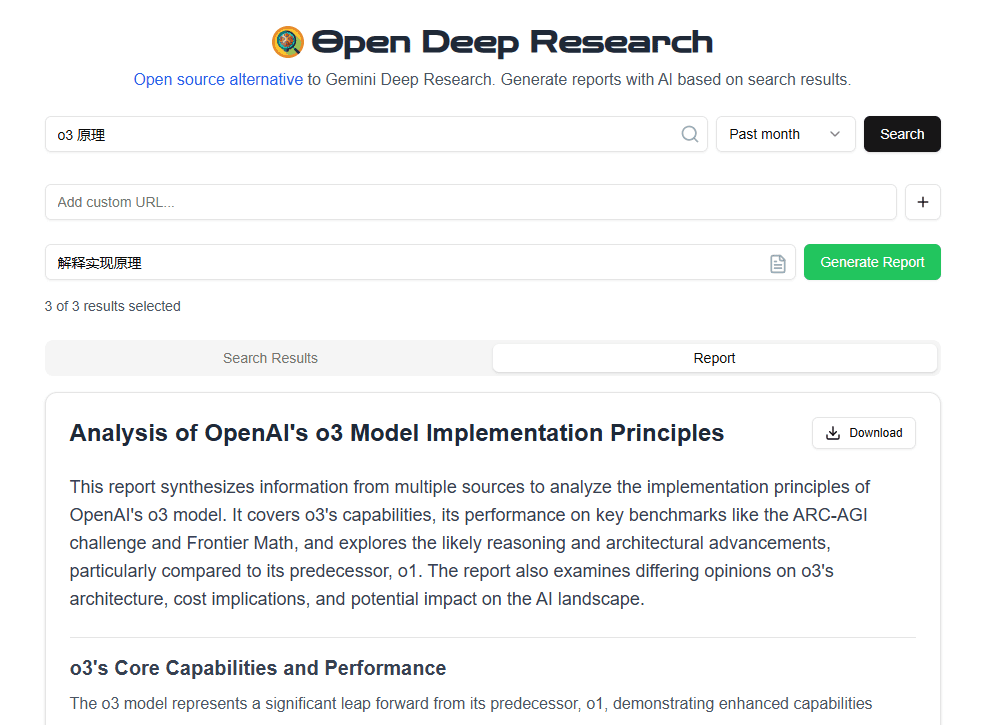
MM-EUREKA: Ein multimodales Reinforcement Learning Tool zur Erforschung des visuellen Denkens

Allgemeine Einführung
MM-EUREKA ist ein Open-Source-Projekt, das vom Shanghai Artificial Intelligence Laboratory der Shanghai Jiao Tong University und anderen Parteien entwickelt wurde. Es erweitert die Fähigkeiten des textuellen Reasonings auf multimodale Szenarien durch regelbasierte Verstärkungslerntechniken, um Modelle bei der Verarbeitung von Bild- und Textinformationen zu unterstützen. Das Hauptziel dieses Tools ist es, die Leistung von Modellen bei visuellen und mathematischen Schlussfolgerungen zu verbessern. Es stellt zwei Hauptmodelle vor, MM-Eureka-8B und MM-Eureka-Zero-38B, die ein effizientes Training mit kleinen Datenmengen ermöglichen, z. B. mit nur 54K grafischen Daten, um andere Modelle zu übertreffen, die Millionen von Daten benötigen. Das Projekt ist vollständig quelloffen, und der Code, die Modelle und die Daten sind für Forscher und Entwickler, die multimodale Inferenztechniken erforschen, auf GitHub frei verfügbar.

Funktionsliste
- Unterstützung des multimodalen Denkens: Die Fähigkeit, Bilder und Text gleichzeitig zu verarbeiten, verbessert die Fähigkeit des Modells, komplexe Probleme zu verstehen.
- Regelbasiertes Verstärkungslernen: Training von Modellen mit einfachen Regeln, um die Abhängigkeit von großen Datenmengen zu verringern.
- Visuelle Epiphanien: Modelle können bei ihren Überlegungen auf Bildhinweise zurückgreifen und so den Prozess der menschlichen Reflexion nachahmen.
- Open Source Complete Pipeline: stellt Code, Datensätze und Trainingsablauf zur einfachen Reproduktion und Verbesserung zur Verfügung.
- Hohe Dateneffizienz: Die Leistung ist vergleichbar mit Modellen, die auf Millionen von Daten mit kleinen Datenmengen (z. B. 8K oder 54K Grafikpaare) trainiert wurden.
- Unterstützung des mathematischen Denkens: speziell optimiert für das Lösen mathematischer Probleme in schulischen und akademischen Szenarien.
Hilfe verwenden
MM-EUREKA ist ein Open-Source-Projekt auf GitHub, das sich vor allem an Nutzer mit einer gewissen Programmierkenntnis richtet, insbesondere an Forscher und Entwickler. Im Folgenden wird detailliert beschrieben, wie dieses Tool zu installieren und zu verwenden ist, einschließlich der wichtigsten Merkmale des eigentlichen Betriebsprozesses.
Einbauverfahren
- Vorbereiten der Umgebung
- Stellen Sie sicher, dass Sie Python 3.8 oder höher auf Ihrem Computer installiert haben. Dies können Sie mit dem Befehl
python --versionPrüfen. - Um Ihren Code zu klonen, müssen Sie Git installieren. Wenn Sie Git nicht haben, können Sie es von der offiziellen Website herunterladen und installieren.
- Empfohlen für Linux-Systeme (z. B. Ubuntu 20.04 oder 22.04), Windows-Benutzer benötigen möglicherweise eine zusätzliche Konfiguration.
- Stellen Sie sicher, dass Sie Python 3.8 oder höher auf Ihrem Computer installiert haben. Dies können Sie mit dem Befehl
- Projektcode klonen
- Öffnen Sie ein Terminal und geben Sie den folgenden Befehl ein, um den MM-EUREKA-Quellcode herunterzuladen:
git clone https://github.com/ModalMinds/MM-EUREKA.git - Sobald der Download abgeschlossen ist, wechseln Sie in den Projektordner:
cd MM-EUREKA
- Öffnen Sie ein Terminal und geben Sie den folgenden Befehl ein, um den MM-EUREKA-Quellcode herunterzuladen:
- Installation von Abhängigkeiten
- Führen Sie den folgenden Befehl aus, um die grundlegenden Abhängigkeiten zu installieren:
pip install -e . - Wenn Sie die vLLM Accelerated Reasoning und zusätzliche Pakete müssen installiert werden:
pip install -e .[vllm] - Installieren Sie Flash-Attention (Version 2.3.6), um die Leistung zu verbessern:
pip install flash-attn==2.3.6 --no-build-isolationWenn Sie Probleme haben, versuchen Sie die Installation von der Quelle aus:
git clone https://github.com/Dao-AILab/flash-attention.git cd flash-attention git checkout v2.3.6 python setup.py install
- Führen Sie den folgenden Befehl aus, um die grundlegenden Abhängigkeiten zu installieren:
- Datensatz herunterladen
- Das Projekt stellt Trainingsdaten MM-Eureka-Dataset zur Verfügung, die von GitHub Releases heruntergeladen werden können.
- Nach dem Herunterladen entpacken Sie die Datei und ändern die Daten nach Bedarf in der
image_urlsFeld, das auf den lokalen Bildpfad verweist.
- Überprüfen der Installation
- Nachdem die Installation abgeschlossen ist, führen Sie
python -c "import mm_eureka"Überprüfen Sie, ob Fehler gemeldet werden. Wenn es keine Fehler gibt, war die Installation erfolgreich.
- Nachdem die Installation abgeschlossen ist, führen Sie
Verwendung der Hauptfunktionen
Funktion 1: Ausführen eines multimodalen Inferenzmodells
- Daten vorbereiten
- Die Daten müssen im JSONL-Format organisiert werden, wobei jede Zeile ein Wörterbuch ist, das
idundconversationsundanswerim Gesang antwortenimage_urlsFelder. Beispiel:{"id": "0", "conversations": [{"role": "user", "content": "这张图里的数学题答案是什么?"}], "answer": "42", "image_urls": ["file:///path/to/image.jpg"]} - Speichern Sie die Daten als
dataset.jsonlin das Projektverzeichnis gelegt.
- Die Daten müssen im JSONL-Format organisiert werden, wobei jede Zeile ein Wörterbuch ist, das
- logische Schlussfolgerung
- Geben Sie den folgenden Befehl in das Terminal ein, um das Modell zu laden und darüber nachzudenken:
python scripts/inference.py --model MM-Eureka-8B --data dataset.jsonl - Die Ausgabe zeigt den Argumentationsprozess des Modells und die Antworten auf jede Frage.
- Geben Sie den folgenden Befehl in das Terminal ein, um das Modell zu laden und darüber nachzudenken:
Funktion 2: Training benutzerdefinierter Modelle
- Konfigurieren Sie die Trainingsparameter
- zeigen (eine Eintrittskarte)
config.yamlDatei, um Modellparameter (z. B. Lernrate, Stapelgröße) und Datenpfade festzulegen. - sicher
data_pathRichte es auf dich.dataset.jsonlDokumentation.
- zeigen (eine Eintrittskarte)
- Grundlagentraining
- Führen Sie den folgenden Befehl aus, um das Training zu starten:
python scripts/train.py --config config.yaml - Während des Trainings speichert das Modell Kontrollpunkte in der
checkpoints/Mappe.
- Führen Sie den folgenden Befehl aus, um das Training zu starten:
Funktion 3: Testen visueller Epiphanien
- Vorbereiten der Testdaten
- Verwenden Sie Daten aus komplexen Mathematikaufgaben, die Bilder enthalten, wie z. B. einige Fragen aus dem K12-Datensatz.
- Einsatzprüfung
- Geben Sie den Befehl ein:
python scripts/test_reflection.py --model MM-Eureka-Zero-38B --data test.jsonl - Das Modell wird den Denkprozess aufzeigen, einschließlich der Überprüfung der Bildhinweise.
- Geben Sie den Befehl ein:
Beispiel für einen operativen Prozess: Lösen von Matheaufgaben
- Daten hochladen
- Bereiten Sie ein Bild (z. B. ein Geometrieproblem) und eine entsprechende Problembeschreibung vor, die im JSONL-Format gespeichert werden.
- Betriebsmodell
- Kosten oder Aufwand
inference.pyDas Skript lädt MM-Eureka-8B und gibt die Daten ein.
- Kosten oder Aufwand
- Ergebnisse anzeigen
- Das Modell gibt den Inferenzschritt (
<think>Tags) und die endgültige Antwort (<answer>Tags), zum Beispiel:<think>先看图,圆的半径是 5,面积公式是 πr²,所以是 25π。</think> <answer>25π</answer>
- Das Modell gibt den Inferenzschritt (
caveat
- Wenn der GPU-Speicher nicht ausreicht, passen Sie die Losgröße an oder verwenden Sie MM-Eureka-8B (kleineres Modell).
- Die Bildpfade in den Daten müssen gültig sein, sonst kann das Modell das Bild nicht verarbeiten.
Mit diesen Schritten können Sie ganz einfach mit MM-EUREKA beginnen und seine multimodalen Argumentationsfähigkeiten erleben.
Anwendungsszenario
- Pädagogische Hilfsmittel
MM-EUREKA analysiert Bilder von mathematischen Problemen und gibt detaillierte Lösungen, die sich für Schülerübungen oder die Vorbereitung von Lehrern eignen. - Wissenschaftliche Erkundung
Forscher können damit die Wirksamkeit von Reinforcement Learning bei multimodalen Aufgaben testen, Algorithmen verbessern oder neue Modelle entwickeln. - AR/VR-Entwicklung
Entwickler können die visuellen Argumentationsfähigkeiten nutzen, um intelligentere interaktive Anwendungen zu entwickeln, z. B. Assistenten für die Problemlösung in Echtzeit.
QA
- Welche Sprachen werden von MM-EUREKA unterstützt?
Derzeit werden vor allem englische und chinesische Grafikdaten unterstützt, und das Modell hat für diese beiden Sprachen den besten Inferenz-Effekt. - Wie stark muss ein Computer konfiguriert sein?
Es werden mindestens 16 GB RAM und eine Mittelklasse-GPU (z. B. NVIDIA GTX 1660) empfohlen. Für das Training großer Modelle kann eine leistungsfähigere Hardware erforderlich sein. - Wie kann ich Code beisteuern?
Um einen Pull Request auf GitHub einzureichen, lesen Sie dieCONTRIBUTING.mdDie Leitlinien des Dokuments.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...