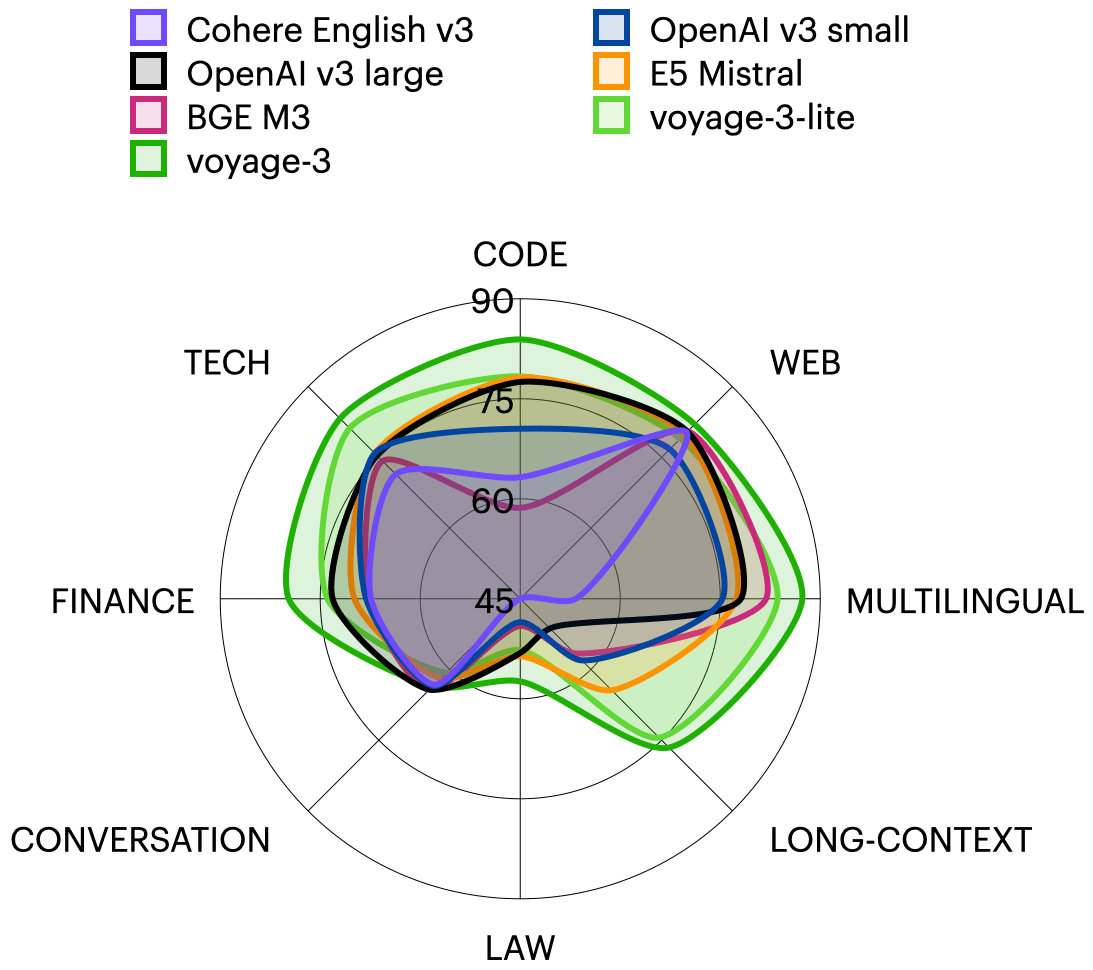
LongBench v2: Auswertung von Langtext +o1?

Evaluierung von Big Models für 'Deep Understanding and Reasoning' in der realen Welt, lange Texte, Multi-Tasks
In den letzten Jahren wurden erhebliche Fortschritte bei der Untersuchung großer Sprachmodelle für lange Texte erzielt, wobei die Länge des Kontextfensters der Modelle von ursprünglich 8k auf 128k oder sogar 1M Token erweitert wurde. Eine Schlüsselfrage bleibt jedoch bestehen: Verstehen diese Modelle wirklich die langen Texte, mit denen sie zu tun haben? Mit anderen Worten, sind sie in der Lage, die Informationen in langen Texten zu verstehen, zu lernen und tiefgreifende Schlussfolgerungen zu ziehen?
Um diese Frage zu beantworten und die Weiterentwicklung von Langtextmodellen für tiefes Verstehen und schlussfolgerndes Denken voranzutreiben, hat ein Team von Forschern der Tsinghua Universität und Smart Spectrum LongBench v2 ins Leben gerufen, einen Benchmark-Test, der die Fähigkeiten von LLMs für tiefes Verstehen und schlussfolgerndes Denken in realem Langtext-Multitasking bewerten soll.
Wir glauben, dass LongBench v2 die Erforschung der Frage vorantreiben wird, wie die Skalierung der Inferenzzeitberechnung (z.B. das o1-Modell) helfen kann, tiefgreifende Verständnis- und Inferenzprobleme in Szenarien mit langen Texten zu lösen.
Besonderheiten
LongBench v2 weist gegenüber den bestehenden Benchmarks für das Verstehen langer Texte mehrere wichtige Merkmale auf:
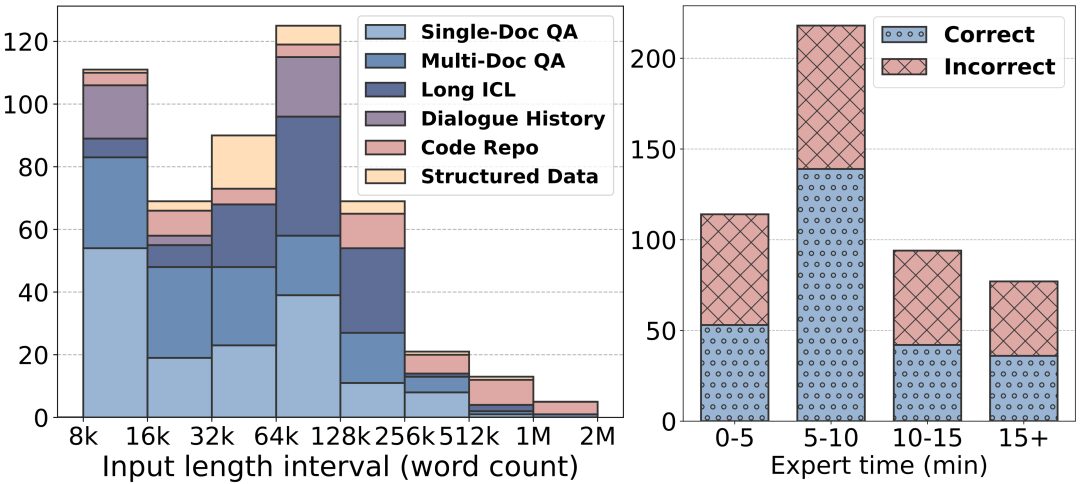
Größere Textlängen: Die Textlängen von LongBench v2 reichen von 8k bis 2M Wörter, wobei die meisten Texte weniger als 128k lang sind.
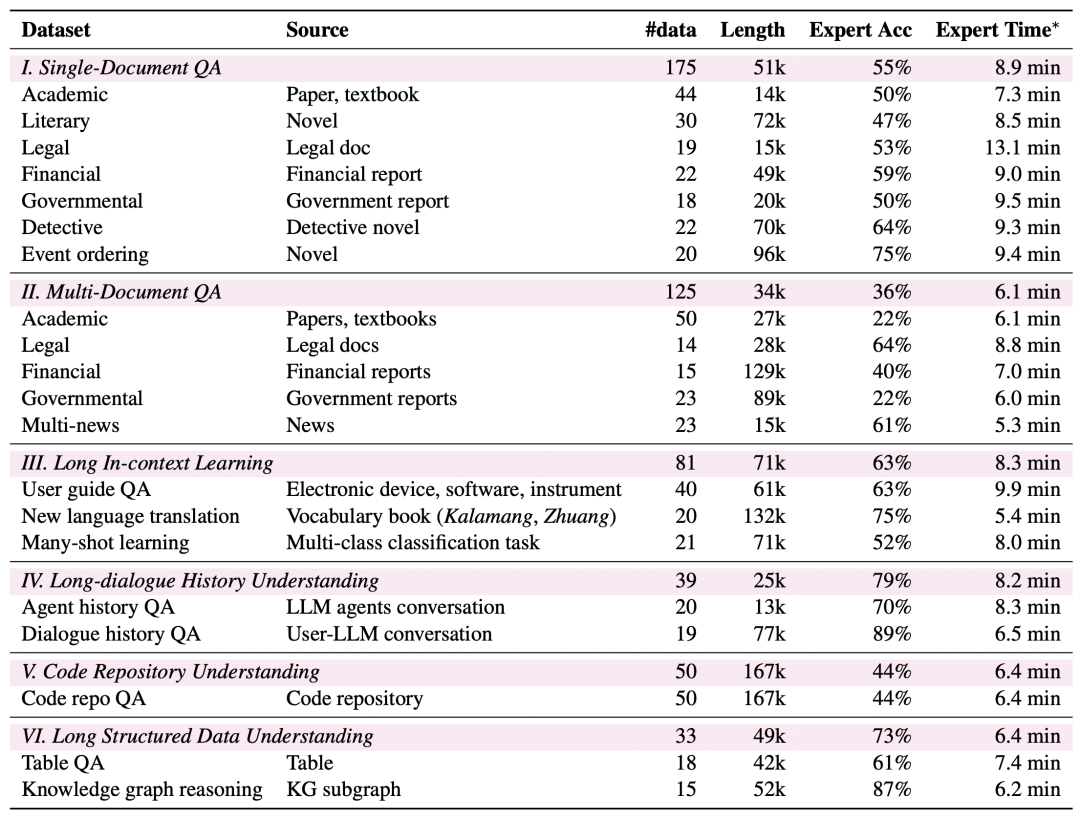
Höherer Schwierigkeitsgrad: LongBench v2 enthält 503 anspruchsvolle Vier-Choice-Multiple-Choice-Fragen - Fragen, die selbst menschliche Experten, die das Tool zur Dokumentensuche verwenden, nur schwer in kurzer Zeit richtig beantworten könnten. Menschliche Experten erreichten im Durchschnitt nur 53,71 TP3T Genauigkeit innerhalb des 15-Minuten-Zeitlimits (251 TP3T nach dem Zufallsprinzip).
Breiteres Aufgabenspektrum: LongBench v2 deckt sechs Hauptaufgabenkategorien ab, darunter Quizfragen zu einzelnen Dokumenten, Quizfragen zu mehreren Dokumenten, Lernen von langen Textkontexten, Verstehen von langen Dialogverläufen, Verstehen von Code-Repositories und Verstehen von langen strukturierten Daten, mit insgesamt 20 Teilaufgaben, die eine Vielzahl von realen Szenarien abdecken.
Höhere Zuverlässigkeit: Um die Zuverlässigkeit der Bewertung zu gewährleisten, sind alle Fragen in LongBench v2 im Multiple-Choice-Format und werden einem strengen manuellen Beschriftungs- und Überprüfungsprozess unterzogen, um die hohe Qualität der Daten sicherzustellen.
Prozess der Datenerhebung
Um die Qualität und den Schwierigkeitsgrad der Daten zu gewährleisten, wendet LongBench v2 ein strenges Datenerfassungsverfahren an, das aus den folgenden Schritten besteht:
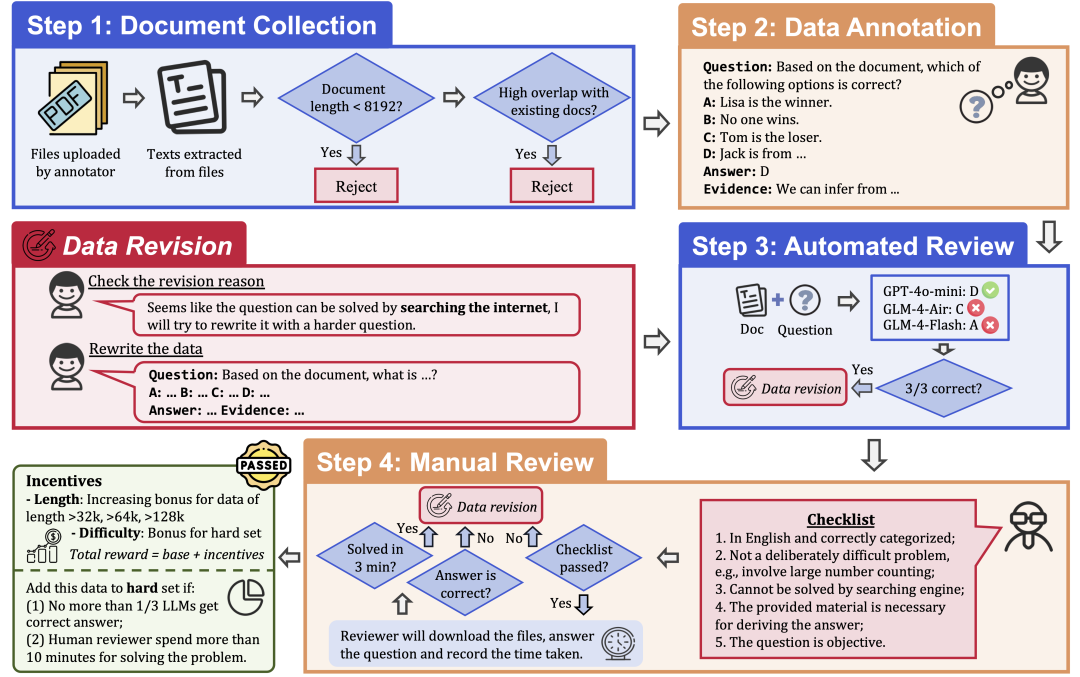
Dokumentensammlung: Rekrutieren Sie 97 Kommentatoren von Spitzenuniversitäten mit unterschiedlichen akademischen Hintergründen und Noten, um lange Dokumente zu sammeln, die sie persönlich gelesen oder verwendet haben, z. B. Forschungsarbeiten, Lehrbücher, Romane usw.
Kennzeichnung der Daten: Auf der Grundlage der gesammelten Dokumente stellt der Kennzeichner eine Multiple-Choice-Frage mit vier Optionen, einer richtigen Antwort und einem entsprechenden Nachweis.
Automatische Überprüfung: Die kommentierten Daten wurden automatisch mit drei LLMs (GPT-4o-mini, GLM-4-Air und GLM-4-Flash) mit einem 128k-Kontextfenster überprüft. Wenn alle drei Modelle die Frage richtig beantworteten, wurde sie als zu einfach angesehen und musste neu etikettiert werden.
Menschliche Überprüfung: Daten, die die automatische Überprüfung bestehen, werden einer menschlichen Überprüfung durch 24 professionelle menschliche Experten zugewiesen, die versuchen, die Frage zu beantworten und zu bestimmen, ob die Frage angemessen und die Antwort richtig ist. Ist der Experte in der Lage, die Frage innerhalb von drei Minuten richtig zu beantworten, gilt die Frage als zu einfach und muss neu gekennzeichnet werden. Ist der Experte der Ansicht, dass die Frage selbst nicht angemessen oder die Antwort falsch ist, wird sie zur erneuten Bewertung zurückgeschickt.
Datenrevision: Daten, die die Prüfung nicht bestehen, werden zur Überarbeitung an den Kommentator zurückgegeben, bis sie alle Prüfungsschritte bestanden haben.
Bewertungsergebnisse
Das Team bewertete 10 Open-Source-LLMs und 6 Closed-Source-LLMs unter Verwendung von LongBench v2. Bei der Bewertung wurden zwei Szenarien berücksichtigt: Zero-Shot und Zero-Shot+CoT (d.h. das Modell gibt zuerst die Gedankenkette aus und gibt dann die gewählte Antwort aus).
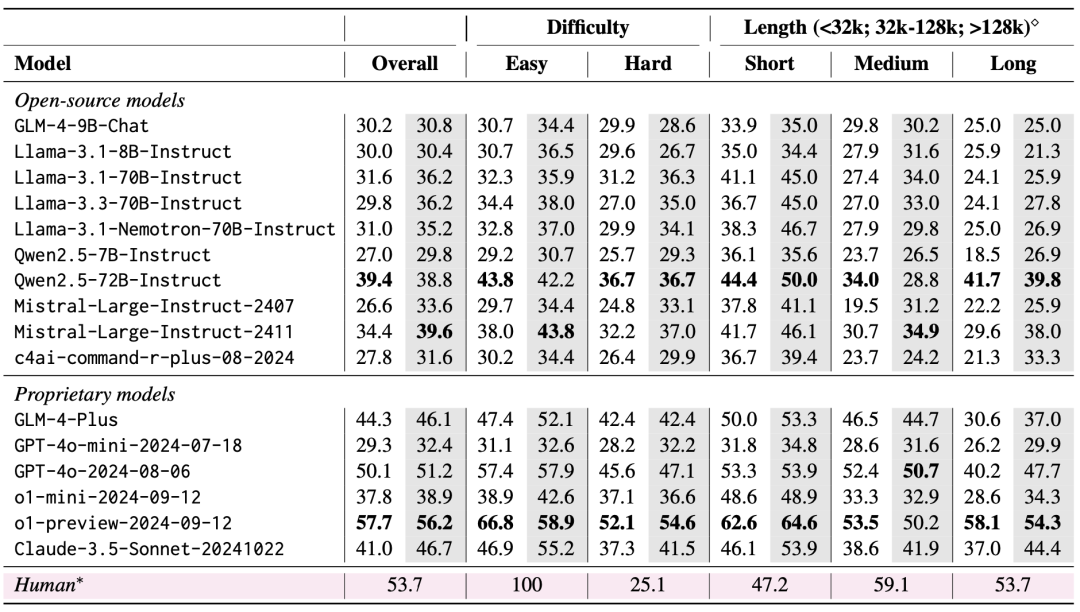
Die Bewertungsergebnisse zeigen, dass LongBench v2 eine große Herausforderung für aktuelle LLMs darstellt, wobei selbst das leistungsstärkste Modell eine Genauigkeit von nur 50,1% mit direkter Antwortausgabe erreicht, während das o1-Preview-Modell, das eine längere Inferenzkette einführt, eine Genauigkeit von 57,7% erreicht, was den menschlichen Experten um 4%.
1. die Bedeutung der Skalierung der Inferenzzeitberechnung
Eine sehr wichtige Erkenntnis aus den Evaluierungsergebnissen ist, dass die Leistung der Modelle auf LongBench v2 durch Scaling Inference-Time Compute deutlich verbessert werden kann. Zum Beispiel erreicht das o1-Preview-Modell signifikante Verbesserungen bei Aufgaben wie Multi-Dokument-Quiz, Lernen von langem Textkontext und Verstehen von Code-Repositories durch die Integration von mehr Inferenzschritten im Vergleich zu GPT-4o.
Dies deutet darauf hin, dass LongBench v2 höhere Anforderungen an die Argumentationsfähigkeiten aktueller Modelle stellt und dass die Erhöhung der Zeit, die für das Nachdenken und Argumentieren über das Argumentieren aufgewendet wird, ein natürlicher und entscheidender Schritt bei der Bewältigung solcher langen textuellen Argumentationsaufgaben zu sein scheint.
2) RAG + Experimente mit langem Kontext

Es zeigt sich, dass beide Modelle, Qwen2.5 und GLM-4-Plus, keine signifikante Leistungsverbesserung oder sogar -verschlechterung aufweisen, sobald die Anzahl der abgerufenen Blöcke einen bestimmten Schwellenwert (32k Token, etwa 64 Blöcke von 512 Länge) überschreitet.
Dies deutet darauf hin, dass eine einfache Vergrößerung der abgerufenen Informationsmenge nicht immer zu einer Leistungssteigerung führt. Im Gegensatz dazu ist GPT-4o in der Lage, längere Abfragekontexte effizient zu nutzen und eine optimale RAG Die Leistung tritt bei einer Abruflänge von 128k auf.
Zusammenfassend lässt sich sagen, dass RAG bei langen textuellen Q&A-Aufgaben, die ein tiefes Verständnis und logisches Denken erfordern, nur von begrenztem Nutzen ist, insbesondere wenn die Anzahl der abgerufenen Blöcke einen bestimmten Schwellenwert überschreitet. Das Modell muss über stärkere Schlussfolgerungsfähigkeiten verfügen, anstatt sich nur auf die abgerufenen Informationen zu verlassen, um die anspruchsvollen Probleme in LongBench v2 effektiv zu lösen.
Dies bedeutet auch, dass künftige Forschungsrichtungen sich mehr darauf konzentrieren müssen, wie das Modell sein eigenes Verständnis von langen Texten und seine Schlussfolgerungen verbessern kann, anstatt sich nur auf externe Abfragen zu verlassen.
Wir erwarten, dass LongBench v2 die Grenzen des Verstehens langer Texte und der Argumentationstechniken erweitern wird. Fühlen Sie sich frei, unser Papier zu lesen, unsere Daten zu nutzen und mehr zu erfahren!
Startseite: https://longbench2.github.io
Diplomarbeit: https://arxiv.org/abs/2412.15204
Daten und Codes: https://github.com/THUDM/LongBench
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...