
Kimi bringt MoBA auf den Markt: ein Durchbruch bei der Ermöglichung von unendlichem Kontext!

Mixture of Experts und Sparse Attention ermöglichen praktisch unbegrenzte Kontexte. Damit kann der RAG-KI-Agent ganze Codebasen und Dokumente ohne kontextuelle Einschränkungen verschlingen.
📌 Die Herausforderung der Aufmerksamkeit bei langen Kontexten
Bei sehr großen Sequenzen sind die Transformatoren nach wie vor sehr rechenaufwändig. Das Standard-Aufmerksamkeitsmodell nimmt jede Token Der Vergleich mit allen anderen Token führt zu einem quadratischen Anstieg der Rechenkosten. Dieser Overhead wird zum Problem, wenn ganze Codebasen, Dokumente mit mehreren Kapiteln oder große Mengen von Rechtstexten gelesen werden.
📌 MoBA
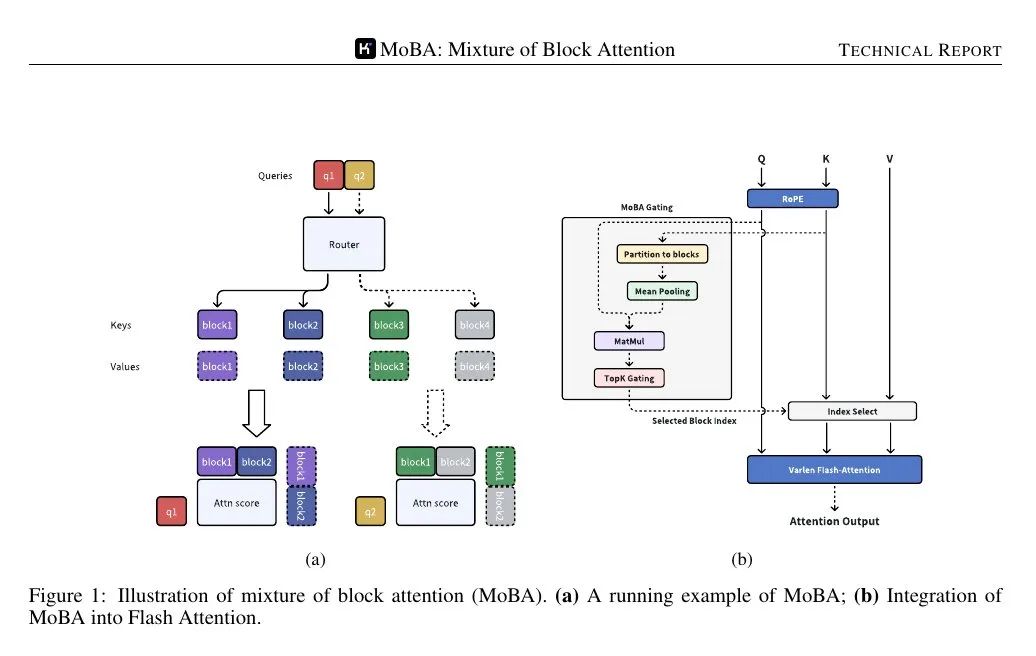
MoBA (Mixture of Block Attention) wendet das Konzept der "Mixture of Experts" auf den Aufmerksamkeitsmechanismus an. Das Modell unterteilt die Eingabesequenz in mehrere Blöcke, und dann berechnet eine trainierbare Gating-Funktion den Korrelationswert zwischen jedem Abfrage-Token und jedem Block. Nur die Blöcke mit den höchsten Korrelationswerten werden in der Aufmerksamkeitsberechnung verwendet, so dass nicht jedes Token in der gesamten Sequenz beachtet werden muss.
Blöcke werden durch Aufteilung der Sequenz in gleiche Abschnitte definiert. Jedes Abfrage-Token betrachtet die aggregierte Darstellung der Schlüssel in jedem Block (z. B. unter Verwendung von Mean-Pooling) und erstellt dann eine Rangfolge ihrer Wichtigkeit, wobei einige Blöcke für eine detaillierte Berechnung der Aufmerksamkeit ausgewählt werden. Der Block, der die Anfrage enthält, wird immer ausgewählt. Die kausale Maskierung stellt sicher, dass die Token keine zukünftigen Informationen sehen, so dass die Generierungsreihenfolge von links nach rechts eingehalten wird.
📌 Nahtloser Wechsel zwischen spärlicher und voller Aufmerksamkeit
MoBA ersetzt den standardmäßigen Aufmerksamkeitsmechanismus, ändert aber nicht die Anzahl der Parameter. Er ist ähnlich wie der Standard Transformator Die Schnittstellen sind kompatibel, so dass die spärliche und die volle Aufmerksamkeit zwischen verschiedenen Schichten oder Trainingsphasen umgeschaltet werden kann. Einige Schichten können die volle Aufmerksamkeit für bestimmte Aufgaben reservieren (z. B. überwachte Feinabstimmung), während die meisten Schichten MoBA verwenden, um die Rechenkosten zu senken.
📌 Dies gilt für größere Transformer-Stapel, indem die Standard-Attention-Aufrufe ersetzt werden. Der Gating-Mechanismus stellt sicher, dass sich jede Abfrage nur auf eine kleine Anzahl von Blöcken konzentriert. Die Kausalität wird behandelt, indem zukünftige Blöcke herausgefiltert werden und eine lokale Maske innerhalb des aktuellen Blocks der Abfrage angewendet wird.
📌 Die folgende Abbildung zeigt, dass die Abfrage nur an einige "Experten"-Blöcke von Schlüsseln/Werten geleitet wird, nicht an die gesamte Sequenz. Der Gating-Mechanismus ordnet jede Abfrage dem relevantesten Block zu, wodurch die Komplexität der Aufmerksamkeitsberechnung von quadratisch auf subquadratisch reduziert wird.
📌 Der Gating-Mechanismus berechnet einen Korrelationswert zwischen jeder Abfrage und der kohäsiven Darstellung jedes Blocks. Anschließend werden für jede Abfrage die obersten k Blöcke mit der höchsten Punktzahl ausgewählt, unabhängig davon, wie weit hinten sie in der Sequenz liegen.
Da nur wenige Blöcke pro Abfrage verarbeitet werden, ist die Berechnung immer noch subquadratisch, aber das Modell kann trotzdem zu Token springen, die weit vom aktuellen Block entfernt sind, wenn der Gating Score eine hohe Korrelation aufweist.
PyTorch-Implementierung
Dieser Pseudocode unterteilt die Schlüssel und Werte in Blöcke, berechnet eine mittlere gepoolte Darstellung jedes Blocks und berechnet den Gating Score (S) durch Multiplikation der Abfrage (Q) mit der gepoolten Darstellung.
Es wendet dann kausale Masken an, um sicherzustellen, dass sich Abfragen nicht auf zukünftige Blöcke konzentrieren können, verwendet den Top-k-Operator, um die relevantesten Blöcke für jede Abfrage auszuwählen, und organisiert die Daten für eine effiziente Berechnung der Aufmerksamkeit.
📌 FlashAttention wurden auf den selbst-aufmerksamen Block (aktuelle Position) bzw. den MoBA-ausgewählten Block angewandt, und schließlich wurden die Ausgaben mit Online-Softmax zusammengeführt.
Das Endergebnis ist ein spärlicher Aufmerksamkeitsmechanismus, der die kausale Struktur bewahrt und weitreichende Abhängigkeiten erfasst und gleichzeitig die vollen quadratischen Rechenkosten der Standardaufmerksamkeit vermeidet.

Dieser Code kombiniert die Logik der Expertenmischung mit spärlicher Aufmerksamkeit, so dass sich jede Abfrage nur auf einige wenige Blöcke konzentriert.
Der Gating-Mechanismus bewertet jeden Block und jede Abfrage und wählt die besten k "Experten" aus, wodurch die Anzahl der Schlüssel/Wert-Vergleiche reduziert wird.
Dadurch wird der Rechenaufwand der Aufmerksamkeit auf einem subquadratischen Niveau gehalten, so dass extrem lange Eingaben verarbeitet werden können, ohne dass der Rechen- oder Speicheraufwand steigt.
Gleichzeitig stellt der Gating-Mechanismus sicher, dass sich die Abfrage bei Bedarf immer noch auf entfernte Token konzentrieren kann, so dass die Fähigkeit des Transformers, den globalen Kontext zu verarbeiten, erhalten bleibt.
Diese block- und gating-basierte Strategie ist genau die Art und Weise, wie MoBA nahezu unendliche Kontexte in LLM implementiert.

Experimentelle Beobachtungen
Modelle, die MoBA verwenden, sind in Bezug auf den Verlust bei der Sprachmodellierung und die nachgelagerte Aufgabenleistung fast mit der vollen Aufmerksamkeit vergleichbar. Die Ergebnisse bleiben auch bei Kontextlängen von Hunderttausenden oder Millionen von Token konsistent. Experimente, die mit "tail tokens" ausgewertet wurden, bestätigen, dass wichtige weitreichende Abhängigkeiten immer noch erfasst werden, wenn die Abfrage relevante Chunks identifiziert.
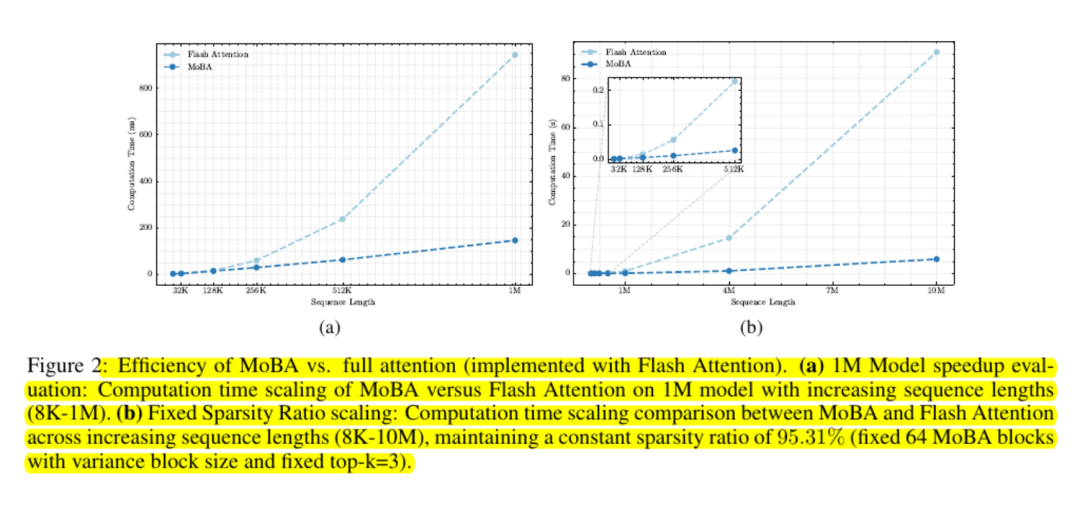
Skalierungstests zeigen, dass seine Kostenkurve subquadratisch ist. Die Forscher berichten von Geschwindigkeitssteigerungen von bis zu sechs Mal bei einer Million Token und größeren Gewinnen außerhalb dieses Bereichs.
MoBA ist speicherfreundlich, da es die Verwendung vollständiger Aufmerksamkeitsmatrizen vermeidet und Standard-GPU-Kernel für blockbasierte Berechnungen verwendet.
Abschließende Beobachtungen
MoBA reduziert den Aufmerksamkeits-Overhead durch eine einfache Idee: Die Abfrage soll lernen, welche Blöcke wichtig sind und alle anderen ignorieren.
Es bewahrt die standardmäßige Softmax-basierte Aufmerksamkeitsschnittstelle und vermeidet die Erzwingung eines starren lokalen Modells. Viele große Sprachmodelle können diesen Mechanismus im Plug-and-Play-Verfahren integrieren.
Dies macht MoBA sehr attraktiv für Arbeitslasten, die mit extrem langen Kontexten umgehen müssen, wie z.B. das Scannen einer gesamten Codebasis oder das Zusammenfassen großer Dokumente, ohne dass größere Änderungen an den Pre-Training-Gewichten vorgenommen werden müssen oder ein großer Re-Training-Overhead anfällt.

© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Verwandte Beiträge



Keine Kommentare...