Ilya Sutskever explodiert bei NeurIPS und erklärt: Pre-Training wird beendet, die Datenknappheit hat ein Ende

Vernunft ist unberechenbar, also müssen wir mit unglaublichen, unberechenbaren KI-Systemen beginnen.
Ilya ist endlich aufgetaucht, und er hat gleich etwas Erstaunliches zu sagen. Am Freitag sagte Ilya Sutskever, der ehemalige Chefwissenschaftler von OpenAI, auf dem Global AI Summit, dass "wir das Ende der Daten erreicht haben, die wir bekommen können, und dass es keine weiteren mehr geben wird". 
Ilya Sutskever, Mitbegründer und ehemaliger Chefwissenschaftler von OpenAI, sorgte für Schlagzeilen, als er das Unternehmen im Mai dieses Jahres verließ, um sein eigenes KI-Labor, Safe Superintelligence, zu gründen. Seit seinem Weggang von OpenAI hat er sich von den Medien ferngehalten. Diesen Freitag hatte er jedoch einen seltenen öffentlichen Auftritt auf der NeurIPS 2024, einer Konferenz über neuronale Informationsverarbeitungssysteme in Vancouver.
"Das Vortraining, wie wir es kennen, wird zweifellos zu Ende gehen", sagte Sutskever auf der Bühne.
Im Bereich der künstlichen Intelligenz haben groß angelegte Vortrainingsmodelle wie BERT und GPT in den letzten Jahren große Erfolge erzielt und sind zu einem Meilenstein auf dem Weg des technologischen Fortschritts geworden.
Aufgrund der komplexen Ziele des Pre-Trainings und der großen Modellparameter kann das Pre-Training in großem Maßstab effizient Wissen aus einer großen Menge von gekennzeichneten und nicht gekennzeichneten Daten erfassen. Durch die Speicherung von Wissen in riesigen Parametern und deren Feinabstimmung für eine bestimmte Aufgabe kann das in den riesigen Parametern implizit kodierte umfangreiche Wissen einer Vielzahl von nachgelagerten Aufgaben zugute kommen. In der KI-Gemeinschaft besteht inzwischen ein Konsens darüber, das Pre-Training als Grundlage für nachgelagerte Aufgaben zu verwenden, anstatt Modelle von Grund auf neu zu lernen. 
In seinem NeurIPS-Vortrag sagte Ilya Sutskever jedoch, dass vorhandene Daten zwar immer noch die KI vorantreiben können, der Branche aber bald die neuen Daten ausgehen werden, die sie als brauchbar bezeichnen kann. Er merkte an, dass dieser Trend die Branche schließlich dazu zwingen wird, die Art und Weise zu ändern, wie Modelle derzeit trainiert werden.
Sutskever vergleicht die Situation mit der Erschöpfung fossiler Brennstoffe: So wie Öl eine endliche Ressource ist, so ist es auch mit den von Menschen erstellten Inhalten im Internet.
"Wir haben den Höhepunkt der Datenmenge erreicht, und es kommen keine weiteren Daten mehr hinzu", sagte Sutskever. "Wir müssen die verfügbaren Daten nutzen, denn es gibt nur ein Internet.
Sutskever sagt voraus, dass die nächste Generation von Modellen "echte Autonomie zeigen wird". Andererseits ist der Begriff "Agent" zu einem Schlagwort in der KI geworden.
Er erwähnte, dass künftige Systeme nicht nur "autonom" sein werden, sondern auch die Fähigkeit haben werden, zu denken. Im Gegensatz zur heutigen KI, die sich stark auf den Abgleich von Mustern stützt (auf der Grundlage dessen, was das Modell zuvor gesehen hat), werden künftige KI-Systeme in der Lage sein, Probleme Schritt für Schritt zu lösen, ähnlich wie beim "Denken".
Sutskever sagt, je mehr ein System denken kann, desto "unvorhersehbarer" wird sein Verhalten. Er vergleicht die Unvorhersehbarkeit von "Systemen mit echter Denkleistung" mit der Leistung fortgeschrittener KI beim Schach - "selbst die besten menschlichen Spieler können ihre Züge nicht vorhersagen".
Diese Systeme werden in der Lage sein, Dinge aus begrenzten Daten zu verstehen und nicht durcheinander zu kommen", sagte er.
In seinem Vortrag verglich er Scaling in KI-Systemen mit der Evolutionsbiologie und verwies auf die Beziehung zwischen dem Verhältnis von Gehirn zu Körpergewicht zwischen verschiedenen Arten in der Studie. Er wies darauf hin, dass die meisten Säugetiere einem bestimmten Skalierungsmuster folgen, während die menschliche Familie (die Vorfahren des Menschen) einen ganz anderen Trend des Wachstums des Verhältnisses von Gehirn zu Körper auf einer logarithmischen Skala aufweist.
Sutskever schlägt vor, dass, so wie die Evolution ein neues Skalierungsparadigma für das menschliche wissenschaftliche Gehirn gefunden hat, die KI über die bestehenden Pre-Training-Methoden hinausgehen und völlig neue Skalierungswege entdecken könnte. Nachfolgend finden Sie den vollständigen Text von Ilya Sutskevers Vortrag: 
Ich möchte den Organisatoren der Konferenz dafür danken, dass sie eine Arbeit für diesen Preis ausgewählt haben (die Arbeit Seq2Seq von Ilya Sutskever et al. wurde für den NeurIPS 2024 Time Check Award ausgewählt). Das ist großartig. Ich möchte mich auch bei meinen unglaublichen Co-Autoren Oriol Vinyals und Quoc V. Le bedanken, die direkt vor Ihnen stehen. 

Sie haben hier ein Bild, einen Screenshot. Es gab einen ähnlichen Vortrag auf der NIPS 2014 in Montreal vor 10 Jahren. Es war eine viel unschuldigere Zeit. Hier sind wir auf dem Foto zu sehen. Das war übrigens das letzte Mal, das unten ist dieses Mal.
Jetzt haben wir mehr Erfahrung und sind hoffentlich ein wenig weiser geworden. Aber hier möchte ich ein wenig über die Übung selbst sprechen und vielleicht einen 10-Jahres-Rückblick machen, denn viele Dinge in der Übung waren richtig, aber einige waren nicht ganz richtig. Wir können darauf zurückblicken und sehen, was passiert ist und wie es uns dorthin gebracht hat, wo wir heute stehen. Lassen Sie uns also darüber reden, was wir getan haben. Als Erstes werden wir Folien derselben Präsentation von vor 10 Jahren zeigen. Sie ist in drei Hauptpunkten zusammengefasst. Ein autoregressives Modell, das auf Text trainiert wurde, ein großes neuronales Netz, ein großer Datensatz, und das war's.
Lassen Sie uns also darüber reden, was wir getan haben. Als Erstes werden wir Folien derselben Präsentation von vor 10 Jahren zeigen. Sie ist in drei Hauptpunkten zusammengefasst. Ein autoregressives Modell, das auf Text trainiert wurde, ein großes neuronales Netz, ein großer Datensatz, und das war's.
Lassen Sie uns nun einige weitere Details erörtern. 
Hier ist eine Folie von vor 10 Jahren, die gut aussieht, "The Deep Learning Hypothesis". Was wir damit sagen wollen, ist, dass ein großes neuronales Netzwerk mit 10 Schichten alles tun kann, was ein Mensch in einem Bruchteil einer Sekunde tun kann. Warum betonen wir, "was Menschen in einem Bruchteil einer Sekunde tun können"? Warum diese Sache?
Warum betonen wir, "was Menschen in einem Bruchteil einer Sekunde tun können"? Warum diese Sache?
Nun, wenn man an das Dogma des Deep Learning glaubt, dass künstliche Neuronen biologischen Neuronen ähneln oder sich zumindest nicht allzu sehr unterscheiden, und wenn man glaubt, dass drei echte Neuronen langsam sind, dann kann der Mensch alles schnell verarbeiten. Ich meine sogar, wenn es nur einen Menschen auf der Welt gäbe. Wenn ein Mensch auf der Welt etwas in einem Bruchteil einer Sekunde erledigen kann, dann kann das auch ein neuronales Netzwerk mit 10 Schichten, oder?
Anschließend bettet man ihre Verbindungen einfach in ein künstliches neuronales Netz ein.
Es geht nur um Motivation. Alles, was ein Mensch in einem Bruchteil einer Sekunde erledigen kann, kann auch ein neuronales Netz mit 10 Schichten.
Wir konzentrierten uns auf neuronale Netze mit 10 Schichten, weil wir damals wussten, wie man sie trainiert, und wenn man irgendwie über diese Anzahl von Schichten hinausgehen konnte, dann konnte man mehr tun. Damals konnten wir aber nur 10 Schichten trainieren, weshalb wir uns auf alles konzentrierten, was ein Mensch in einem Bruchteil einer Sekunde tun kann.
Die andere Folie aus jenem Jahr veranschaulicht unseren Hauptgedanken, dass man vielleicht zwei Dinge erkennen kann, oder zumindest eines, dass hier eine Autoregression stattfindet. 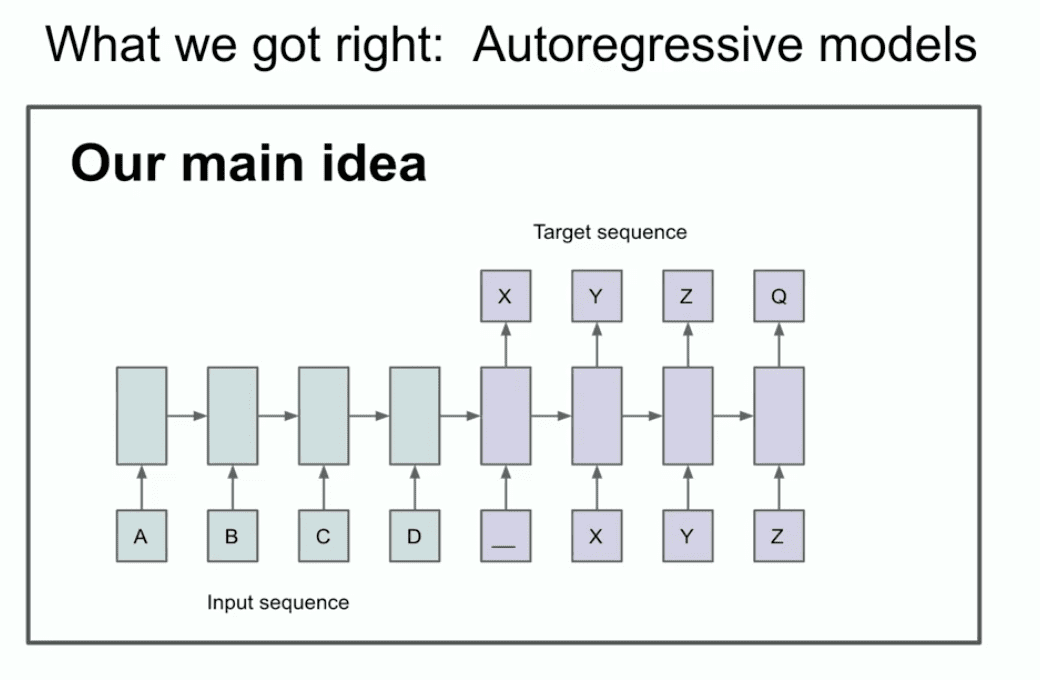
Was zum Teufel steht da? Was sagt diese Folie eigentlich aus? Diese Folie besagt, dass, wenn Sie ein autoregressives Modell haben und es die nächste Token gut genug ist, dann wird es tatsächlich die richtige Verteilung der als nächstes erscheinenden Sequenz erfassen und festhalten.
Es ist relativ neu, es ist nicht das erste autoregressive Netz, aber ich glaube, es ist das erste autoregressive neuronale Netz. Wir haben wirklich geglaubt, dass man, wenn man es gut trainiert, alles erreichen kann, was man will. In unserem Fall handelte es sich um eine maschinelle Übersetzungsaufgabe, die heute konservativ erscheint und damals sehr kühn war. Jetzt zeige ich Ihnen eine alte Geschichte, die viele von Ihnen wahrscheinlich noch nie gesehen haben, und sie heißt LSTM.
Für diejenigen, die damit nicht vertraut sind, ist das LSTM der arme Deep-Learning-Forscher in der Transformator Was vorher gemacht wurde.
Es ist im Grunde ein ResNet, aber um 90 Grad gedreht, also ein LSTM. Es ist also ein LSTM. Ein LSTM ist wie ein etwas komplexeres ResNet. Sie können den Integrator sehen, der jetzt Residualstrom genannt wird. aber es findet eine Multiplikation statt. Es ist ein bisschen kompliziert, aber das ist es, was wir hier tun. Dies ist ein um 90 Grad gedrehtes ResNet. 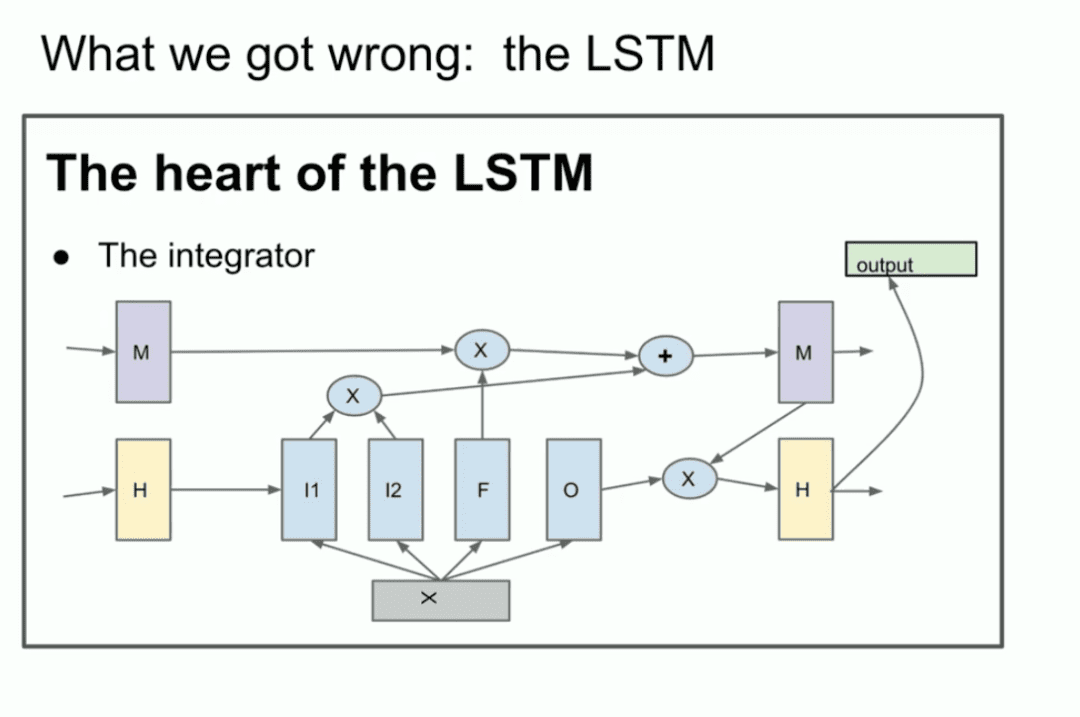
Ein weiterer wichtiger Punkt, den ich in diesem alten Vortrag hervorheben wollte, war, dass wir die Parallelisierung genutzt haben, aber nicht nur die Parallelisierung.
Wir haben Pipelining verwendet, d. h. wir haben jeder Schicht des neuronalen Netzes eine GPU zugewiesen, was, wie wir heute wissen, keine kluge Strategie ist, aber wir waren damals nicht klug. Wir haben es also verwendet und waren mit 8 GPUs 3,5 Mal schneller. 
Die letzte Schlussfolgerung ist die wichtigste Folie. Sie verdeutlicht, was der Anfang der Skalierungsgesetze sein könnte. Wenn Sie einen sehr großen Datensatz haben und ein sehr großes neuronales Netz trainieren, ist der Erfolg garantiert. Wenn man großzügig ist, könnte man sagen, dass genau das passiert. 
Nun möchte ich eine weitere Idee erwähnen, die sich meiner Meinung nach wirklich bewährt hat. Es ist die Kernidee des Deep Learning selbst. Es ist die Idee des Konnektionismus. Wenn man glaubt, dass künstliche Neuronen so etwas wie biologische Neuronen sind, dann ist das eine Idee. Wenn man glaubt, dass das eine dem anderen ein wenig ähnelt, dann kann man auch an hyperskalige neuronale Netze glauben. Sie müssen nicht unbedingt die Größe eines menschlichen Gehirns haben, sie könnten etwas kleiner sein, aber man kann sie so konfigurieren, dass sie so ziemlich alles tun, was wir tun.
Aber es gibt immer noch einen Unterschied zum Menschen, denn das menschliche Gehirn findet heraus, wie es sich selbst rekonfigurieren kann, und wir verwenden die besten Lernalgorithmen, die wir haben, was so viele Datenpunkte wie Parameter erfordert. Der Mensch kann das viel besser. All dies ist auf die, wie ich es nennen würde, "Vor-Ausbildungszeit" ausgerichtet.
All dies ist auf die, wie ich es nennen würde, "Vor-Ausbildungszeit" ausgerichtet.
Und dann haben wir das, was wir das GPT-2-Modell, das GPT-3-Modell und die Skalierungsgesetze nennen, und ich möchte besonders meinen ehemaligen Mitarbeiter Alec Radford sowie Jared Kaplan und Dario Amodei erwähnen, deren Bemühungen all diese Arbeit möglich gemacht haben. 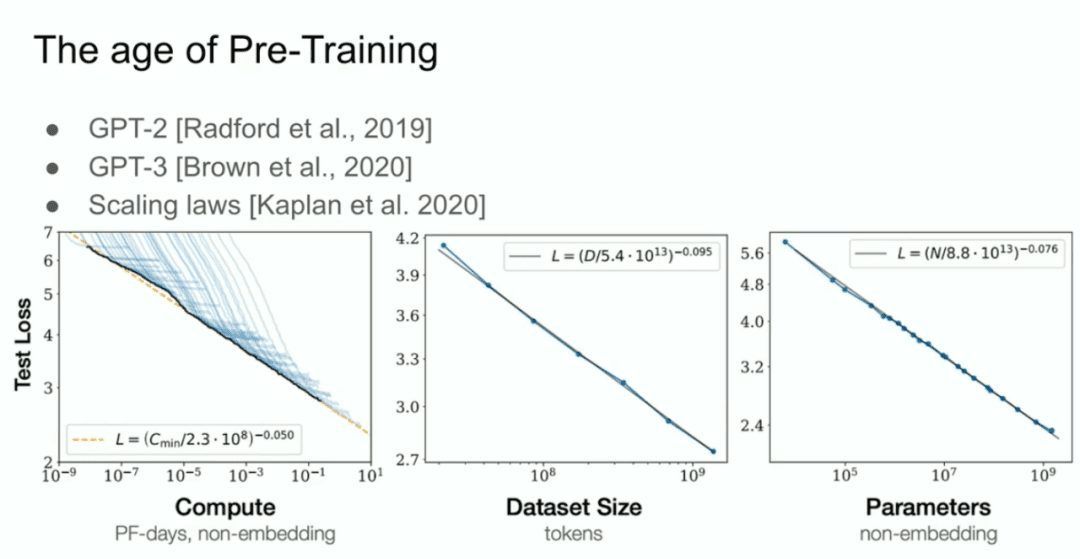 Das ist die Ära des Pre-Trainings, und das ist der Grund für alle Fortschritte, die wir heute sehen: Mega-neuronale Netze, Mega-neuronale Netze, die auf riesigen Datensätzen trainiert werden.
Das ist die Ära des Pre-Trainings, und das ist der Grund für alle Fortschritte, die wir heute sehen: Mega-neuronale Netze, Mega-neuronale Netze, die auf riesigen Datensätzen trainiert werden.
Aber der Weg der Vorbildung, wie wir ihn kennen, wird zweifellos enden. Warum wird sie enden? Weil die Computer durch bessere Hardware, bessere Algorithmen und Logikcluster immer leistungsfähiger werden und die Daten nicht mehr wachsen, weil wir nur ein Internet haben. 
Man könnte sogar sagen, dass Daten der fossile Treibstoff der KI sind. Sie wurden auf eine bestimmte Art und Weise erzeugt, und jetzt, wo wir sie nutzen, haben wir die Nutzung der Daten maximiert, und es kann nicht besser werden. Wir finden heraus, was wir mit den Daten, die wir jetzt haben, tun müssen. Daran werde ich noch arbeiten, und das bringt uns noch ziemlich weit, aber das Problem ist, dass es nur ein Internet gibt.
Deshalb werde ich hier Spekulationen darüber anstellen, was als nächstes passieren wird. Eigentlich brauche ich gar nicht zu spekulieren, denn viele andere spekulieren auch, und ich werde ihre Spekulationen erwähnen.
- Vielleicht haben Sie schon einmal den Ausdruck "Intelligenter Körper-Agent" gehört, er ist ziemlich verbreitet, und ich bin mir sicher, dass irgendwann etwas passieren wird, bei dem die Menschen das Gefühl haben, dass intelligente Körper die Zukunft sind.
- Genauer gesagt, aber auch etwas vage, synthetische Daten. Aber was bedeuten synthetische Daten? Das herauszufinden, ist eine große Herausforderung, und ich bin sicher, dass verschiedene Leute hier alle möglichen interessanten Fortschritte machen.
- Es gibt auch die Inferenzzeitberechnung, oder vielleicht in jüngerer Zeit (OpenAIs) o1, das o1-Modell, das am anschaulichsten zeigt, wie Menschen versuchen, herauszufinden, was sie nach dem Vortraining tun sollen.
Das sind alles sehr gute Dinge. 
Ich möchte noch ein weiteres Beispiel aus der Biologie anführen, das ich wirklich cool finde. Vor vielen Jahren habe ich auf dieser Konferenz auch einen Vortrag gesehen, in dem jemand dieses Diagramm zeigte, das die Beziehung zwischen Körpergröße und Gehirngröße bei Säugetieren darstellte. In diesem Fall war es massiv. In dem Vortrag, an den ich mich gut erinnere, wurde gesagt, dass in der Biologie alles verwirrend ist, aber hier gibt es ein seltenes Beispiel für eine sehr starke Beziehung zwischen der Größe des Körpers eines Tieres und seines Gehirns.
Durch einen glücklichen Zufall wurde ich auf dieses Bild aufmerksam.  Also ging ich zu Google und suchte nach Bildern.
Also ging ich zu Google und suchte nach Bildern.
In dieser Abbildung sind eine Vielzahl von Säugetieren aufgeführt, sowie Nicht-Primaten, die aber weitgehend gleich sind, und Primitive. Soweit ich weiß, waren die Primitiven in ihrer Entwicklung enge Verwandte des Menschen, wie z. B. die Neandertaler. Zum Beispiel der 'Energised Man'. Interessanterweise weisen sie unterschiedliche Steigungen des Verhältnisses von Gehirn zu Körper auf. Das ist sehr interessant.
Das bedeutet, dass es einen Fall gibt, einen Fall für die Biologie, um eine andere Skala zu finden. Es ist offensichtlich, dass etwas anders ist. Übrigens möchte ich betonen, dass diese x-Achse eine logarithmische Skala ist. Das sind 100, 1.000, 10.000, 100.000, wiederum in Gramm, 1 Gramm, 10 Gramm, 100 Gramm, ein Kilogramm. Es ist also möglich, dass die Dinge anders sind.
Was wir tun, was wir bisher in Bezug auf die Skalierung getan haben, wir stellen fest, dass die Art und Weise, wie wir skalieren, die oberste Priorität wird. Es besteht kein Zweifel daran, dass jeder, der hier arbeitet, herausfinden wird, was zu tun ist. Aber ich möchte hier darüber sprechen. Ich möchte mir ein paar Minuten Zeit nehmen, um eine langfristige Prognose abzugeben, etwas, das uns alle betrifft, oder?  All die Fortschritte, die wir machen, sind erstaunliche Fortschritte. Ich meine, diejenigen von Ihnen, die vor 10 Jahren in diesem Bereich gearbeitet haben, wissen noch, wie impotent alles war. Wenn Sie in den letzten zwei Jahren in das Feld des Deep Learning eingestiegen sind, können Sie das wahrscheinlich gar nicht nachvollziehen.
All die Fortschritte, die wir machen, sind erstaunliche Fortschritte. Ich meine, diejenigen von Ihnen, die vor 10 Jahren in diesem Bereich gearbeitet haben, wissen noch, wie impotent alles war. Wenn Sie in den letzten zwei Jahren in das Feld des Deep Learning eingestiegen sind, können Sie das wahrscheinlich gar nicht nachvollziehen.
Ich möchte ein wenig über "Superintelligenz" sprechen, denn das ist eindeutig die Richtung, in die sich das Feld bewegt, und das, was das Feld versucht, aufzubauen.
Sprachmodelle haben derzeit zwar unglaubliche Fähigkeiten, sind aber auch etwas unzuverlässig. Es ist nicht klar, wie sich das vereinbaren lässt, aber früher oder später wird das Ziel erreicht sein: Diese Systeme werden zu echten Intelligenzen. Im Moment sind diese Systeme noch keine mächtigen, sinnvollen Wahrnehmungsintelligenzen; sie fangen gerade erst an zu denken. Übrigens: Je mehr ein System denkt, desto unberechenbarer wird es.
Wir sind daran gewöhnt, dass Deep Learning sehr vorhersehbar ist. Denn wenn man daran arbeitet, die menschliche Intuition nachzubilden, wenn man auf eine Reaktionszeit von 0,1 Sekunden zurückgeht, welche Art von Verarbeitung führt unser Gehirn dann durch? Das ist Intuition, und wir haben AIS etwas von dieser Intuition mitgegeben.
Aber beim Denken gibt es erste Anzeichen dafür, dass das Denken unberechenbar ist. Schach zum Beispiel ist auch für die besten menschlichen Spieler unberechenbar. Wir werden es also mit sehr unberechenbaren KI-Systemen zu tun haben. Sie werden Dinge aus begrenzten Daten verstehen und nicht verwirrt sein.
All das ist sehr einschränkend. Übrigens habe ich nicht gesagt, wie oder wann all diese Dinge mit dem "Selbstbewusstsein" geschehen würden, denn warum sollte das "Selbstbewusstsein" nicht nützlich sein? Wir selbst sind Teil des Modells unserer eigenen Welt.
Wenn all diese Dinge zusammenkommen, werden wir Systeme haben, die ganz andere Qualitäten und Eigenschaften haben als die, die heute existieren. Sie werden natürlich unglaubliche und erstaunliche Fähigkeiten haben. Aber das Problem mit einem solchen System ist, dass ich vermute, dass es sehr unterschiedlich sein wird.
Ich würde sagen, dass es auch unmöglich ist, die Zukunft vorherzusagen. Es sind wirklich alle möglichen Dinge möglich. Ich danke Ihnen allen.
Nach einer Runde Applaus auf der Neurlps-Konferenz beantwortete Ilya einige kurze Fragen von mehreren Fragenden.
F: Gibt es im Jahr 2024 noch andere biologische Strukturen, die für die menschliche Kognition relevant sind und die es Ihrer Meinung nach wert sind, in ähnlicher Weise erforscht zu werden, oder gibt es andere Bereiche, die Sie interessieren?
Ilja:Ich würde die Frage so beantworten: Wenn Sie oder jemand anderes eine Einsicht in ein bestimmtes Problem hat, wie z. B. "Hey, wir ignorieren eindeutig, dass das Gehirn etwas tut, und wir tun es nicht", und es ist machbar, dann sollten sie diese Richtung weiter verfolgen. Ich persönlich habe keine solchen Einsichten. Natürlich kommt es auch auf das Abstraktionsniveau der Forschung an, auf die man sich konzentriert. Viele Menschen streben danach, eine biologisch inspirierte KI zu entwickeln. In gewisser Weise könnte man argumentieren, dass biologisch inspirierte KI ein großer Erfolg war - schließlich ist die gesamte Grundlage des Deep Learning biologisch inspirierte KI. aber andererseits ist diese biologische Inspiration tatsächlich sehr, sehr begrenzt. Im Grunde heißt es nur: "Lasst uns Neuronen verwenden" - das ist alles, was biologisch inspiriert ist. Detailliertere, tiefere Ebenen der Bio-Inspiration sind schwieriger zu erreichen, aber ich würde es nicht ausschließen. Ich denke, es könnte sehr wertvoll sein, wenn jemand mit einem besonderen Einblick einen neuen Blickwinkel entdecken könnte. F: Ich möchte eine Frage zur Autokorrektur stellen.
Sie haben erwähnt, dass die Inferenz eine der Hauptentwicklungsrichtungen für Modelle in der Zukunft sein könnte und ein Unterscheidungsmerkmal darstellen könnte. In einigen der Posterpräsentationen haben wir gesehen, dass es eine "Illusion" der aktuellen Modelle gibt. Unsere derzeitige Methode zur Analyse, ob Modelle halluzinieren (bitte korrigieren Sie mich, wenn ich das falsch verstanden habe, Sie sind der Experte auf diesem Gebiet), basiert hauptsächlich auf statistischen Analysen, z. B. der Feststellung, ob es eine Abweichung vom Mittelwert um eine gewisse Abweichung von der Standardabweichung gibt. Glauben Sie, dass das Modell in Zukunft, wenn es über die Fähigkeit verfügt, logisch zu denken, in der Lage sein wird, sich selbst zu korrigieren, wie die Autokorrektur, und somit zu einem Kernmerkmal künftiger Modelle wird? Auf diese Weise würde das Modell weniger Halluzinationen haben, weil es in der Lage wäre, Situationen zu erkennen, in denen es seine eigenen halluzinatorischen Inhalte erzeugt. Das ist vielleicht eine komplexere Frage, aber glauben Sie, dass zukünftige Modelle in der Lage sein werden, das Auftreten von Halluzinationen durch logisches Denken zu verstehen und zu erkennen?
Ilja:Antwort: Ja.
Ich denke, dass die von Ihnen beschriebene Situation sehr wahrscheinlich ist. Ich bin mir zwar nicht sicher, aber ich schlage vor, dass Sie das überprüfen, und dieses Szenario könnte bereits in einigen frühen Modellen des Denkens aufgetreten sein. Aber warum sollte es auf lange Sicht nicht möglich sein?
F: Ich meine, es ist wie die Autokorrekturfunktion in Microsoft Word, es ist eine Kernfunktion.
Ilja:Ja, ich denke, es "Autokorrektur" zu nennen, ist eigentlich eine Untertreibung. Wenn man "Autokorrektur" sagt, denkt man an relativ einfache Funktionen, aber das Konzept geht weit über Autokorrektur hinaus. Insgesamt lautet die Antwort jedoch ja.
FRAGEGEBER: Vielen Dank. Der nächste Fragesteller ist der zweite.
F: Hallo Ilja, mir hat das Ende mit dem mysteriösen Whiteout sehr gut gefallen. Werden die KIs uns ersetzen, oder sind sie uns überlegen? Brauchen sie Rechte? Es ist eine ganz neue Spezies. Der Homo sapiens hat diese Intelligenz hervorgebracht, und ich glaube, die Leute von Reinforcement Learning sind der Meinung, dass wir Rechte für diese Wesen brauchen.
Ich habe eine damit nicht zusammenhängende Frage: Wie schaffen wir die richtigen Anreize für Menschen, um sie so zu erschaffen, dass sie die gleichen Freiheiten genießen können wie wir Homo sapiens?
Ilja:Ich denke, das sind Fragen, über die die Menschen mehr nachdenken und sich Gedanken machen sollten. Aber auf Ihre Frage, welche Art von Anreizen wir schaffen sollten, kann ich nicht mit Sicherheit eine Antwort geben. Es hört sich so an, als ob wir über die Schaffung einer Art Top-Down-Struktur oder eines Governance-Modells sprechen, aber da bin ich mir wirklich nicht so sicher.
Als Nächstes ist der letzte Fragesteller an der Reihe.
F: Hallo Ilya, danke für die tolle Präsentation. Ich komme von der Universität von Toronto. Ich danke Ihnen für all Ihre Arbeit, die Sie geleistet haben. Ich würde Sie gerne fragen, ob Sie glauben, dass LLMs in der Lage sind, Multi-Hop-Inferenz außerhalb der Verteilung zu verallgemeinern?
Ilja:Okay, diese Frage geht davon aus, dass die Antwort entweder "ja" oder "nein" lautet, aber so sollte sie eigentlich nicht beantwortet werden. Denn wir müssen erst einmal herausfinden: Was bedeutet eigentlich verteilungsübergreifende Verallgemeinerung? Was ist intra-distributiv? Was ist out-of-distribution? Denn hier ist die Rede von "time-testing". Ich würde sagen, dass man vor langer, langer Zeit, also vor Deep Learning, String Matching und n-Gramme für die maschinelle Übersetzung verwendet hat. Damals verließ man sich auf statistische Phrasentabellen. Können Sie sich das vorstellen? Diese Methoden hatten eine Komplexität von Zehntausenden von Codezeilen, eine wirklich unvorstellbare Komplexität. Und damals wurde Generalisierung so definiert, dass das Übersetzungsergebnis nicht buchstäblich identisch mit der Phrasendarstellung im Datensatz war. Nun könnte man sagen: "Mein Modell hat in einem Mathematikwettbewerb sehr gut abgeschnitten, aber vielleicht wurden einige der Ideen für diese Mathematikfragen irgendwann einmal in einem Internetforum diskutiert, so dass das Modell sie sich einfach gemerkt hat." Nun, man könnte argumentieren, dass dies innerhalb der Verteilung liegen könnte, oder es könnte das Ergebnis von Auswendiglernen sein. Aber ich denke, es ist wahr, dass unsere Standards für Verallgemeinerungen dramatisch gestiegen sind - man könnte sogar sagen, signifikant und unvorstellbar hoch.
Meine Antwort lautet also: In gewissem Maße sind Modelle wahrscheinlich nicht annähernd so gut in der Verallgemeinerung wie Menschen. Ich glaube, dass Menschen viel besser verallgemeinern können. Aber gleichzeitig ist es auch wahr, dass KI-Modelle in gewissem Maße zu einer Verallgemeinerung außerhalb der Verteilung fähig sind. Ich hoffe, dass diese Antwort für Sie von Nutzen ist, auch wenn sie ein wenig redundant klingt.
F: Ich danke Ihnen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...