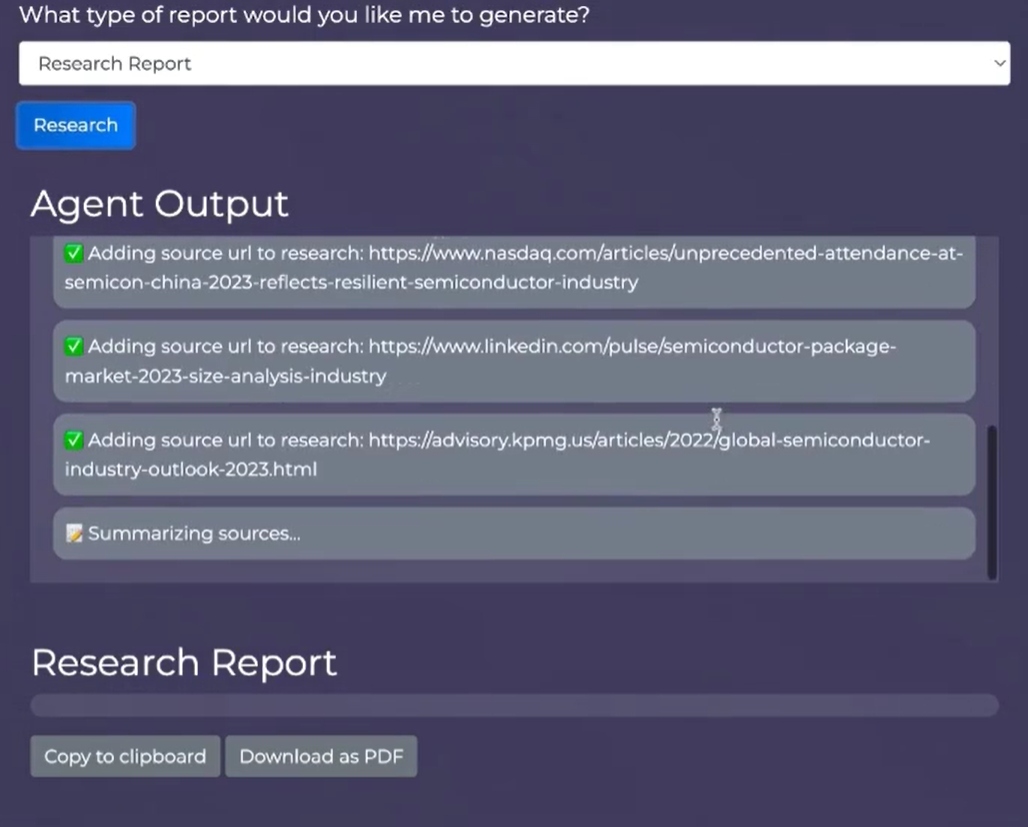
Foudinge Scrub: Aufbau eines Wissensgraphen aus Restaurantbewertungen
Allgemeine Einführung
Foudinge Scrub ist ein Open-Source-Webtool, das auf GitHub gehostet und vom Entwickler Théophile Cantelobre erstellt wurde. Es wurde entwickelt, um Benutzern bei der Bereinigung und Bearbeitung von Knowledge-Graph-Entitäten zu helfen, die aus komplexen Textdaten extrahiert wurden, insbesondere für Daten, die von der Restaurantbewertungsseite LeFooding.com gecrawlt wurden. Das Tool, das auf dem Flask-Framework und reinem JavaScript basiert, unterstützt Funktionen wie die Volltextsuche für Benutzer, die mit doppelten Daten oder Codierungsproblemen zu kämpfen haben. Durch die Einbeziehung von strukturierten Generierungstechniken aus dem Large Language Model (LLM) bietet Foudinge Scrub eine intuitive Schnittstelle, die es dem Benutzer ermöglicht, die Extraktionsergebnisse effizient zu optimieren und gleichzeitig die strukturelle Integrität der Daten zu erhalten. Der Projektcode und die zugehörigen Ressourcen sind auf GitHub öffentlich verfügbar und können von Entwicklern weiterverwendet oder verbessert werden.

Funktionsliste
- Datenbereinigung und Datendeduplizierung:: Identifizieren und Reparieren von doppelten Entitäten oder fehlerhaften Elementen aus Textdaten.
- Volltextsuche:: Unterstützung für die schnelle Suche nach bestimmten Entitäten oder Schlüsselwörtern in der Bearbeitungsoberfläche.
- Strukturierte Bearbeitung:: Bereitstellung einer visuellen Schnittstelle zur manuellen Anpassung von Entitäten im Wissensgraphen unter Beibehaltung einer konsistenten Datenstruktur.
- Kodierungsprobleme behobenBehebung von Zeichenkodierungsfehlern, die durch SQLite oder aus anderen Gründen verursacht werden.
- Open-Source-Unterstützung:: Der Projektcode ist öffentlich zugänglich, und die Benutzer können den Code herunterladen, ändern oder beitragen.
Hilfe verwenden
Anschaffung und Installation
Foudinge Scrub ist ein Open-Source-Projekt, das auf GitHub basiert. Benutzer müssen den Code zunächst herunterladen und lokal ausführen. Im Folgenden wird der Installationsprozess detailliert beschrieben:
1. voraussetzungen
- BetriebssystemWindows, MacOS oder Linux.
- Software-AbhängigkeitErfordert Python 3.7+, Git und einen Code-Editor (z. B. VS Code).
- NetzwerkumgebungStellen Sie sicher, dass Sie Zugang zu GitHub haben und installieren Sie die PyPIs, die Sie für Ihre Abhängigkeiten benötigen.
2. das Projekt herunterladen
- Öffnen Sie ein Terminal oder ein Befehlszeilentool.
- Geben Sie den folgenden Befehl ein, um das Repository zu klonen:
git clone https://github.com/theophilec/foudinge-scrub.git
- Rufen Sie den Projektkatalog auf:
cd foudinge-scrub
3. die Installation von Abhängigkeiten
- Das Projekt basiert auf der Entwicklung von Flask und JavaScript und erfordert eine Python-Abhängigkeit, die installiert werden muss. Führen Sie den folgenden Befehl aus:
pip install -r requirements.txt - für den Fall, dass
requirements.txtEs wird keine Dokumentation zur Verfügung gestellt, die Kernabhängigkeiten können manuell installiert werden:pip install flask - Der JavaScript-Teil verwendet Jinja-Vorlagen, die keine zusätzliche Installation erfordern, aber stellen Sie sicher, dass Sie einen modernen Browser (z. B. Chrome, Firefox) lokal installiert haben.
4. die Anwendung ausführen
- Führen Sie die Flask-Anwendung im Stammverzeichnis des Projekts aus:
python app.py - Nach erfolgreichem Start zeigt das Terminal etwas an wie
Running on http://127.0.0.1:5000/Der Tipp. - Öffnen Sie Ihren Browser und geben Sie
http://127.0.0.1:5000/Um die Foudinge Scrub-Schnittstelle aufzurufen, klicken Sie hier.
5. die Fehlersuche
- sollten wir auf
ModuleNotFoundErrorauf fehlende Abhängigkeitsinstallationen prüfen. - Wenn der Anschluss belegt ist, ändern Sie die
app.pyPortnummer in der5000umwandeln in5001.
Hauptfunktionen
Datenbereinigung und Datendeduplizierung
- Daten vorbereitenFoudinge Scrub verarbeitet standardmäßig Restaurantbewertungsdaten von LeFooding.com. Für maßgeschneiderte Daten, siehe bitte
theophilec/foudingeCrawlen von Code im Repository (unter Verwendung von SQLite, asyncio und aiohttp), um kompatible Knowledge-Graph-Dateien zu erzeugen. - Daten importierenPlatzieren Sie die Datendatei im angegebenen Verzeichnis des Projekts (normalerweise das Stammverzeichnis oder der in der Konfigurationsdatei angegebene Pfad).
- Aufräumarbeiten einleitenWenn die Weboberfläche geöffnet wird, lädt das System automatisch die Daten und zeigt ein visuelles Mapping an. Doppelte oder fehlerhafte Einheiten werden hervorgehoben oder markiert.
- manuelle EinstellungKlicken Sie auf die doppelte Entität, wählen Sie "Zusammenführen" oder "Löschen", bestätigen und speichern Sie die Änderungen.
- Validierung der ErgebnisseNach der Bereinigung wird der Atlas in Echtzeit aktualisiert, um sicherzustellen, dass keine Fehler ausgelassen werden.
Volltextsuche
- Suchmodus aufrufenSuchen Sie das Suchfeld am oberen Rand der Benutzeroberfläche (normalerweise ein Eingabefeld neben einem Lupensymbol).
- Schlüsselwörter eingebenGeben Sie den Namen der zu suchenden Entität (z. B. Restaurantname, Name einer Person) oder ein Schlüsselwort ein.
- Ergebnisse anzeigenDas System listet die Treffer auf und springt durch Anklicken zum entsprechenden Ort der Entität.
- Erweiterte Verwendung:: Unterstützt unscharfe Suchen, z.B. die Eingabe von "Gren" ergibt "Grenat".
Strukturierte Bearbeitung
- Öffnen Sie den Bearbeitungsbildschirm:: Klicken Sie in der Diagrammansicht auf den Knoten, der bearbeitet werden soll (z. B. das Feld "Chef" für ein Restaurant).
- Inhalt der ÄnderungGeben Sie den neuen Wert in das Pop-up-Fenster ein, z. B. ändern Sie den Namen des Restaurants vor "Neil Mahatsry" von "La Brasserie Communale" in etwas anderes.
- Änderungen speichernKlicken Sie auf die Schaltfläche "Speichern". Das System prüft das Datenformat, um sicherzustellen, dass die Struktur konsistent ist.
- Rückgängig machen:: Wenn Sie einen Fehler gemacht haben, können Sie auf die Schaltfläche "Rückgängig" klicken, um den vorherigen Status wiederherzustellen.
Kodierungsprobleme behoben
- Identifizierung des Problems:: Wenn die Schnittstelle verstümmelt ist (z. B. "Antoine Joannier" wird zu "Antoine Joanniér"), liegt ein Kodierungsfehler vor.
- AutoreparaturWählen Sie "Fixe Kodierung" im Menü "Einstellungen" und das System wird versuchen, UTF-8 oder andere Kodierungsformate zu standardisieren.
- manuelle EingabeWenn die automatische Korrektur fehlschlägt, bearbeiten Sie das verstümmelte Feld manuell und geben Sie die richtigen Zeichen ein.
Ausgewählte Funktionen
Wissensgraphen-Optimierung in Verbindung mit LLM
Das Hauptmerkmal von Foudinge Scrub ist die Verwendung von groß angelegten Sprachmodellen (LLMs), um strukturierte Daten zu erzeugen, die durch manuelle Bearbeitung weiter optimiert werden können. Wenn zum Beispiel "Antoine Joannier arbeitete in der Brasserie Communale, bevor er zu Grenat kam" aus einer Restaurantkritik extrahiert wird, erzeugt das LLM JSON:
{
"Person": {
"name": "Antoine Joannier",
"role": "Host",
"previous_restaurants": ["La Brasserie Communale"]
}
}
Diese Struktur kann in der Schnittstelle angepasst werden, indem z.B. ein neues Feld "current_restaurant" hinzugefügt und mit "Grenat" gefüllt wird, wie folgt:
- Prüfen Sie die Knoten für die JSON-Anzeige.
- Klicken Sie auf "Feld hinzufügen" und geben Sie die Schlüssel-Werte-Paare ein.
- Beim Speichern wird die Zuordnung aktualisiert und spiegelt die neue Beziehung wider.
Open-Source-Zusammenarbeit
- Code beisteuernBenutzer können das Repository forken, Änderungen am Code vornehmen und einen Pull Request einreichen, um z. B. einen neuen Suchalgorithmus hinzuzufügen oder die Schnittstelle zu optimieren.
- Dokument anzeigenDie README-Datei im Hauptverzeichnis des Projekts enthält grundlegende Anweisungen, für detaillierte Code-Logik siehe die
app.pyund JavaScript-Dateien.
Empfehlungen für die Verwendung
- Ersteinsatz: Führen Sie zunächst die Beispieldaten aus, um sich mit dem Layout der Schnittstelle und der Betriebslogik vertraut zu machen.
- Groß angelegte DatenBei einer großen Anzahl von Kommentaren empfiehlt es sich, diese in Stapeln zu importieren, um Verzögerungen im Browser zu vermeiden.
- Unterstützung der Gemeinschaft: Stellen Sie eine Frage auf der GitHub Issues-Seite, vielleicht können die Entwickler oder die Community helfen.
Mit diesen Schritten können die Benutzer schnell mit Foudinge Scrub beginnen und die Aufgaben der Datenbereinigung und Wissensgraphenoptimierung effizient erledigen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...