
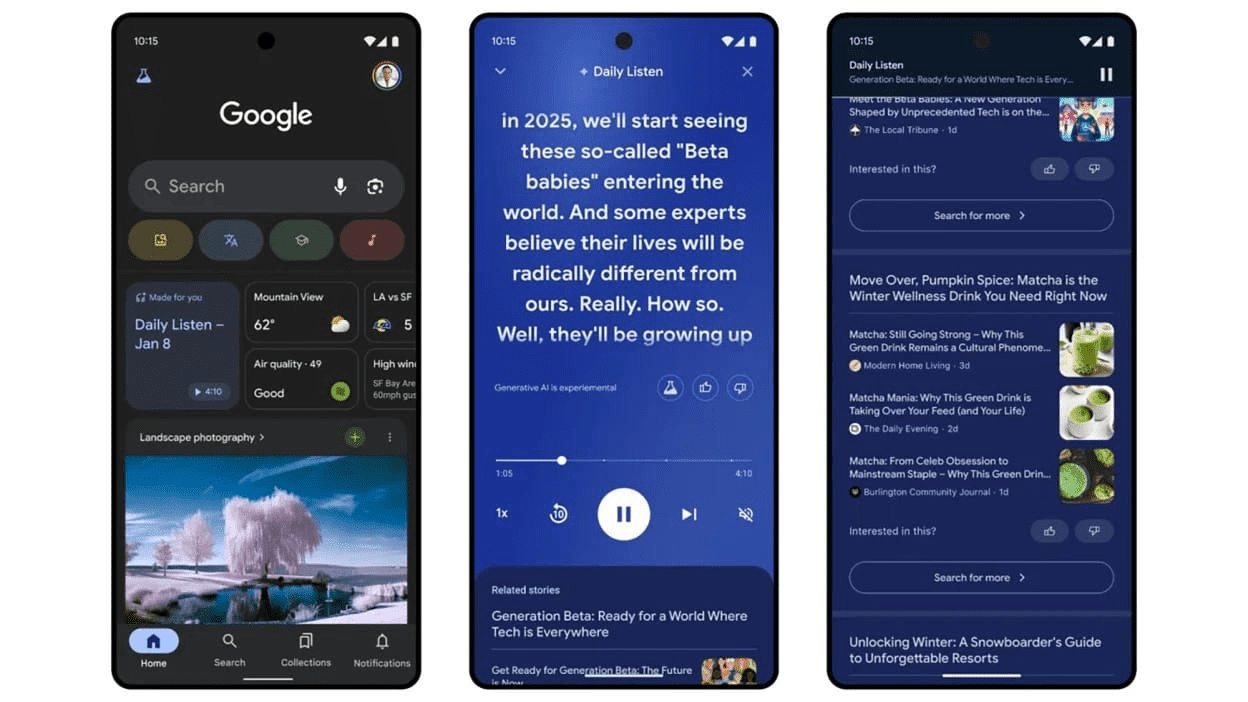
Analyst Alberto Romero spekuliert: Eigentlich ist der GPT-5 von OpenAI längst überfällig
Beginnen wir das neue Jahr auf eine spannende Art und Weise!

- Kann von GPT-5 erzeugt werden
Was wäre, wenn ich Ihnen sagen würde, dass das GPT-5 real ist. Es ist nicht nur real, sondern es gestaltet die Welt bereits auf eine Weise, die Sie nicht sehen können. Hier ein hypothetischer Fall: OpenAI hat GPT-5 entwickelt, behält es aber intern, weil der ROI viel höher ist, als es Millionen von Menschen zugänglich zu machen. ChatGPT Benutzer. Darüber hinaus ist der ROI, den sie durch die Kein Geld. Vielmehr geht es um etwas anderes. Wie Sie sehen können, ist die Idee einfach genug; die Herausforderung besteht darin, die Hinweise, die darauf hindeuten, zusammenzufügen. In diesem Artikel geht es darum, warum ich glaube, dass diese Hinweise letztendlich zusammenhängen.
Vorab ein Hinweis: Dies ist reine Spekulation. Die Beweise sind alle öffentlich zugänglich, aber es gibt keine undichten Stellen oder internen Gerüchte, die bestätigen, dass ich richtig liege. Tatsächlich stelle ich diese Theorie in diesem Artikel auf und gebe sie nicht nur weiter. Ich habe keine privilegierten Informationen - und selbst wenn ich welche hätte, bin ich an eine Vertraulichkeitsvereinbarung gebunden. Diese Hypothese ist überzeugend, weil sie logisch . Ehrlich gesagt, was brauche ich noch, um diese Gerüchteküche in Gang zu bringen?
Ob Sie es glauben oder nicht, bleibt Ihnen überlassen. Selbst wenn ich falsch liege - und wir werden die Antwort schließlich erfahren -, ist es ein unterhaltsames Detektivspiel. Ich lade Sie ein, sich an den Spekulationen in den Kommentaren zu beteiligen, aber bitte bleiben Sie dabei konstruktiv und überlegt. Bitte lesen Sie zuerst den gesamten Artikel durch. Ansonsten ist jede Diskussion willkommen.
I. Mysteriöses Verschwinden von Opus 3.5
Bevor wir uns mit GPT-5 beschäftigen, müssen wir seinen ebenfalls fehlenden entfernten Cousin erwähnen: Anthropic's Claude Opus 3.5.
Wie Sie wissen, bieten die drei großen KI-Labore - OpenAI, Google DeepMind und Anthropic - alle Modellportfolios an, die das Spektrum zwischen Preis/Latenz und Leistung abdecken. openAI hat GPT-4o, GPT-4o mini, sowie o1 und o1-mini; Google DeepMind bietet Zwillinge Ultra, Pro und Flash; Anthropic hat Claude Opus, Sonnet und Haiku, und das Ziel ist klar: so viele Kundenprofile wie möglich abzudecken. Einige suchen unabhängig von den Kosten nach Spitzenleistungen, während andere erschwingliche, angemessene Lösungen benötigen. Das alles macht Sinn.
Doch im Oktober 2024 geschah etwas Seltsames. Während alle damit rechneten Anthropisch Als sie Claude Opus 3.5 als Antwort auf GPT-4o (das im Mai 2024 veröffentlicht wurde) herausbrachten, brachten sie am 22. Oktober eine aktualisierte Version von Claude Sonnet 3.5 (die als Sonnet 3.6 bekannt wurde) heraus, die verschwand, so dass Anthropic ohne ein Produkt in direkter Konkurrenz zu GPT-4o dastand. GPT-4o. Seltsam, nicht wahr? Hier ein kurzer Blick auf die Zeitachse von Opus 3.5:
- Am 28. Oktober schrieb ich in meinem Wochenrückblick: "[Es] gibt Gerüchte, dass Sonnet 3.6 ... . ein Zwischen-Checkpoint, der während des mit Spannung erwarteten Trainingsausfalls von Opus 3.5 generiert wurde." Am selben Tag erschien im r/ClaudeAI-Unterforum ein Beitrag mit dem Titel "Claude 3.5 Opus has been deprecated" (Claude 3.5 Opus wurde veraltet) mit einem Link zur Seite Anthropic models - von Opus 3.5 gibt es immer noch keine Spur. Es gibt Spekulationen, dass dieser Schritt gemacht wurde, um das Vertrauen der Investoren im Vorfeld einer neuen Finanzierungsrunde zu erhalten.
- Am 11. November ließ Anthropic-CEO Dario Amodei im Lex Fridman-Podcast das Opus 3.5 fallen: "Obwohl wir kein genaues Datum nennen können, planen wir nach wie vor die Veröffentlichung von Claude 3.5 Opus" - eine vorsichtig zweideutige, aber effektive Formulierung.
- Am 13. November bestätigte Bloomberg frühe Gerüchte: "Nach Abschluss der Schulung stellte Anthropic fest, dass Opus 3.5 die ältere Version in den Bewertungen übertraf, aber die Steigerung blieb angesichts der Größe des Modells und der Kosten für den Aufbau des Laufs hinter den Erwartungen zurück." Dario nannte kein Datum, anscheinend weil die Ergebnisse nicht zufriedenstellend waren, obwohl das Training mit Opus 3.5 nicht fehlschlug. Beachten Sie den Fokus auf Verhältnis zwischen Kosten und Leistung Nicht nur Leistung.
- Am 11. Dezember brachten der Halbleiterexperte Dylan Patel und sein Team von Semianalysis die letzte Wendung und lieferten die Erklärung: "Anthropic schließt Claude 3.5 Opus Training ab und zeigt gute Leistungen... ... hat es aber nicht veröffentlicht. Weil sie gewechselt haben zu Generierung von Synthesedaten mit Claude 3.5 Opus die das Claude 3.5 Sonnet durch Bonusmodellierung deutlich aufwertet."
Kurz gesagt, Anthropic hat Claude Opus 3.5 trainiert und den Namen fallen gelassen, weil die Ergebnisse nicht gut genug waren. dario glaubt, dass die Ergebnisse mit einem anderen Trainingsprozess hätten verbessert werden können, und vermeidet das Datum. Bloomberg bestätigt, dass es die bestehenden Modelle übertrifft, dass aber die Kosten für die Inferenz (die Kosten für den Benutzer, der das Modell verwendet) unerschwinglich sind, und Dylans Team enthüllt die Verbindung zwischen Sonnet 3.6 und dem fehlenden Opus 3.5: Letzteres wurde verwendet, um intern synthetische Daten zu erzeugen, um die Leistung des ersteren zu verbessern.
Der gesamte Prozess kann wie folgt dargestellt werden:

II. besser, kleiner und billiger?
Der Prozess der Verwendung eines starken und teuren Modells zur Generierung von Daten, um ein etwas schwächeres, aber wirtschaftlicheres Modell zu ergänzen, wird als Destillation bezeichnet. Dies ist eine gängige Praxis. Mit dieser Technik können KI-Labors die Grenzen des reinen Vortrainings überwinden und die Leistung kleinerer Modelle steigern.
Es gibt verschiedene Methoden der Destillation, aber darauf wollen wir hier nicht eingehen. Der springende Punkt ist, dass ein starkes Modell als "Lehrer" das "Schüler"-Modell von [klein, billig und schnell] + (nach einer Dezimalzahl oder einem Bruch) etwas weniger als umgewandelt in [klein, billig, schnell] + Beeindruckend . Dylan erklärt, warum dies für die Kombination Opus 3.5-Sonnet 3.6 von Anthropic sinnvoll ist:
(Die Inferenzkosten (des neuen Sonnet gegenüber dem alten) haben sich nicht wesentlich geändert, aber die Modellleistung hat sich verbessert. Warum sollte man aus Kostengründen 3.5 Opus herausgeben, wenn man 3.5 Sonnet durch Post-Training mit 3.5 Opus erhalten kann?
Zurück zur Kostenfrage: Die Destillation kontrolliert die Ausgaben für Schlussfolgerungen und verbessert gleichzeitig die Leistung. Damit wird das von Bloomberg angesprochene Kernproblem direkt angegangen, und Anthropic entschied sich nicht nur wegen der unzureichenden Ergebnisse, sondern auch wegen des höheren internen Wertes, Opus 3.5 nicht zu veröffentlichen. (Dylan weist darauf hin, dass dies der Grund ist, warum die Open-Source-Gemeinschaft schnell zu GPT-4 aufschließt - sie holen sich das Gold direkt von der OpenAI-Goldmine).
Die erstaunlichste Offenbarung: Sonett 3.6 ist nicht nur hervorragend - es erreicht die oberste Ebene . Das Mittelklassemodell von Anthropic übertrifft das Flaggschiff von OpenAI, indem es durch Opus 3.5 destilliert (und wahrscheinlich aus anderen Gründen; fünf Monate sind in der KI lang genug). Plötzlich begann die Vorstellung, dass hohe Kosten gleichbedeutend mit hoher Leistung sind, zu bröckeln.
Was ist aus der Ära des "größer ist besser" geworden, vor der OpenAI-CEO Sam Altman warnt, dass sie vorbei ist? Ich habe darüber geschrieben. Als die Top-Labore zu Geheimnisträgern wurden, gaben sie keine Parameterzahlen mehr bekannt. Die letzte öffentlich zugängliche Parametergröße von OpenAI war 175 Milliarden für GPT-3 im Jahr 2020. Gerüchte im Juni 2023 deuteten darauf hin, dass GPT-4 ein hybrides Expertenmodell mit ~1,8 Billionen Parametern war. Eine anschließende detaillierte Bewertung durch Semianalysis bestätigte, dass GPT-4 im Juli 2023 1,76 Billionen Parameter hatte. Die anschließende detaillierte Auswertung von Semianalysis bestätigte, dass GPT-4 im Juli 2023 1,76 Billionen Parameter hatte.
Bis Dezember 2024 - also in anderthalb Jahren - schätzt Ege Erdil, Forscherin bei EpochAI, einer Organisation, die sich mit den zukünftigen Auswirkungen der KI befasst, dass die Parametergrößen der Frontier-Modelle, einschließlich GPT-4o und Sonnet 3.6, deutlich kleiner sind als GPT-4 (obwohl beide Benchmarks GPT-4 übertreffen):
... Aktuelle Grenzmodelle wie die erste Generation von GPT-4o und Claude 3.5 Sonnet können um eine Größenordnung kleiner sein als GPT-4, wobei 4o etwa 200 Milliarden Parameter und 3.5 Sonnet etwa 400 Milliarden Parameter umfasst ... Allerdings kann die Ungenauigkeit der Schätzung zu Fehlern von bis zu einem Faktor zwei führen.
Er erklärt ausführlich, wie er zu dieser Zahl gekommen ist, ohne dass das Labor architektonische Details preisgibt, aber das ist für uns nicht wichtig. Der Punkt ist, dass sich der Nebel lichtet: Anthropic und OpenAI scheinen ähnliche Wege zu gehen. Ihre neuesten Modelle sind nicht nur besser, sondern auch kleiner und billiger als ihre Vorgänger. Wir wissen, dass Anthropic dies durch die Destillation von Opus 3.5 erreicht hat. Aber was hat OpenAI getan?

III. KI-Labore werden durch Universalismus angetrieben
Man könnte meinen, dass die Destillationsstrategie von Anthropic auf eine einzigartige Situation zurückzuführen ist - nämlich auf die schlechten Trainingsergebnisse von Opus 3.5. Aber in Wirklichkeit ist die Situation von Anthropic nicht einzigartig, und die jüngsten Trainingsergebnisse von Google DeepMind und OpenAI sind ebenso unbefriedigend. (Beachten Sie, dass schlechte Ergebnisse nicht dasselbe sind wie Das Modell ist schlimmer. ) Die Gründe sind uns egal: abnehmende Erträge aufgrund unzureichender Daten, inhärente Beschränkungen der Transformer-Architektur, Plateau des Pre-Training-Skalierungsgesetzes usw. In jedem Fall ist der besondere Kontext von Anthropic eigentlich universell.
Aber denken Sie daran, was Bloomberg berichtet: Leistungskennzahlen sind nur so gut wie die Kosten. Ist dies ein weiterer gemeinsamer Faktor? Ja, und Ege erklärt, warum: der Nachfrageschub nach dem ChatGPT/GPT-4-Boom. Die generative KI breitet sich in einem Tempo aus, das es den Labors schwer macht, die Verluste einer weiteren Expansion zu tragen. Daher waren sie gezwungen, die Kosten für die Inferenz zu senken (das Training ist nur einmalig, die Kosten für die Inferenz wachsen mit dem Nutzervolumen und der Nutzung). Wenn 300 Millionen Nutzer das Produkt jede Woche verwenden, könnten die Betriebskosten plötzlich fatal sein.
Die Faktoren, die Anthropic dazu veranlassten, Sonnet 3.6 mit Destillation zu verbessern, wirken sich mit exponentieller Intensität auf OpenAI aus. Destillation ist effektiv, weil sie diese beiden allgegenwärtigen Herausforderungen in Stärken umwandelt: Lösung des Problems der Inferenzkosten durch die Bereitstellung kleiner Modelle, während gleichzeitig keine großen Modelle veröffentlicht werden, um öffentliche Reaktionen auf mittelmäßige Leistungen zu vermeiden.
Ege glaubt, dass OpenAI die Alternative wählen könnte: Übertraining. Das heißt, mehr Daten mit kleineren Modellen in einem rechnerisch nicht optimalen Zustand zu trainieren: "Wenn die Inferenz einen großen Teil der Kosten des Modells ausmacht, ist es am besten, ... mehr Token mit kleineren Modellen zu trainieren." Aber Übertraining ist nicht mehr machbar. Wenn die Inferenz einen großen Teil der Modellkosten ausmacht, ist es besser, mehr Token mit kleineren Modellen zu trainieren." Aber Übertraining ist nicht mehr machbar; AI Labs hat keine qualitativ hochwertigen Pre-Trainingsdaten mehr, wie sowohl Elon Musk als auch Ilya Sutskever kürzlich eingeräumt haben.
Um auf die Destillation zurückzukommen, kommt Ege zu dem Schluss: "Ich denke, es ist wahrscheinlich, dass sowohl das GPT-4o als auch das Claude 3.5 Sonnet aus größeren Modellen destilliert wurden."
Alle bisherigen Hinweise deuten darauf hin, dass OpenAI das Gleiche tut wie Anthropic mit Opus 3.5 (train and hide), und zwar auf dieselbe Weise (Destillation) und aus denselben Gründen (schlechte Ergebnisse/Kostenkontrolle). Dies ist eine Entdeckung. Aber hier ist die Sache: Opus 3.5 dennoch Wo sind die OpenAI-Pendants versteckt? Ist es im Keller des Unternehmens versteckt? Erraten Sie seinen Namen...

IV. Pioniere müssen den Weg frei machen
Ich beginne die Analyse mit einer Untersuchung des Opus 3.5-Ereignisses von Anthropic, das in seinen Informationen transparenter ist. Dann übertrage ich das Konzept der Destillation auf OpenAI und erkläre, dass die gleichen zugrunde liegenden Kräfte, die Anthropic antreiben, auch auf OpenAI wirken, aber unsere Theorie stößt auf ein neues Hindernis: Als Pionier könnte OpenAI auf Hindernisse stoßen, die Anthropic noch nicht kennt.
Zum Beispiel die Hardware-Anforderungen für die Ausbildung GPT-5. Sonnet 3.6 ist vergleichbar mit GPT-4o, aber es wurde fünf Monate später veröffentlicht. Wir sollten davon ausgehen, dass GPT-5 auf einem höheren Niveau ist: leistungsfähiger und größer. Nicht nur die Argumentationskosten, sondern auch die Ausbildungskosten sind höher. Die Ausbildungskosten könnten sich auf eine halbe Milliarde Dollar belaufen. Ist es möglich, dies mit der vorhandenen Hardware zu erreichen?
Ege ist wieder einmal aufgetaucht: Es ist möglich. Es ist nicht realistisch, 300 Millionen Nutzern ein solches Ungetüm anzubieten, aber die Ausbildung ist kein Problem:
Im Prinzip reicht die vorhandene Hardware aus, um Modelle zu unterstützen, die viel größer sind als GPT-4: z. B. ein Modell mit 100 Billionen Parametern, das 50 Mal größer ist als GPT-4, mit Inferenzkosten von etwa $3000/Million Output-Token und einer Output-Rate von 10-20 Token/Sekunde. Damit dies jedoch machbar ist, müssen große Modelle einen erheblichen wirtschaftlichen Wert für die Kunden schaffen.
Aber selbst Microsoft, Google oder Amazon (die Eigentümer von OpenAI, DeepMind bzw. Anthropic) können sich diese Art von Schlussfolgerungen nicht leisten. Die Lösung ist einfach: Wenn sie Billionen parametrischer Modelle der Öffentlichkeit zur Verfügung stellen wollen, müssten sie "einen erheblichen wirtschaftlichen Wert schaffen". Das tun sie also nicht.
Sie trainierten das Modell. Sie stellten fest, dass die Leistung besser ist als bei bestehenden Produkten. Aber sie müssen akzeptieren, dass "die Verbesserung nicht groß genug ist, um die enormen Kosten für den Betrieb zu rechtfertigen". (Kommt Ihnen das bekannt vor? Das Wall Street Journal berichtete vor einem Monat über das GPT-5 mit ähnlichen Worten wie Bloombergs Bericht über Opus 3.5).
Sie berichten über mittelmäßige Ergebnisse (mit der Flexibilität, den Bericht anzupassen). Behalten Sie sie intern als Lehrermodelle, um Schülermodelle zu destillieren. Dann geben Sie letztere frei. Wir bekommen Sonnet 3.6 und GPT-4o, o1, etc. und freuen uns über ihre billige Qualität. Die Erwartungen an Opus 3.5 und GPT-5 bleiben intakt, auch wenn wir immer ungeduldiger werden. Ihre Goldgrube glänzt weiterhin.
V. Sie haben doch sicher noch mehr Gründe, Herr Altman!
V. Natürlich haben Sie mehr Gründe, Herr Altman!
Als ich in meiner Untersuchung so weit kam, war ich immer noch nicht völlig überzeugt. Es stimmt, dass alle Beweise darauf hindeuten, dass es für OpenAI völlig plausibel ist, aber es gibt immer noch eine Lücke zwischen "plausibel" oder sogar "plausibel" und "real". Ich werde diese Lücke nicht für Sie füllen - es ist schließlich nur eine Spekulation. Aber ich kann das Argument noch verstärken.
Gibt es weitere Beweise dafür, dass OpenAI auf diese Weise vorgeht? Gibt es noch weitere Gründe für die Verzögerung der Veröffentlichung von GPT-5, abgesehen von der schlechten Leistung und den zunehmenden Verlusten, und welche Informationen können wir aus den öffentlichen Erklärungen der OpenAI-Führungskräfte über GPT-5 entnehmen? Riskieren sie nicht einen Imageschaden, wenn sie die Veröffentlichung des Modells immer wieder hinauszögern? Schließlich ist OpenAI das Aushängeschild der KI-Revolution, und Anthropic steht in ihrem Schatten.Anthropic kann es sich leisten, so zu agieren, aber was ist mit OpenAI? Vielleicht nicht ohne einen Preis.
Da wir gerade von Geld sprechen, lassen Sie uns einige relevante Details über die Partnerschaft von OpenAI mit Microsoft herausfinden. Zunächst die bekannte Tatsache: die AGI-Satzung. In OpenAIs Blog-Post über ihre Struktur gibt es fünf Governance-Klauseln, die ihre Arbeitsweise, ihre Beziehung zu gemeinnützigen Organisationen, ihre Beziehung zu ihrem Vorstand und ihre Beziehung zu Microsoft definieren. Die fünfte Klausel definiert AGI als "ein hochgradig autonomes System, das in der Lage ist, den Menschen in den meisten wirtschaftlich wertvollen Unternehmungen zu übertreffen" und legt fest, dass, sobald der OpenAI-Vorstand erklärt, dass AGI implementiert wurde, "das System von der Lizenzierung geistigen Eigentums und anderen kommerziellen Bedingungen mit Microsoft ausgenommen wird, die nur den Bedingungen der Microsoft-Lizenz und anderen kommerziellen Bedingungen unterliegen. Andere kommerzielle Bedingungen mit Microsoft, die nur für die Technologie vor AGI gelten."
Natürlich will keines der beiden Unternehmen, dass die Partnerschaft scheitert. openAI legt die Bedingungen fest, tut aber alles, um sie nicht einhalten zu müssen. Eine Möglichkeit, dies zu tun, ist die Verzögerung der Veröffentlichung von Systemen, die als AGI bezeichnet werden könnten. "Aber GPT-5 ist doch keine AGI", werden Sie sagen. Und hier noch eine zweite Tatsache, die fast niemand kennt: OpenAI und Microsoft haben eine geheime Definition von AGI, die zwar für wissenschaftliche Zwecke irrelevant ist, aber ihre Partnerschaft rechtlich festlegt: Eine AGI ist ein "KI-System, das in der Lage ist, mindestens 100 Milliarden Dollar Gewinn zu erwirtschaften". KI-System.
Wenn OpenAI hypothetisch die Veröffentlichung unter dem Vorwand verzögern würde, dass GPT-5 noch nicht fertig sei, würden sie neben der Kostenkontrolle und der Verhinderung eines öffentlichen Rückschlags noch etwas anderes erreichen: Sie würden vermeiden, bekannt zu geben, ob es die Schwelle zur Einstufung als AGI erreicht oder nicht. 100 Milliarden Dollar sind zwar eine schwindelerregende Zahl, aber nichts hindert ehrgeizige Kunden daran, so viel Gewinn zu machen. Andererseits sollten wir uns darüber im Klaren sein: Wenn OpenAI vorhersagt, dass GPT-5 100 Milliarden Dollar an wiederkehrenden Einnahmen pro Jahr generieren wird, wird es ihnen nichts ausmachen, die AGI-Klausel auszulösen und sich von Microsoft zu trennen.
Die meisten öffentlichen Reaktionen auf die Nichtveröffentlichung von GPT-5 durch OpenAI basierten auf der Annahme, dass sie es nicht veröffentlichen, weil es nicht gut genug sei. Selbst wenn dies zuträfe, würde kein Skeptiker auf den Gedanken kommen, dass OpenAI vielleicht einen besseren internen Anwendungsfall als eine externe Nutzung hat. Es besteht ein großer Unterschied zwischen der Entwicklung eines großartigen Modells und der Entwicklung eines großartigen Modells, das 300 Millionen Menschen kostengünstig bedienen kann. Wenn man das nicht kann, wird man es nicht tun. Aber noch einmal, wenn Sie unnötig Tun Sie es, und Sie werden es nicht tun. Früher haben sie uns ihre besten Modelle zur Verfügung gestellt, weil sie unsere Daten brauchten. Das ist jetzt nicht mehr so notwendig. Und sie sind nicht mehr hinter unserem Geld her. Das ist Microsofts Sache, nicht ihre. Sie wollen AGI, dann ASI. Sie wollen ein Vermächtnis hinterlassen.

VI. warum dies alles ändert
Wir nähern uns dem Ende. Ich glaube, ich habe genug Argumente vorgebracht, um eine solide These aufzustellen: Es ist sehr wahrscheinlich, dass OpenAI bereits GPT-5 im Haus hat, so wie Anthropic Opus 3.5 hat. Es ist sogar möglich, dass OpenAI niemals GPT-5 veröffentlichen wird. Die Öffentlichkeit misst die Leistung jetzt in Form von o1/o3, nicht nur GPT-4o oder Claude Sonnet 3.6. da OpenAI das Gesetz der Skalierung in Tests erforscht, steigt die Latte, die für GPT-5 überschritten werden muss, immer weiter an. Wie können sie ein GPT-5 herausbringen, das wirklich besser ist als o1, o3 und die kommenden Modelle der o-Serie, vor allem, wenn sie sie in einem so schnellen Tempo herausbringen? Außerdem brauchen sie unser Geld und unsere Daten nicht mehr.
Die Ausbildung neuer Basismodelle - GPT-5, GPT-6 und später - war intern für OpenAI immer sinnvoll, aber nicht unbedingt als Produkt. Das ist wahrscheinlich vorbei. Das einzige wichtige Ziel für sie ist jetzt, weiterhin bessere Daten für die nächste Generation von Modellen zu generieren. Von nun an könnte das Basismodell im Hintergrund arbeiten und andere Modelle zu Leistungen befähigen, die sie allein nicht erreichen könnten - wie ein zurückgezogener alter Mann, der seine Weisheiten aus einer geheimen Höhle weitergibt, nur dass diese Höhle ein riesiges Datenzentrum ist. Ob wir ihn nun sehen oder nicht, wir werden die Folgen seiner Weisheit erfahren.

Selbst wenn der GPT-5 schließlich veröffentlicht wird, erscheint diese Tatsache plötzlich fast irrelevant. Wenn OpenAI und Anthropic in die Gänge kommen Rekursive Selbstverbesserung (allerdings immer noch mit menschlicher Beteiligung), dann wird es keine Rolle mehr spielen, was sie uns öffentlich mitteilen. Sie werden immer weiter vorankommen - so wie sich das Universum so schnell ausdehnt, dass das Licht aus fernen Galaxien uns nicht mehr erreichen kann.
Vielleicht ist das der Grund, warum OpenAI in nur drei Monaten von o1 auf o3 aufgestiegen ist. Es ist auch der Grund, warum sie auf o4 und o5 springen. Das ist wahrscheinlich der Grund, warum sie in letzter Zeit in den sozialen Medien so aufgeregt waren. Weil sie eine neue und verbesserte Arbeitsweise eingeführt haben.
Glauben Sie wirklich, dass die Nähe zur AGI bedeutet, dass Sie in der Lage sein werden, immer leistungsfähigere KI zu nutzen? Dass sie jeden Fortschritt für uns freigeben wird, damit wir ihn nutzen können? Natürlich werden Sie das nicht glauben. Sie meinten es ernst, als sie zum ersten Mal sagten, dass ihre Modelle sie so weit bringen würden, dass niemand sonst in der Lage sein würde, sie einzuholen. Jede neue Generation von Modellen ist ein Motor der Fluchtgeschwindigkeit. Aus der Stratosphäre haben sie abgewunken.
Es bleibt abzuwarten, ob sie zurückkehren werden.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...