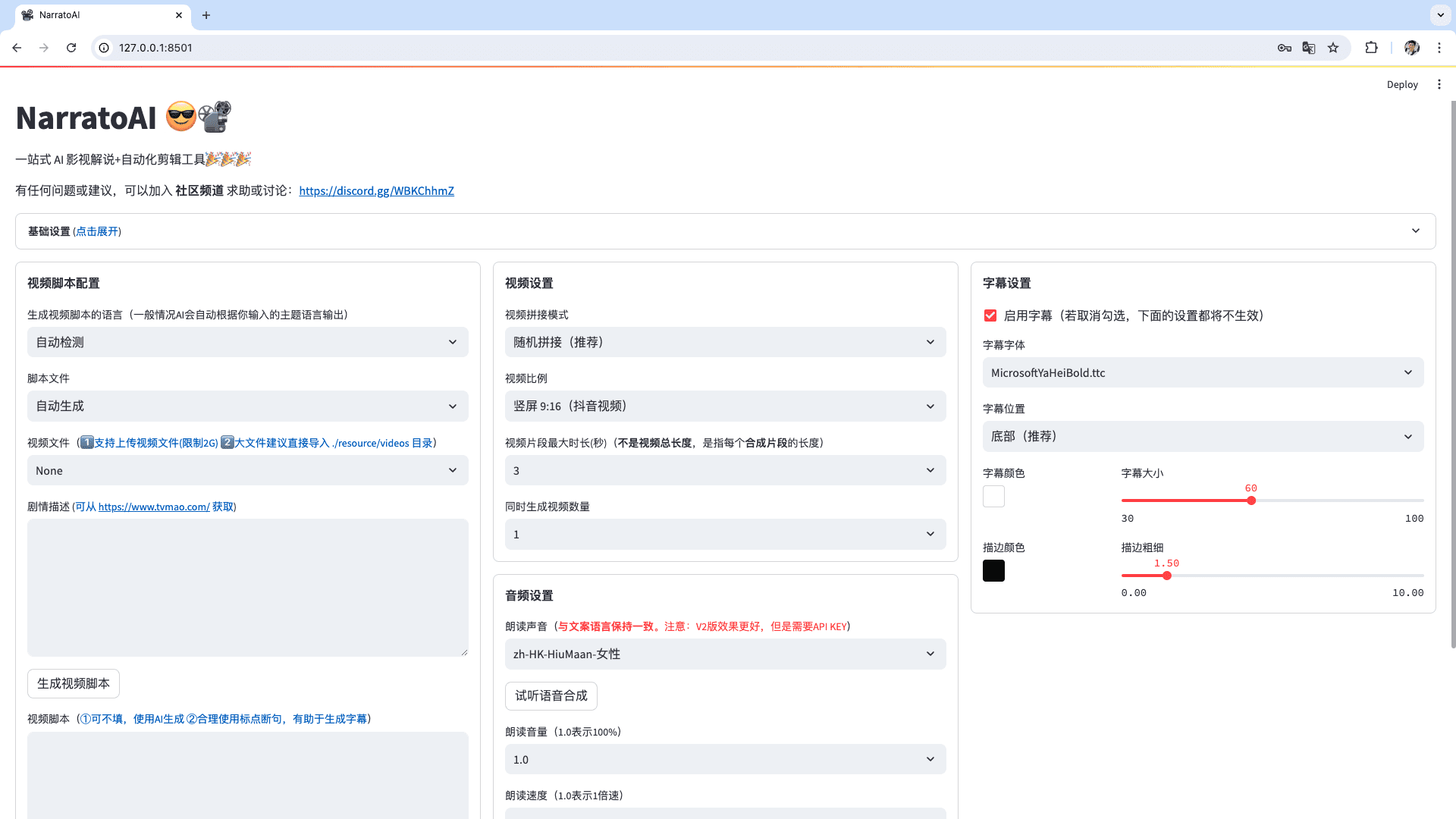
Dia: ein Text-to-Speech-Modell zur Erzeugung hyperrealistischer Multiplayer-Dialoge

Allgemeine Einführung
Dia ist ein von Nari Labs entwickeltes Open-Source-Text-to-Speech (TTS)-Modell, das sich auf die Erzeugung von hyperrealistischem Dialog-Audio konzentriert. Es wandelt Text-Skripte in einem einzigen Prozess in realistische Dialoge mit mehreren Charakteren um, unterstützt die Steuerung von Emotionen und Intonation und generiert sogar nonverbale Ausdrücke wie Lachen. Das Herzstück von Dia ist ein Modell mit 1,6 Milliarden Parametern, das auf Hugging Face gehostet wird und dessen Code und Pre-Training-Modelle den Nutzern über GitHub zur Verfügung stehen. Dia wurde mit dem Schwerpunkt auf Offenheit und Flexibilität entwickelt und ermöglicht es den Nutzern, die volle Kontrolle über Dialogskripte und Sprachausgabe zu haben. Das Projekt wird von der Google TPU Research Cloud und dem Hugging Face ZeroGPU Grant unterstützt und ist von Technologien wie SoundStorm und Parakeet inspiriert.

Demo-Adresse: https://huggingface.co/spaces/nari-labs/Dia-1.6B
Funktionsliste
- Erzeugung surrealer DialogeKonvertierung von Textskripten in Mehrzeichen-Dialog-Audio mit Unterstützung für mehrere Sprecher-Tags (z.B. [S1], [S2]).
- Emotionen und KlangkontrolleAnpassung der Emotionen und der Intonation von Sprache durch Audiohinweise oder feste Samen.
- nonverbaler AusdruckGenerieren Sie nonverbale Geräusche wie Lachen und Pausen, um den Realismus der Dialoge zu erhöhen.
- Gradio Interaktive SchnittstelleBietet eine visuelle Schnittstelle zur Vereinfachung der Dialogerstellung und der Audioausgabe.
- Quelloffene Modelle und CodesBenutzer können vortrainierte Modelle von Hugging Face herunterladen oder den Quellcode auf GitHub erhalten.
- Geräteübergreifende UnterstützungUnterstützt GPU-Betrieb, CPU-Unterstützung ist für die Zukunft geplant.
- Wiederholbare Einstellungen: Sicherstellung der konsistenten Erzeugung von Ergebnissen durch Setzen von Zufallsseeds.
Hilfe verwenden
Einbauverfahren
Um Dia zu verwenden, müssen Sie zunächst Ihr GitHub-Repository klonen und Ihre Umgebung einrichten. Hier sind die detaillierten Schritte:
- Klon-Lager::
Führen Sie den folgenden Befehl im Terminal aus:git clone https://github.com/nari-labs/dia.git cd dia - Erstellen einer virtuellen Umgebung::
Verwenden Sie Python zur Erstellung virtueller Umgebungen, um Abhängigkeiten zu isolieren:python -m venv .venv source .venv/bin/activate # Windows 用户运行 .venv\Scripts\activate - Installation von Abhängigkeiten::
Dia VerwendunguvWerkzeuge zur Verwaltung von Abhängigkeiten. InstallationuvUnd laufen:pip install uv uv run app.pyDadurch werden automatisch die erforderlichen Bibliotheken installiert und die Gradio-Schnittstelle gestartet.
- Hardware-Voraussetzung::
- GPUsEmpfohlene NVIDIA-GPUs mit CUDA-Unterstützung.
- CPUGPU-Optimierung ist derzeit besser, CPU-Unterstützung ist geplant.
- Direktzugriffsspeicher (RAM)Mindestens 16 GB RAM, für das Laden von Modellen ist mehr Speicher erforderlich.
- Überprüfen der Installation::
in Bewegung seinuv run app.pyDanach zeigt das Terminal die lokale URL der Gradio-Schnittstelle an (normalerweise diehttp://127.0.0.1:7860). Öffnen Sie diese URL in Ihrem Browser und überprüfen Sie, ob die Schnittstelle ordnungsgemäß geladen wird.
Verwendung der Gradio-Schnittstelle
Die Gradio-Schnittstelle ist die primäre Interaktionsmethode von Dia und eignet sich für schnelle Tests und die Erstellung von Dialogen. Die Schritte sind wie folgt:
- Öffnen Sie die Schnittstelle::
aktivieren (einen Plan)uv run app.pyDie Oberfläche enthält Texteingabefelder, Parametereinstellungen und Audioausgabebereiche. - Eingabe von Dialogskripten::
Geben Sie das Skript in das Textfeld ein, indem Sie die[S1]und[S2]usw., um zwischen den Sprechern zu unterscheiden. Zum Beispiel:[S1] 你好,今天过得怎么样? [S2] 还不错,就是有点忙。(笑)Das Skript unterstützt nicht-sprachliche Auszeichnungen wie
(笑). - Einstellung der Generierungsparameter::
- Maximum Audio Marker(
--max-tokens): Steuert die Länge des erzeugten Tons, Standardwert 3072. - CFG-Verhältnis(
--cfg-scale): Passt die Generierungsqualität an, Standardwert 3.0. - Aushilfe(
--temperature): steuert die Zufälligkeit, Standardwert 1,3, je höher der Wert, desto mehr Zufall. - Top-p(
--top-p): Kernel-Stichprobenwahrscheinlichkeit, Standardwert 0,95.
Diese Parameter können in der Benutzeroberfläche angepasst werden, und Anfänger können die Standardwerte verwenden.
- Maximum Audio Marker(
- Hinzufügen von Audiohinweisen (optional)::
Um die Stimmkonsistenz zu gewährleisten, können Sie einen Referenzton hochladen. Klicken Sie auf die Option "Audio Cue" in der Benutzeroberfläche und wählen Sie eine WAV-Datei aus. In der offiziellen Dokumentation wird erwähnt, dass in Kürze Richtlinien für Audio-Cueing veröffentlicht werden, aber im Moment können Sie sich auf das Beispiel in der Gradio-Benutzeroberfläche beziehen. - Audio generieren::
Klicken Sie auf die Schaltfläche "Generieren", und das Modell verarbeitet das Skript und gibt den Ton aus. Die Generierungszeit hängt von der Leistung der Hardware ab und beträgt in der Regel ein paar Sekunden bis zu einigen zehn Sekunden. Die erzeugten Audiodaten können in der Benutzeroberfläche als Vorschau angezeigt oder als WAV-Datei heruntergeladen werden. - Samenfixierung::
Um sicherzustellen, dass der erzeugte Ton jedes Mal derselbe ist, können Sie einen Zufallswert festlegen. Klicken Sie auf die Option "Seed" in der Benutzeroberfläche und geben Sie eine ganze Zahl ein (z.B.35). Wenn dies nicht der Fall ist, kann Dia jedes Mal einen anderen Ton erzeugen.
Verwendung der Befehlszeile
Zusätzlich zu Gradio unterstützt Dia auch Befehlszeilenoperationen für Entwickler oder Batchgenerierung. Unten ist das Beispiel:
- Ausführen von CLI-Skripten::
Läuft in einer virtuellen Umgebung:python cli.py "[S1] 你好! [S2] 嗨,很好。" --output output.wav - Modelle spezifizieren::
Standardmäßig wird das Gesicht der Umarmungnari-labs/Dia-1.6BModelle. Wenn Sie ein lokales Modell verwenden, müssen Sie eine Konfigurationsdatei und Kontrollpunkte bereitstellen:python cli.py --local-paths --config config.yaml --checkpoint checkpoint.pt "[S1] 测试" --output test.wav - Anpassungsparameter::
Die Generierungsparameter können z.B. über die Kommandozeile eingestellt werden:python cli.py --text "[S1] 你好" --output out.wav --max-tokens 3072 --cfg-scale 3.0 --temperature 1.3 --top-p 0.95 --seed 35
Featured Function Bedienung
- Dialog mit mehreren Charakteren::
Die Kernkompetenz von Dia liegt in der Erstellung von Dialogen mit mehreren Akteuren. Skripte werden mit dem[S1]und[S2]Markierungen zur Unterscheidung der Charaktere, so weist das Modell jedem Charakter automatisch eine andere Stimme zu. Es wird empfohlen, den Tonfall oder die Emotionen der Charaktere im Skript zu verdeutlichen, zum Beispiel:[S1] (兴奋)我们赢了! [S2] (惊讶)真的吗?太棒了! - nonverbaler Ausdruck::
Dem Skript hinzufügen(笑)und(停顿)und andere Marker, erzeugt Dia die entsprechenden Soundeffekte. Beispiel:[S2] 这太好笑了!(笑) - Stimmkonsistenz::
Um zu vermeiden, dass jedes Mal andere Töne erzeugt werden, müssen Sie entweder den Seed festlegen oder Audio-Cues verwenden. Die Fixierung des Seeds erfolgt in der Gradio-Schnittstelle oder auf der Kommandozeile über den Befehl--seedEinstellungen. Audio-Prompts sollten als hochwertige WAV-Dateien mit klaren Sprachclips hochgeladen werden.
caveat
- Die Modelle sind nicht auf bestimmte Klänge abgestimmtGenerierte Geräusche können jedes Mal anders sein und die Konsistenz muss durch Seeding oder Audio Cueing sichergestellt werden.
- Hardware-BeschränkungGPU-Leistung: Die GPU-Leistung hat einen erheblichen Einfluss auf die Generierungsgeschwindigkeit und kann auf Geräten der unteren Leistungsklasse langsamer sein.
- Ethische LeitlinienNari Labs stellt ethische und rechtliche Richtlinien für die Nutzung zur Verfügung, die von den Benutzern befolgt werden müssen, um die Erstellung unangemessener Inhalte zu vermeiden.
Anwendungsszenario
- Erstellung von Inhalten
Dia eignet sich für die Erstellung realistischer Dialoge für Podcasts, Animationen oder kurze Videos. Kreative können Skripte eingeben und schnell die Stimmen der Charaktere generieren, wodurch die Kosten für die Aufnahme entfallen. Animatoren können zum Beispiel Dialoge mit verschiedenen Intonationen für ihre Figuren erzeugen, um ihre Arbeit zu verbessern. - Bildung und Ausbildung
Dia kann Audiodialoge für das Sprachenlernen oder Rollenspieltraining erstellen. Sprachlehrer können zum Beispiel Multi-Rollen-Dialoge erstellen, die reale Szenarien simulieren, damit die Schüler das Hören und Sprechen üben können. - Spieleentwicklung
Spieleentwickler können Dia verwenden, um dynamische Dialoge für NPCs zu erstellen. Die Skripte unterstützen Emotions-Tagging und können charakter-spezifische Sprache für verschiedene Szenarien erzeugen. - Forschung und Entwicklung
KI-Forscher können TTS-Technologien durch Sekundärentwicklung auf der Grundlage des offenen Quellcodes von Dia erforschen. Das Modell unterstützt lokales Laden, was für Experimente und Optimierung geeignet ist.
QA
- Welche Eingabeformate werden von Dia unterstützt?
Dia akzeptiert Text-Skripte mit[S1]und[S2]Marker unterscheiden zwischen Sprechern. Nonverbale Token wie(笑)Der Audio-Cue ist optional auch im WAV-Format erhältlich. - Wie kann ich sicherstellen, dass die erzeugten Klänge konsistent sind?
Feste Seeds können durch die Einstellung (--seed) oder laden Sie eine Audio-Cue-Implementierung hoch. Die Seeds können in der Gradio-Oberfläche oder über die Befehlszeile festgelegt werden, und bei den Audio-Cues muss es sich um WAV-Dateien hoher Qualität handeln. - Unterstützt Dia den CPU-Betrieb?
Dia ist derzeit für die Ausführung auf GPUs optimiert, die Unterstützung für CPUs ist für die Zukunft geplant, und NVIDIA-GPUs werden für die beste Leistung empfohlen. - Wie lange dauert es, Audio zu erzeugen?
Die Generierungszeit hängt von der Hardware und der Länge des Skripts ab. Auf leistungsstarken GPUs dauert die Generierung kurzer Dialoge in der Regel einige Sekunden, während lange Dialoge mehrere Dutzend Sekunden dauern können. - Ist Dia frei?
Dia ist ein Open-Source-Projekt und der Code und die Modelle sind kostenlos. Die Kosten für die Hardware, die für den Betrieb benötigt wird, sind von den Nutzern selbst zu tragen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...