DeepSeek: von den Medien ignorierte Themen
Gastbeiträge von Lennart Heim und Sihao Huang. Dieser Artikel ist ein Cross-Posting von Lennarts Blog, der regelmäßig für ChinaTalk schreibt und kürzlich an einer Diskussion über Geopolitik im Zeitalter des Time-Tested Computing teilgenommen hat, und von Sihao, der bereits über Pekings Vision einer globalen KI-Governance geschrieben hat.
Jüngste Berichte über DeepSeek Berichte über KI-Modelle haben sich weitgehend auf ihre überlegene Leistung beim Benchmarking und ihre Effizienzgewinne konzentriert. Diese Erfolge sind zwar anerkennenswert und haben politische Auswirkungen (siehe unten), doch die Realität des Zugangs zu Computerressourcen, der Exportkontrollen und der KI-Entwicklung ist komplexer als in vielen Berichten dargestellt. Hier sind einige wichtige Punkte von Interesse:
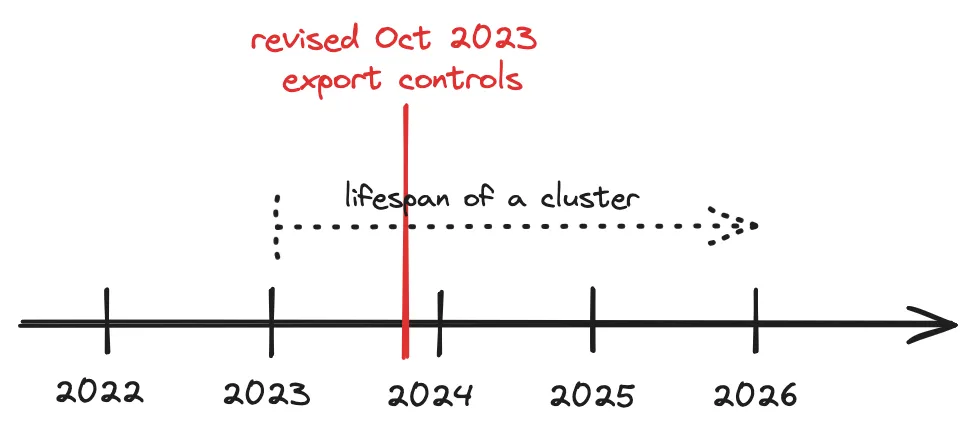
- Die tatsächlichen Ausfuhrbeschränkungen für KI-Chips beginnen im Oktober 2023, und die derzeitigen Behauptungen über ihre Unwirksamkeit sind verfrüht. DeepSeek arbeitet mit dem Nvidia H800, einem Chip, der entwickelt wurde, um das ursprüngliche Limit vom Oktober 2022 zu umgehen. Für die Berechnungsaufgaben von DeepSeek ist die Leistung dieser Chips mit dem in den USA erhältlichen H100 vergleichbar. Der neueste H20 von Nvidia - ein KI-Chip, der noch nach China exportiert werden kann - ist schwächer beim Training, aber immer noch leistungsstark beim Einsatz.
Trotz seiner Einschränkungen beim Training bleibt H20 uneingeschränkt und robust in modernen KI-Einsätzen, insbesondere bei speicherintensiven Aufgaben wie langen kontextbezogenen Schlussfolgerungen. Dies ist von entscheidender Bedeutung, insbesondere bei Trends wie Compute-on-Test, synthetischer Datengenerierung und Reinforcement Learning, die mehr auf Speicher als auf Rechenleistung angewiesen sind. Da im Dezember 2024 Beschränkungen für Exporte von High Bandwidth Memory (HBM) in Kraft treten, wird es interessant sein zu sehen, wie H20 weiterhin verfügbar sein wird, insbesondere im Zusammenhang mit der KI-Rechnernachfrage, die sich zunehmend auf die Bereitstellungsseite verlagert. - Hardware-Ausfuhrkontrollen wirken zeitverzögert und sind noch nicht voll wirksam.
All dies setzt voraus, dass die Ausfuhrkontrollen perfekt durchgesetzt werden, was nicht der Fall ist. Die Halbleiterkontrollen haben eine Vielzahl von Schlupflöchern, und es gibt glaubwürdige Beweise für den Transfer von Chips in großem Umfang. Auch wenn der Diffusionsrahmen dazu beitragen kann, einige dieser Schlupflöcher zu schließen, bleibt die Durchsetzung die größte Herausforderung. [JS: Natürlich gibt es nach wie vor Zugangsprobleme in der westlichen Cloud ......China nutzt immer noch Datenzentren, die vor den Exportbeschränkungen gebaut wurden und Zehntausende von Chips enthalten, während US-Unternehmen Datenzentren mit Hunderttausenden von Chips bauen. Die wirkliche Bewährungsprobe wird kommen, wenn diese Datenzentren aufgerüstet oder erweitert werden müssen - ein Prozess, der für US-Firmen einfacher ist, für chinesische Firmen, die Exportkontrollen unterliegen, aber eine Herausforderung darstellen wird. Wenn 100.000 Chips benötigt werden, um die nächste Generation von Modellen zu trainieren, werden die Exportkontrollen einen erheblichen Einfluss auf die Entwicklung von Spitzenmodellen in China haben. Aber auch ohne solche umfangreichen Trainingsanforderungen werden Exportkontrollen tiefgreifende Auswirkungen auf Chinas KI-Ökosystem haben, indem sie die Einsatzkapazitäten reduzieren, die Unternehmensentwicklung einschränken und die Fähigkeit zur Synthese von Trainingsdaten und zum Selbstspiel behindern.
- Es ist keine Überraschung, dass DeepSeek V3 sein Training mit weniger Rechenressourcen absolviert; die Kosten für Algorithmen des maschinellen Lernens sind im Laufe der Zeit gesunken. Aber die gleichen Effizienzgewinne, die es kleinen Unternehmen wie DeepSeek ermöglichen, auf KI-Funktionen zuzugreifen (d. h. "Erreichbarkeitseffekt") und kann es auch anderen Unternehmen ermöglichen, leistungsfähigere Systeme auf größeren Computerclustern aufzubauen (d. h., "Leistungseffekt"). Glücklicherweise trainierte DeepSeek V3 mit nur 2.000 H800 anstelle von 200.000 B200 (Nvidias neueste Chipgeneration).

- Der Zeitpunkt der Veröffentlichung hat strategische Gründe, aber die technischen Fähigkeiten sind echt. Die Veröffentlichung des R1 fällt mit der Amtseinführung von Präsident Trump in der vergangenen Woche zusammen und zielt eindeutig darauf ab, das Vertrauen der Öffentlichkeit in Amerikas KI-Führung zu einem für die US-Politik kritischen Zeitpunkt zu untergraben. Es ist die gleiche Strategie, mit der Huawei sein neues Produkt während des Besuchs der ehemaligen Handelsministerin Raimondo in China vorstellte. Immerhin wurden die Benchmark-Ergebnisse des R1 Preview bereits im November veröffentlicht.
Dieses sorgfältige PR-Timing sollte nicht über zwei Tatsachen hinwegtäuschen: die technologischen Fortschritte von DeepSeek und die derzeitigen und künftigen strukturellen Herausforderungen aufgrund von Exportkontrollen. - Exportkontrollen lassen sich nur schwer auf eine einzelne Trainingsaufgabe anwenden, aber sie können die Entwicklung eines ganzen KI-Ökosystems wirksam einschränken. Insbesondere Beschränkungen für Chips, die dem neuesten Stand der Technik entsprechen, können den Einsatz von KI in großem Maßstab (d. h. die Bereitstellung von KI-Diensten für eine große Zahl von Nutzern) und die Verbesserung von Fähigkeiten wirksam einschränken. KI-Unternehmen verwenden in der Regel 60-80% der Rechenressourcen für die Bereitstellung - und das schon vor dem Aufkommen rechenintensiver Argumentationsmodelle. Eine Begrenzung der Rechenressourcen erhöht die Kosten für chinesische KI, mindert die Fähigkeit, sie in großem Umfang einzusetzen, und schränkt die Systemleistung ein. Es ist erwähnenswert, dass es bei der Bereitstellung von Rechenleistung nicht nur um den Zugang der Nutzer geht; sie spielt auch eine Schlüsselrolle bei der Generierung synthetischer Trainingsdaten, bei der Verbesserung der Fähigkeiten durch Modellinteraktionen und bei der Erstellung, Skalierung und Optimierung von Modellen.
So weist Gwern in seinen jüngsten Kommentaren darauf hin, dass das Deployment Computing bei der KI-Entwicklung eine Schlüsselrolle spielt, die weit über den Nutzerzugang hinausgeht. Modelle wie das o1 von OpenAI können zur Generierung hochwertiger Trainingsdaten verwendet werden, wodurch eine Rückkopplungsschleife entsteht, bei der die Einsatzmöglichkeiten direkt die Entwicklungsmöglichkeiten und die Gesamtleistung verbessern. - Die Effizienzgewinne von DeepSeek sind möglicherweise auf die massive arithmetische Unterstützung zurückzuführen, die es zuvor erhielt. Auf den ersten Blick scheint der Weg zur Verringerung des Chipverbrauchs (d. h. zur "Effizienzsteigerung") mit viel Rechenleistung zu beginnen. deepSeek betreibt Asiens ersten A100-Cluster mit 10.000 Chips und unterhält Berichten zufolge einen H800-Cluster mit 50.000 Chips sowie unbegrenzten Zugang zu (exportkontrollierten) Cloud-Dienstleistern in China und im Ausland. Cloud-Service-Anbieter in China und im Ausland (die nicht der Exportkontrolle unterliegen). Dieser umfassende Zugang zu Rechenleistung ist für die Entwicklung effizienter Technologien durch iterative Tests und für die Bereitstellung von Modellierungsdiensten für seine Kunden von entscheidender Bedeutung.
In jüngster Zeit haben andere KI-Unternehmen Nutzungsspitzen erlebt, die zu Serviceausfällen geführt haben, selbst wenn sie durch eine höhere Rechenleistung unterstützt wurden. Ob DeepSeek ähnliche Spitzen bewältigen kann, ist noch nicht getestet worden, und sie werden mit einer begrenzten Rechenleistung zu kämpfen haben. (Sam Altman behauptet sogar, dass ChatGPT Die Pro-Abonnements machen derzeit Verluste).
Ihr R1-Modell war zwar sehr effizient, aber sein Entwicklungsprozess war mit einem hohen Anteil an arithmetischen Berechnungen für die Generierung synthetischer Daten, die Destillation und das Experimentieren verbunden. - Die Exportkontrollen haben die rechnerische Kluft zwischen den USA und China weiter vergrößert, was für DeepSeek eine große Einschränkung darstellt. Die Unternehmensleitung hat öffentlich eingeräumt, dass sie trotz verbesserter Effizienz immer noch einen rechnerischen Nachteil von viermal hat. Das bedeutet, dass wir die doppelte Rechenleistung benötigen, um die gleichen Ergebnisse zu erzielen", so Wenfeng Liang, Gründer von DeepSeek. Auch bei der Dateneffizienz klafft eine Lücke von etwa dem Zweifachen, was bedeutet, dass wir die doppelte Menge an Trainingsdaten und Rechenleistung benötigen, um vergleichbare Ergebnisse zu erzielen. Zusammengenommen erfordert dies die 4-fache Rechenleistung". Er fügte hinzu: "Wir haben auf kurze Sicht keine Finanzierungspläne. Unser Problem war nie die Finanzierung, sondern das Embargo für High-End-Chips."
- Führende KI-Unternehmen in den USA halten ihre stärksten Fähigkeiten unter Verschluss, was bedeutet, dass öffentliche Benchmarkings nicht das gesamte Bild der KI-Entwicklung widerspiegeln. Chinesische Unternehmen neigen dazu, Fortschritte öffentlich zu machen, während Anthropisch und OpenAI, um nur einige zu nennen, behalten einen großen Teil ihrer Fähigkeiten für sich. Daher sind direkte Vergleiche auf der Grundlage öffentlich zugänglicher Informationen unvollständig. DeepSeek hat zum Teil wegen seiner Offenheit Aufmerksamkeit erregt - im Gegensatz zum Trend westlicher Unternehmen, sich zunehmend abzuschotten, teilen sie Modellgewichtungen und Methoden im Detail. Es bleibt jedoch abzuwarten, ob Offenheit notwendigerweise zu einem strategischen Vorteil führt.
Was bedeutet das also?
Die Erfolge von DeepSeek sind real und wichtig. Es ist unzutreffend, ihre Fortschritte einfach als Propaganda abzutun. Die von DeepSeek angegebenen Trainingskosten sind nicht beispiellos, und historische Trends bei der Effizienz von Algorithmen belegen dies. Allerdings müssen Vergleiche sorgfältig im Kontext betrachtet werden - DeepSeek berichtet nur über die endgültigen Kosten vor dem Trainingslauf und ignoriert wichtige Ausgaben wie Personalkosten, Vorversuche, Datenerfassung und Infrastrukturentwicklung. Weitere Informationen über die irreführenden Vergleiche, die sich aus unterschiedlichen Kostenberechnungsmethoden ergeben können, finden Sie in diesem Artikel.
Die zunehmende Rechenleistung bedeutet, dass sich die KI-Fähigkeiten schließlich ausbreiten werden. Kontrollen allein reichen nicht aus. Es sind ergänzende Maßnahmen erforderlich, um die Widerstandsfähigkeit und die Abwehrkräfte der Gesellschaft zu stärken, um Institutionen aufzubauen, die in der Lage sind, KI-Risiken zu erkennen, zu bewerten und darauf zu reagieren, und um robuste Abwehrmaßnahmen gegen potenzielle KI-Bedrohungen von Seiten des Gegners zu entwickeln. Wir sollten jedoch auch anerkennen, dass Exportkontrollen bereits Auswirkungen auf Chinas KI-Entwicklung hatten und in Zukunft noch stärkere Auswirkungen haben könnten.
Modelle selbst sind vielleicht nicht das, was viele als "strategischen Graben" betrachten, aber die Auswirkungen der Rechenleistung auf die nationale Sicherheit variieren je nach Anwendungsszenario. Bei Anwendungen, die einen groß angelegten Einsatz erfordern (z. B. Massenüberwachung), können Kapazitätsbeschränkungen ein erhebliches Hindernis darstellen. Bei Anwendungen für Einzelanwender sind die Auswirkungen der Regulierung dagegen weniger bedeutend. Die Beziehung zwischen der rechnerischen Verfügbarkeit und den nationalen Sicherheitsfähigkeiten ist nach wie vor komplex, auch wenn die modellierten Fähigkeiten selbst immer leichter zu reproduzieren sind.
Auch wenn sich KI-Fähigkeiten trotz Kontrollen weiter verbreiten und es immer schwierig sein wird, die Verbreitung ganz zu stoppen, bleiben diese Kontrollen entscheidend für die Aufrechterhaltung des technologischen Vorsprungs. Kontrollen verschaffen wertvolle Zeit, aber es sind immer noch ergänzende Maßnahmen erforderlich, um sicherzustellen, dass Demokratien der Entwicklung voraus sind und in der Lage sind, Herausforderungen durch potenzielle Rivalen abzuwehren.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel



Keine Kommentare...